Interoperability(互操作性)¶
Palantir AIP and Foundry are designed to interoperate with the full range of data, logic, AI, workflow, and security systems.
This includes tools and technologies that span traditional data, analytics, governance, and operational domains—including edge devices and rugged environments.
Removing traditional tradeoffs often found with integrated platforms, the goal of the Palantir architecture is to provide a coherent and complete experience while enabling the modularity required to deeply connect with existing (or future) enterprise software platforms.
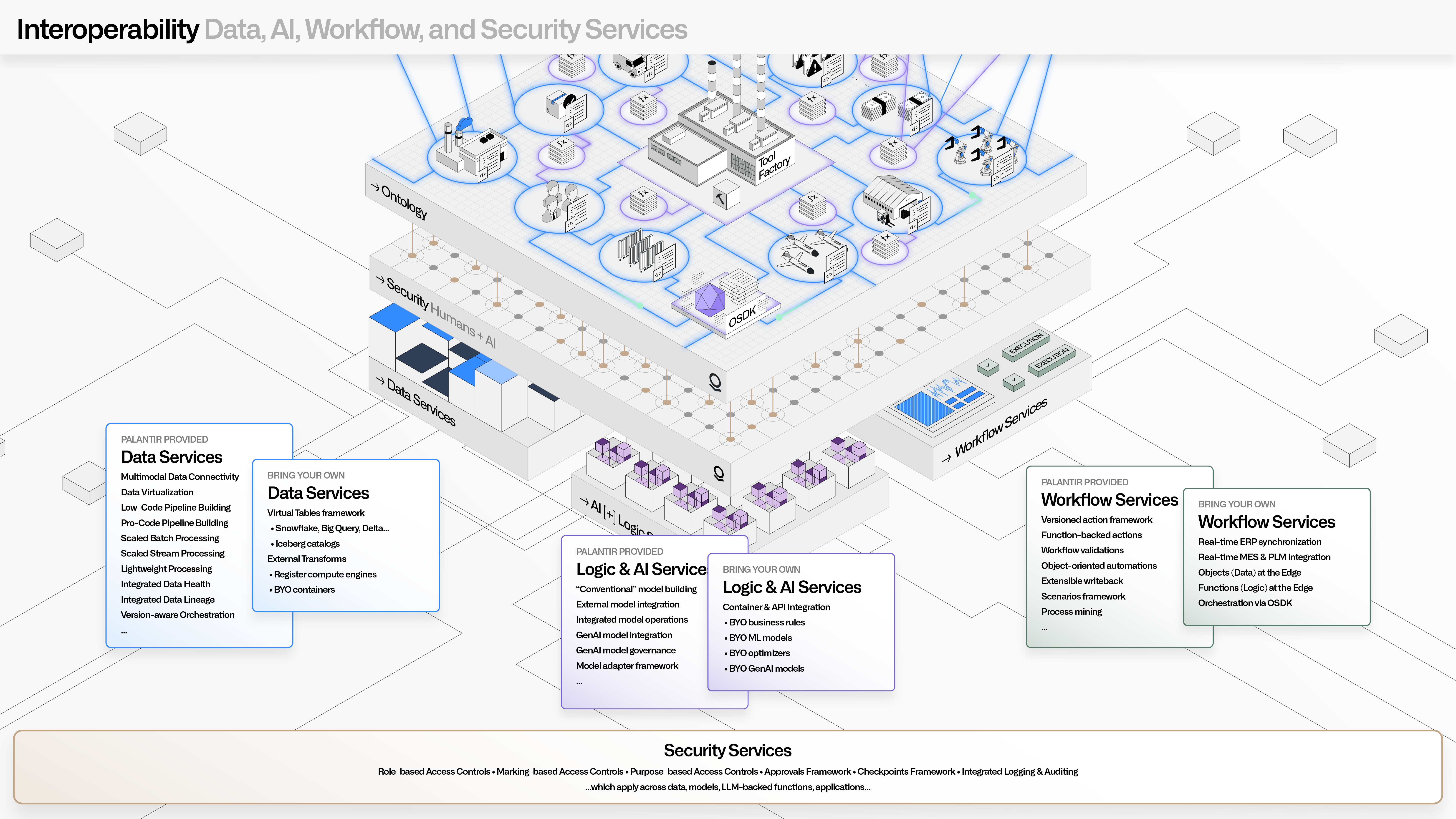
Data interoperability¶
The Palantir platforms are built on top of open data standards. All data is stored in its original format (such as CSV, Iceberg, or Parquet), and is accessible through standard interfaces, such as REST, JDBC, and S3-compatible access. Additionally, all transformed data is, by default, accessible in open formats, such as Apache Iceberg and Apache Parquet. This allows for deep connectivity with existing data platforms, systems of record, and other services within enterprise data architectures.
Beyond native capabilities, the Multimodal Data Plane (MMDP) enables unprecedented integration with existing enterprise assets. This includes the Virtual Tables framework for leveraging existing data assets within common data platforms (such as Databricks, Snowflake, or BigQuery) without needless data duplication. MMDP also includes fully orchestrated pushdown compute, so that applications like Pipeline Builder can be seamlessly used with existing compute investments.
