Multimodal Data Plane (MMDP)(多模态数据平面 (MMDP))¶
The Multimodal Data Plane (MMDP) is Palantir’s open data and compute architecture. MMDP reflects the learnings of two decades of forging battle-tested solutions on the frontline of customer missions, and wrestling with the design tradeoffs that often create tension between analytical and operational system designs.
Concretely, most platform architectures are built around particular compute runtimes or data storage modalities. While this can function for narrow use cases, these dependencies can quickly become a hindrance when scaling to interconnected use cases which require complex interplays of, for example, structured, unstructured, time series, geospatial, or geometric data, which must each be transformed and manipulated through different forms of compute, before being holistically made available in seamless end user experiences.
In the age of AI, moving beyond fragmented data and compute is no longer just a “nice to have”, but essential to unlocking enterprise autonomy.

Any data: MMDP's open data architecture¶
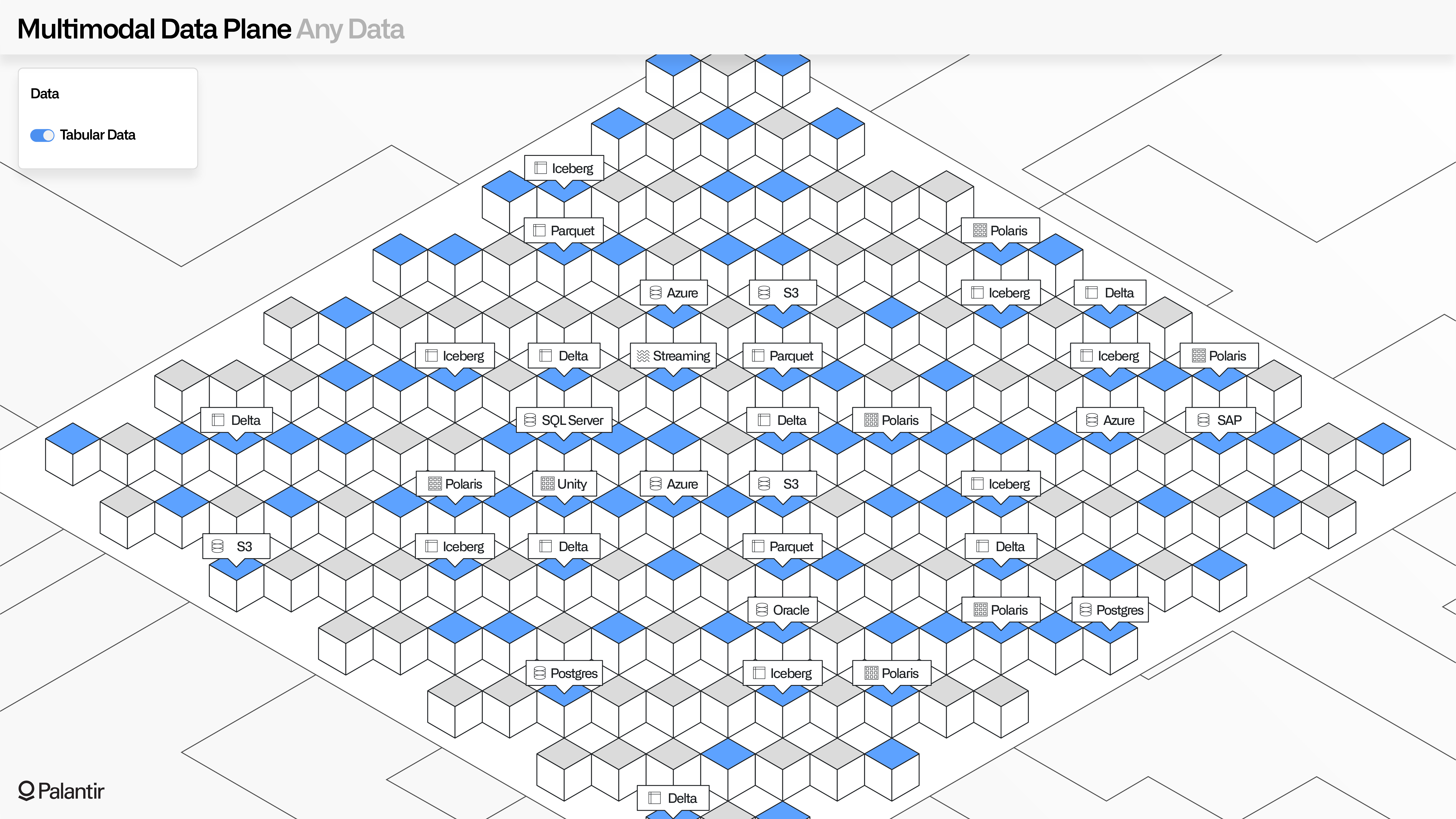
The bedrock of MMDP is an open data architecture. This starts with a commitment to Apache Iceberg as the primary table format for Foundry and AIP.
Iceberg is being embraced as an open standard across key Palantir partners, including AWS, Google Cloud, Microsoft Azure, Databricks, and Snowflake.
MMDP allows Iceberg catalogs to be managed within Palantir, or as virtual catalogs and virtual tables that are registered from these (or other) providers. This means that leveraging data in the Ontology for operational applications and AI-driven automations never requires data to be duplicated.
Adopting Iceberg also means that standard tools such as SQL applications and analytical notebooks can securely interact with and manipulate data in Foundry and AIP as in any other environment.
Many organizations are building a “data mesh” (or now, an “AI mesh”) that incorporates Palantir as one participant in a wider, more heterogenous enterprise architecture. It is an explicit goal of MMDP to support these types of mixed architectures by providing an “unwalled garden” that enables end-to-end delivery of outcomes, while ensuring that every layer of the architecture can be deeply integrated with existing data lakes, lakehouses, conventional warehouses, data governance tools, and other key storage repositories.
MMDP: Openness beyond tabular data¶
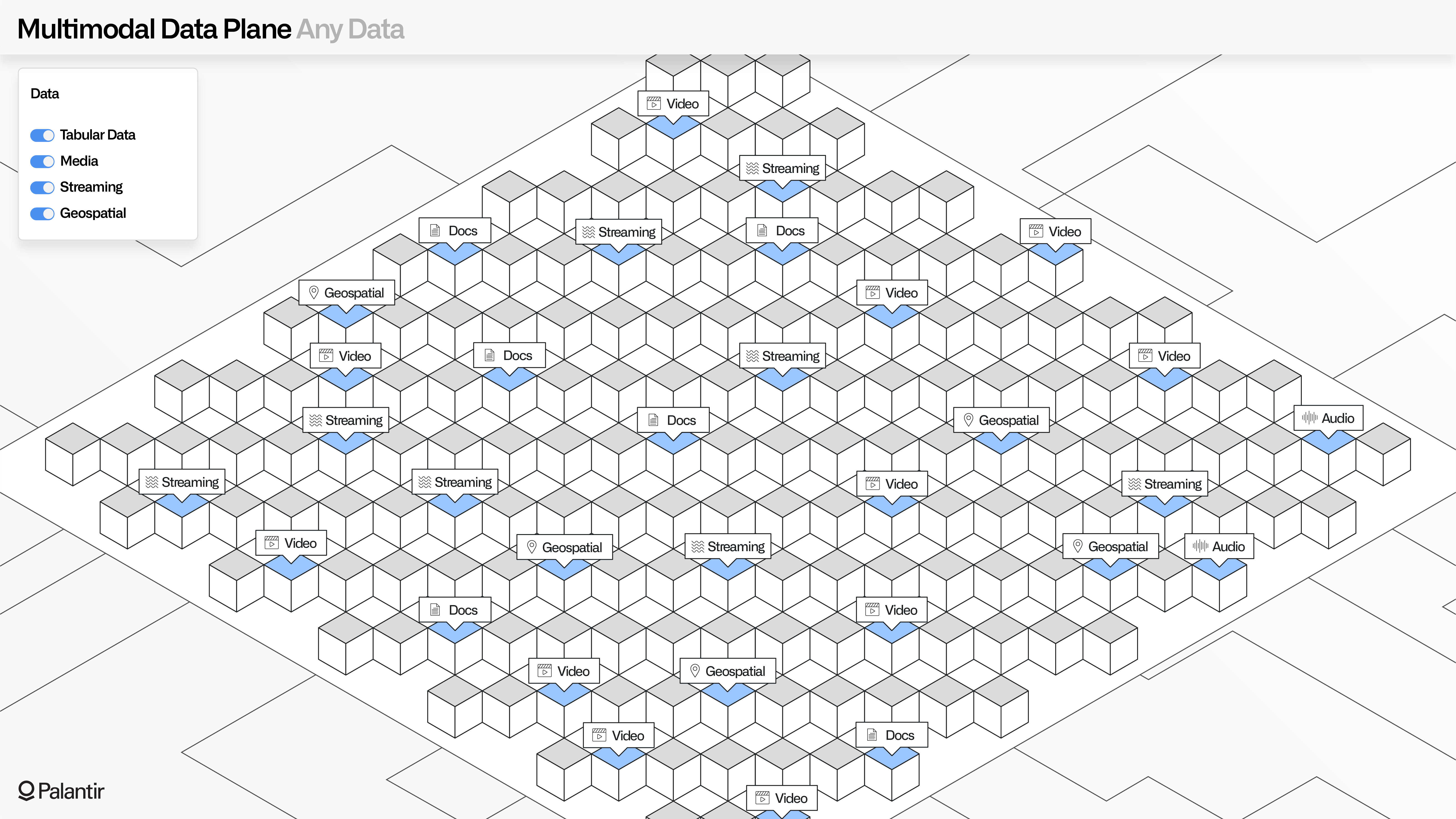
In addition to tabular data, MMDP extends the same open guarantees to media, documents, streaming data, geospatial data, and the vast expanse of multimodal data types.
Media data can be synchronized with minimal assumptions about the underlying format; where there are recognized formats, analytical tools can immediately help with interactive parsing; and where custom or niche formats are integrated, metadata can be lazily affixed from other sources.
The same is true for streaming and geo-temporal data, which might have associative metadata (e.g., sensor tags) that require processing in a data pipeline that flows parallel to the primary ingress pipeline.
Regardless of how data is ingested and transformed, all underlying files and points can be securely accessed through standard REST APIs, as well as the Python and TypeScript SDKs.
Export jobs and Ontology-based webhooks provide simple and secure methods of synchronizing any data (regardless of modality) to external systems, and the Source-based Transforms paradigm enables developers to use the full power of the Foundry toolchain to customize data egress as needed, at the granularity of individual workflow steps.
Any compute: MMDP's open compute architecture¶
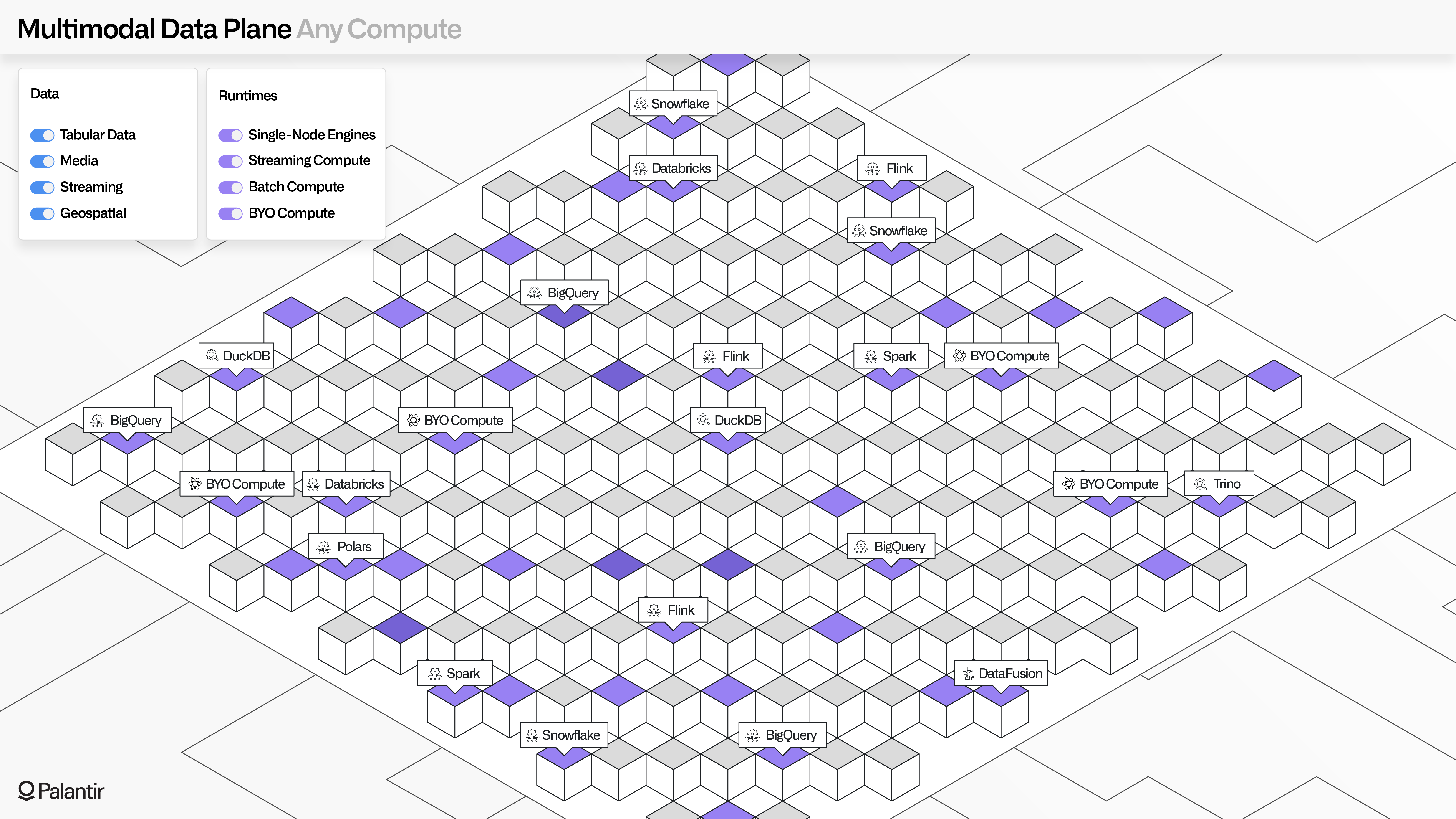
MMDP’s open compute architecture unlocks the value of the open data architecture. Foundry and AIP come with an array of out-of-the-box runtimes, which all use a hardened, autoscaling Kubernetes-based compute mesh (Palantir Rubix).
Rubix operates on zero-trust principles and enforces a rigorous security posture across every runtime and service it manages; for instance, to defend against advanced persistent threats, every container is destroyed and cycled within 72 hours. This requires the dependent compute infrastructure to be highly available, and generally resilient to the failure of single nodes.
Users across roles and functions, whether technical data engineers or analytical data scientists or operational business users, can leverage batch, streaming, and interactive compute engines within the platform (and through APIs and SDKs). This includes autoscaling Spark for batch compute; autoscaling Flink for streaming compute; and a range of open and high-performance single-node engines such as Apache DataFusion, Polars, and DuckDB.
Data transformations that are managed "South of the Ontology" (from raw data to Ontology data) as well as interactive functions that are used "North of the Ontology" (from Ontology data to end users) can leverage these runtimes and others in a resilient and governed manner.
MMDP: Build with any compute¶
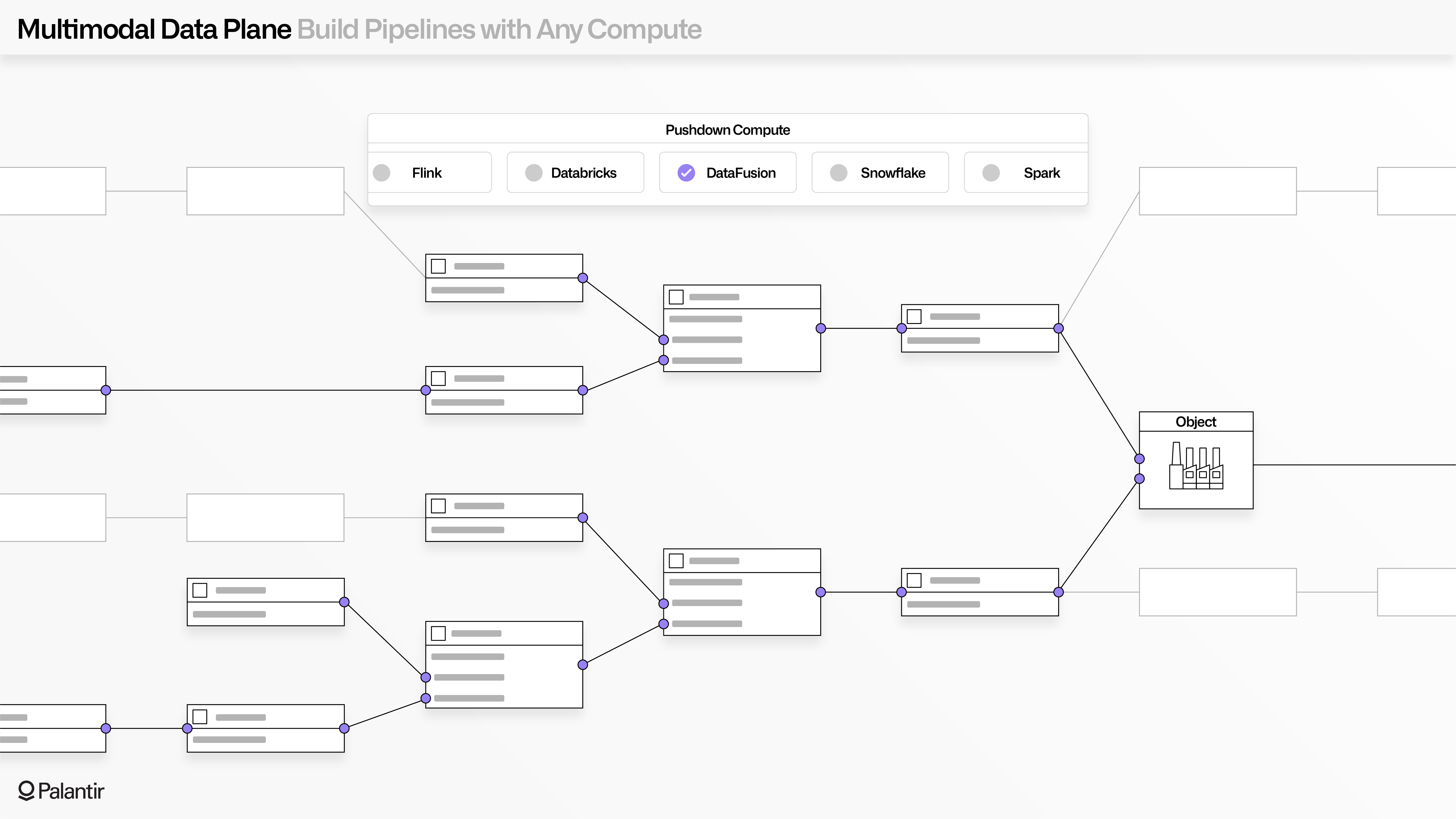
The Compute Modules framework enables "Bring your own compute" ("BYO Compute"), where any containerized resource can be imported and securely surfaced through batch, streaming, and interactive functions.
Across operational workflows, the most important executables and models are often trapped within domain-specific artifacts, or legacy packages that are no longer actively developed. Compute Modules enable these fragmented compute artifacts to be securely liberated and then hosted and used across AI-enabled workflows and alongside more modern logic artifacts (such as Python, Java, SQL, Go, or Rust programs).
Foundry and AIP can also orchestrate with compute resources that are located outside of the Palantir environment, including existing model inference infrastructure, Spark clusters, cloud-hosted optimization engines, and high-performance computing resources that run on-premises.
MMDP also enables native and seamless pushdown of compute to cloud-native runtimes (such as Databricks or Snowflake), allowing developers to use tools like Pipeline Builder and Code Workspaces with their existing compute resources.
Any model: Palantir's commitment to model access¶
Palantir’s commitment to openness and optionality extends to generative AI. MMDP's "any model" philosophy reflects the ongoing commitment to offer the latest generative AI models through AIP’s Model Catalog (including those from OpenAI, Anthropic, Google, Meta, and xAI), and providing a level playing field for enterprises to register and use their own models in equal measure.
LLMs and multimodal models, whether Palantir-provided or custom-registered, can be seamlessly used throughout Foundry and AIP applications, including Pipeline Builder, Workshop, AIP Logic, and the developer toolchain.
To assist in administration, access to models can be governed with precision, with token limits can be set across all use-cases and lines of effort. Meanwhile, resource management capabilities extend cohesively across all data, compute, and AI models connected through MMDP, regardless of the specific underlying modality, runtime, or format.
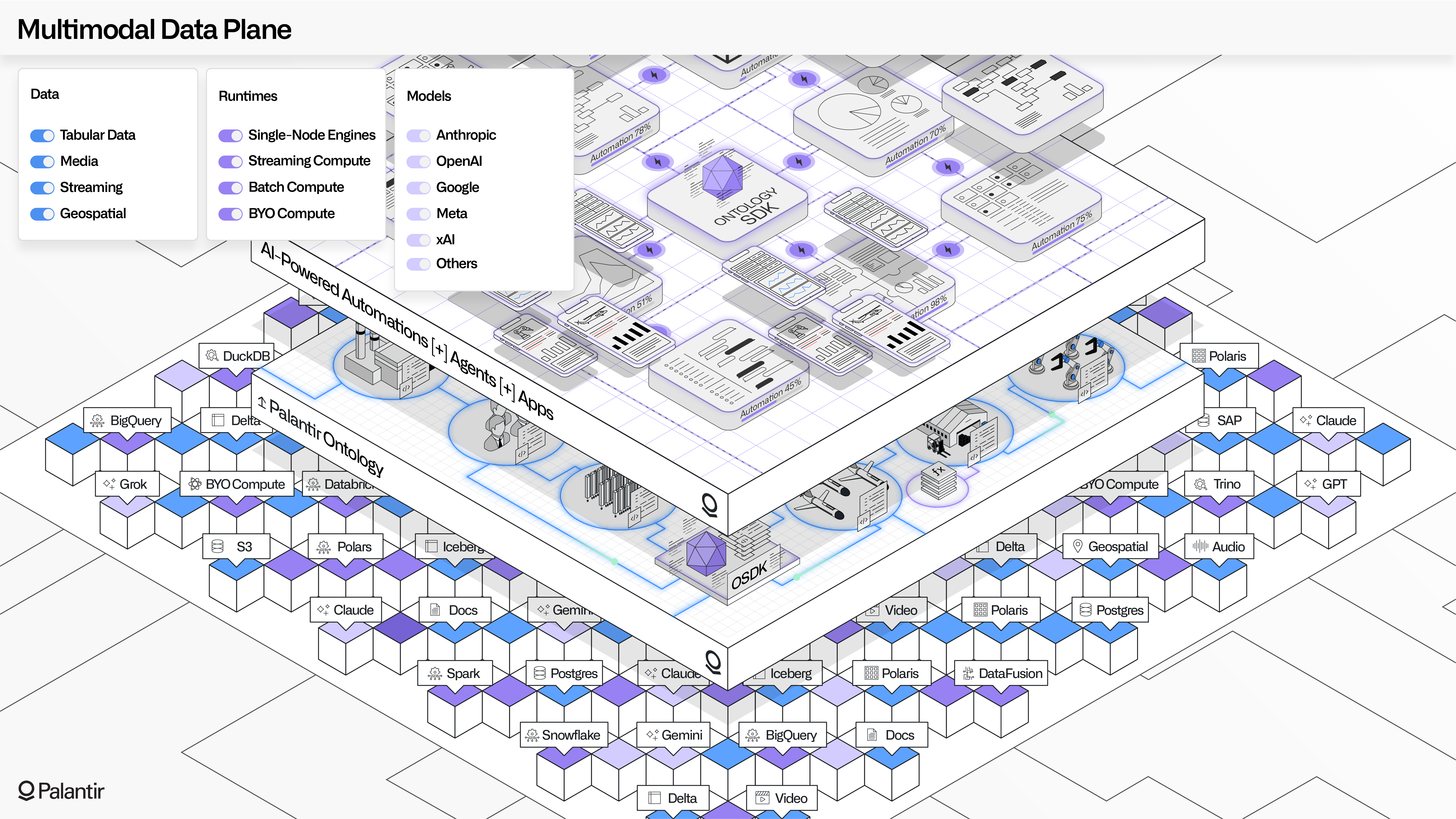
Anywhere: MMDP's commitment to openness¶
MMDP bridges the analytical and operational worlds by resisting the easy answers provided by monolithic storage and compute architectures.
The open data architecture leverages open standards like Apache Iceberg, while providing parity for media, documents, streams, and multimodal data types.
The open compute architecture bundles in common runtimes, allows teams to bring their own compute resources, and provides rich interfaces for orchestrating with existing compute infrastructure throughout the enterprise.
This openness extends to generative AI, with a wide variety of LLMs available through the Model Catalog and the ability to easy register custom, fine-tuned, and existing enterprise models.
And with Palantir Apollo, all of this flexibility, along all of these dimensions, is agnostic to the underlying infrastructure provider and continuously evolving in response to the most demanding requirements seen on the frontlines.
MMDP's philosophy: "Any data, any compute, any model, anywhere."
中文翻译¶
多模态数据平面 (MMDP)¶
多模态数据平面 (Multimodal Data Plane, MMDP) 是 Palantir 的开放数据与计算架构。MMDP 凝聚了二十年来在客户任务前线打造经过实战检验的解决方案,以及权衡分析型与操作型系统设计之间常见矛盾的经验。
具体而言,大多数平台架构都围绕特定的计算运行时或数据存储模式构建。虽然这适用于狭窄的用例,但当扩展到需要结构化、非结构化、时序、地理空间或几何数据等复杂交互的互联用例时,这些依赖关系很快就会成为障碍——这些数据必须通过不同形式的计算进行转换和处理,然后才能整体性地呈现在无缝的最终用户体验中。
在人工智能时代,超越碎片化的数据和计算已不再是"锦上添花",而是实现企业自主化的关键。
任意数据:MMDP 的开放数据架构¶
MMDP 的基石是开放数据架构。这首先体现在将 Apache Iceberg 作为 Foundry 和 AIP 的主要表格式。
Iceberg 正被 Palantir 的主要合作伙伴(包括 AWS、Google Cloud、Microsoft Azure、Databricks 和 Snowflake)作为开放标准广泛采用。
MMDP 允许在 Palantir 内部管理 Iceberg 目录,或者将这些(或其他)提供商注册的虚拟目录和虚拟表作为外部目录管理。这意味着,为操作型应用和 AI 驱动的自动化而利用本体论 (Ontology) 中的数据时,永远无需复制数据。
采用 Iceberg 还意味着,SQL 应用和分析型笔记本等标准工具可以像在任何其他环境中一样,安全地与 Foundry 和 AIP 中的数据进行交互和操作。
许多组织正在构建一个"数据网格"(或现在的"AI 网格"),将 Palantir 作为更广泛、更多元的企业架构中的一员。MMDP 的一个明确目标就是支持这类混合架构,通过提供一个"无围墙花园"来实现端到端的成果交付,同时确保架构的每一层都能与现有数据湖、湖仓一体、传统数据仓库、数据治理工具及其他关键存储库深度集成。
MMDP:超越表格数据的开放性¶
除表格数据外,MMDP 还将同样的开放保障扩展到媒体、文档、流式数据、地理空间数据以及广阔的多模态数据类型。
媒体数据可以在对底层格式做最少假设的情况下进行同步;对于已识别的格式,分析工具可以立即进行交互式解析;对于集成的自定义或小众格式,可以从其他来源惰性地附加元数据。
流式数据和地理时空数据也是如此,它们可能具有关联元数据(例如传感器标签),需要在与主要入口管道并行的数据管道中进行处理。
无论数据如何摄取和转换,所有底层文件和点都可以通过标准 REST API 以及 Python 和 TypeScript SDK 安全访问。
导出作业和基于本体论的 Webhook 提供了简单安全的方法,可将任何数据(无论何种模态)同步到外部系统,而基于源的转换 (Source-based Transforms) 范式使开发人员能够利用 Foundry 工具链的全部功能,在单个工作流步骤的粒度上按需自定义数据出口。
任意计算:MMDP 的开放计算架构¶
MMDP 的开放计算架构释放了开放数据架构的价值。Foundry 和 AIP 附带一系列开箱即用的运行时,这些运行时均使用经过加固、自动扩展的基于 Kubernetes 的计算网格 (Palantir Rubix)。
Rubix 基于零信任原则运行,并在其管理的每个运行时和服务上强制执行严格的安全态势;例如,为防御高级持续性威胁,每个容器在 72 小时内被销毁并轮换。这要求依赖的计算基础设施具有高可用性,并且通常能够抵御单节点故障。
跨角色和职能的用户——无论是技术数据工程师、分析型数据科学家还是操作型业务用户——都可以利用平台内的批处理、流式和交互式计算引擎(以及通过 API 和 SDK)。这包括用于批处理计算的自动扩展 Spark;用于流式计算的自动扩展 Flink;以及一系列开放的高性能单节点引擎,如 Apache DataFusion、Polars 和 DuckDB。
在本体论"南向"管理的数据转换(从原始数据到本体论数据)以及在本体论"北向"使用的交互式函数(从本体论数据到最终用户)都可以以弹性且受治理的方式利用这些运行时及其他运行时。
MMDP:使用任意计算进行构建¶
计算模块 (Compute Modules) 框架支持"自带计算"(BYO Compute),其中任何容器化资源都可以被导入,并通过批处理、流式和交互式函数安全地呈现。
在操作型工作流中,最重要的可执行文件和模型通常被困在特定领域的工件中,或不再积极维护的遗留包中。计算模块使这些碎片化的计算工件能够被安全地解放出来,然后在 AI 驱动的工作流中托管和使用,并与更现代的逻辑工件(如 Python、Java、SQL、Go 或 Rust 程序)并存。
Foundry 和 AIP 还可以与 Palantir 环境外部的计算资源进行编排,包括现有模型推理基础设施、Spark 集群、云托管的优化引擎以及本地运行的高性能计算资源。
MMDP 还支持将计算原生无缝下推到云原生运行时(如 Databricks 或 Snowflake),使开发人员能够使用 Pipeline Builder 和代码工作区 (Code Workspaces) 等工具与现有计算资源配合使用。
任意模型:Palantir 对模型访问的承诺¶
Palantir 对开放性和可选性的承诺延伸到了生成式 AI。MMDP 的"任意模型"理念反映了持续致力于通过 AIP 的模型目录 (Model Catalog) 提供最新的生成式 AI 模型(包括来自 OpenAI、Anthropic、Google、Meta 和 xAI 的模型),并为企业注册和使用自己的模型提供公平的竞争环境。
LLM 和多模态模型,无论是 Palantir 提供的还是自定义注册的,都可以在 Foundry 和 AIP 应用中无缝使用,包括 Pipeline Builder、Workshop、AIP Logic 和开发者工具链。
为协助管理,可以对模型的访问进行精确治理,在所有用例和工作线上设置令牌限制。同时,资源管理能力可以一致地扩展到通过 MMDP 连接的所有数据、计算和 AI 模型,无论其具体的底层模态、运行时或格式如何。
任意位置:MMDP 对开放性的承诺¶
MMDP 通过抵制单体存储和计算架构提供的简单答案,架起了分析世界与操作世界之间的桥梁。
开放数据架构利用 Apache Iceberg 等开放标准,同时为媒体、文档、流和多模态数据类型提供同等支持。
开放计算架构捆绑了通用运行时,允许团队自带计算资源,并提供丰富的接口,用于与企业内现有计算基础设施进行编排。
这种开放性延伸到了生成式 AI,通过模型目录提供多种 LLM,并能够轻松注册自定义、微调的和现有的企业模型。
借助 Palantir Apollo,所有这些维度的灵活性都与底层基础设施提供商无关,并持续根据前线遇到的最严苛需求而演进。
MMDP 的理念:"任意数据、任意计算、任意模型、任意位置。"