Learn more about data interoperability:
- Explore the philosophy behind the Multimodal Data Plane.
- Review the expanding list of out-of-the-box Data Connection Source types.
- Learn about building custom data connections.
- View the options for avoiding data duplication with Virtual Tables.
- Learn about generating data pipelines out-of-the-box with Palantir HyperAuto.
Metadata interoperability¶
Palantir Foundry and AIP provide rich metadata integration capabilities for the vast range of mandatory metadata (such as security, attribution, or lineage) and discretionary metadata (such as tags or enrichments). Metadata services securely expose all metadata attributes that exist across projects, datasets, ontology elements, agents, models, analyses, applications, pipeline orchestrations, resource health, and much more. This allows for deep connectivity with existing data catalogs, metadata management tools, master data management tools, and other services within existing governance architectures.
Learn more about the various types of metadata:
- Learn about dataset metadata (and all of the metadata accessible via the Platform SDK ↗).
- Explore the Developer Libraries & API reference.
- Learn about Ontology metadata (and the Ontology SDK).
Semantic interoperability¶
The Palantir Ontology pushes beyond traditional semantic definitions, and includes granular definitions for the objects, links, actions, and functions that drive complex operations, agents, and AI-driven automations. All elements in an organization’s Ontology can be accessed through REST APIs and configured through JSON-driven authoring paradigms. This allows for bidirectional synchronization with existing semantic modeling tools, ontologies resident within data catalogs, and domain-specific modeling tools.
Learn more about creating and integrating with the Ontology:
- Review the Ontology SDK to learn how you can build applications and workflows on top of the Ontology.
- Learn about using Webhooks to integrate with existing operational systems.
- Explore Palantir MCP, which enables agent-driven semantic interoperability.
Code & logic interoperability¶
Palantir's commitment to open software standards applies across data engineering, data science, and all other code-driven authoring paradigms. All data transformation, by default, uses open languages (like Python, Java, or SparkSQL) that have bindings for the open runtimes (such as Spark, Flink, DataFusion, or Polars) that are bundled with the platform. Also, all data science workflows leverage open languages (like Python or R) that leverage the same open runtimes, and are designed to leverage common open formats (such as ONNX). Code Repositories are stored within a highly available Git service, and can be securely accessed both through UI-driven exports, and API (programmatic) interactions.
Beyond packaged compute runtimes and associated languages, the Compute Modules framework enables teams to bring their own containerized runtimes, applications, models, and executables of all kinds. These containers are securely orchestrated and managed by Palantir’s underlying compute infrastructure (Rubix), and can be robustly surfaced throughout the full range of data pipelining, application building, analytical, and AI-driven workflows.
Learn more about interfacing with code and logic:
- View the out-of-the-box languages supported for data transformation.
- View the languages supported for data science workflows.
- Explore the full range of model integration options.
- Learn about the Code Repositories environment.
- Learn how to “Bring Your Own Containers” with Compute Modules.
Analytical interoperability¶
Palantir Foundry and AIP provide a full range of analytical tools to empower users, and can also seamlessly interoperate with existing investments such as BI and data science tools. Out-of-the-box connectors are available for common systems such as Power BI®, Tableau, Jupyter, and RStudio®. These connectors enable a broad range of users to tap into integrated data, while taking advantage of best-in-class data management, model management, and governance.
In addition to data connectors, Code Workspaces provides a seamless experience working natively in Jupyter® and RStudio® inside the platform.
Learn about analytics connectors:
- Learn about how SQL & BI Connectors enable integration with existing BI investments.
- Get started working directly in Jupyter® or RStudio® with Code Workspaces
- Refer to the Platform SDK ↗ and R SDK ↗ on GitHub for integration with data science tools.
Security interoperability¶
The platform provides robust, transparent controls across all resources in the platform. Security services are designed to leverage existing authentication systems (for example, via SAML) for identity, and existing authorization systems (like Active Directory) for permissions that can span role-based, classification-based, and purpose-based regimes. Through the Ontology SDK, permissions can be extended and managed flexibly for third-party and custom application development. Dynamic and retrospective access to all security information is possible through the platform’s REST APIs.
Learn more about interfacing with Palantir security services:
- Learn about setting up SAML integration for authentication.
- Learn how Palantir can enable cross-organization collaboration.
- Learn about permissions in the Ontology SDK.
中文翻译¶
互操作性¶
Palantir AIP 与 Foundry 旨在与各类数据、逻辑、AI、工作流及安全系统实现全面互操作。
这涵盖了横跨传统数据、分析、治理和运营领域的技术与工具——包括边缘设备和严苛环境。
Palantir 架构的目标是消除集成平台常见的传统权衡,在提供连贯完整体验的同时,实现与现有(或未来)企业软件平台深度连接所需的模块化能力。
数据互操作性¶
Palantir 平台构建于开放数据标准之上。所有数据均以其原始格式(如 CSV、Iceberg 或 Parquet)存储,并通过标准接口(如 REST、JDBC 和兼容 S3 的访问方式)进行访问。此外,所有经过转换的数据默认以开放格式(如 Apache Iceberg 和 Apache Parquet)提供访问。这使得平台能够与现有数据平台、记录系统以及企业数据架构中的其他服务实现深度连接。
除原生能力外,多模态数据平面(Multimodal Data Plane, MMDP)还能实现与现有企业资产的空前集成。这包括虚拟表(Virtual Tables)框架,可在无需不必要数据复制的情况下,利用常见数据平台(如 Databricks、Snowflake 或 BigQuery)中的现有数据资产。MMDP 还包含完全编排的下推计算功能,使 Pipeline Builder 等应用能够与现有计算投资无缝配合使用。
了解更多关于数据互操作性的信息:
- 探索多模态数据平面背后的理念。
- 查看不断扩展的开箱即用数据连接(Data Connection)源类型列表。
- 了解如何构建自定义数据连接。
- 查看通过虚拟表避免数据复制的选项。
- 了解如何使用 Palantir HyperAuto 开箱即用地生成数据管道。
元数据互操作性¶
Palantir Foundry 和 AIP 为广泛的强制性元数据(如安全性、归属或血缘)和自由性元数据(如标签或增强信息)提供丰富的元数据集成能力。元数据服务安全地公开跨项目、数据集、本体论(Ontology)元素、代理(Agent)、模型、分析、应用、管道编排、资源健康状态等所有元数据属性。这使得平台能够与现有数据目录、元数据管理工具、主数据管理工具以及现有治理架构中的其他服务实现深度连接。
了解更多关于各类元数据的信息:
- 了解数据集元数据(以及通过 Platform SDK ↗ 可访问的所有元数据)。
- 探索开发者库与 API 参考。
- 了解本体论元数据(以及本体论 SDK)。
语义互操作性¶
Palantir 本体论超越了传统语义定义,包含驱动复杂操作、代理和 AI 驱动自动化的对象、链接、操作和函数的精细定义。组织本体论中的所有元素均可通过 REST API 访问,并通过 JSON 驱动的编写范式进行配置。这使得平台能够与现有语义建模工具、数据目录中的本体论以及领域特定建模工具实现双向同步。
了解更多关于创建和集成本体论的信息:
- 查看本体论 SDK,了解如何在本体论之上构建应用和工作流。
- 了解如何使用 Webhooks 与现有运营系统集成。
- 探索 Palantir MCP,该功能支持代理驱动的语义互操作性。
代码与逻辑互操作性¶
Palantir 对开放软件标准的承诺适用于数据工程、数据科学以及所有其他代码驱动的编写范式。所有数据转换默认使用开放语言(如 Python、Java 或 SparkSQL),这些语言与平台捆绑的开放运行时(如 Spark、Flink、DataFusion 或 Polars)具有绑定关系。此外,所有数据科学工作流均利用开放语言(如 Python 或 R),这些语言使用相同的开放运行时,并设计为利用常见开放格式(如 ONNX)。代码仓库(Code Repositories)存储在高可用的 Git 服务中,可通过 UI 驱动的导出和 API(编程)交互安全访问。
除打包的计算运行时和相关语言外,计算模块(Compute Modules)框架使团队能够自带各类容器化运行时、应用、模型和可执行文件。这些容器由 Palantir 底层计算基础设施(Rubix)安全编排和管理,并可稳健地呈现在数据管道构建、应用开发、分析和 AI 驱动工作流的全范围内。
了解更多关于代码与逻辑接口的信息:
分析互操作性¶
Palantir Foundry 和 AIP 提供全面的分析工具以赋能用户,同时也能与现有投资(如 BI 和数据科学工具)无缝互操作。平台提供针对常见系统(如 Power BI®、Tableau、Jupyter 和 RStudio®)的开箱即用连接器。这些连接器使广泛用户能够利用集成数据,同时享受一流的数据管理、模型管理和治理能力。
除数据连接器外,代码工作区(Code Workspaces)还提供在平台内原生使用 Jupyter® 和 RStudio® 的无缝体验。
了解分析连接器:
- 了解 SQL 与 BI 连接器如何实现与现有 BI 投资的集成。
- 开始使用代码工作区,直接在 Jupyter® 或 RStudio® 中工作。
- 参考 GitHub 上的 Platform SDK ↗ 和 R SDK ↗,实现与数据科学工具的集成。
安全互操作性¶
该平台为平台内所有资源提供稳健、透明的控制。安全服务设计为利用现有身份验证系统(例如通过 SAML)进行身份识别,并利用现有授权系统(如 Active Directory)管理权限,这些权限可涵盖基于角色、基于分类和基于用途的机制。通过本体论 SDK,权限可灵活扩展和管理,以支持第三方和自定义应用开发。通过平台的 REST API,可动态和追溯地访问所有安全信息。
了解更多关于 Palantir 安全服务接口的信息: