Investigation and cohorting(调查与分组(Investigation and Cohorting))¶
Organizations typically have significant revenue or cost saving opportunities available if they have the tools to look for them, for example, when identifying risks in a power grid, investigating potential fraud, identifying opportunities to improve material yields, or finding the next best sales action. Investigation and Cohorting workflows allow users to create a common operating picture of their organization, combine subject-matter expertise and data analysis to reveal opportunities, and implement real-world solutions.
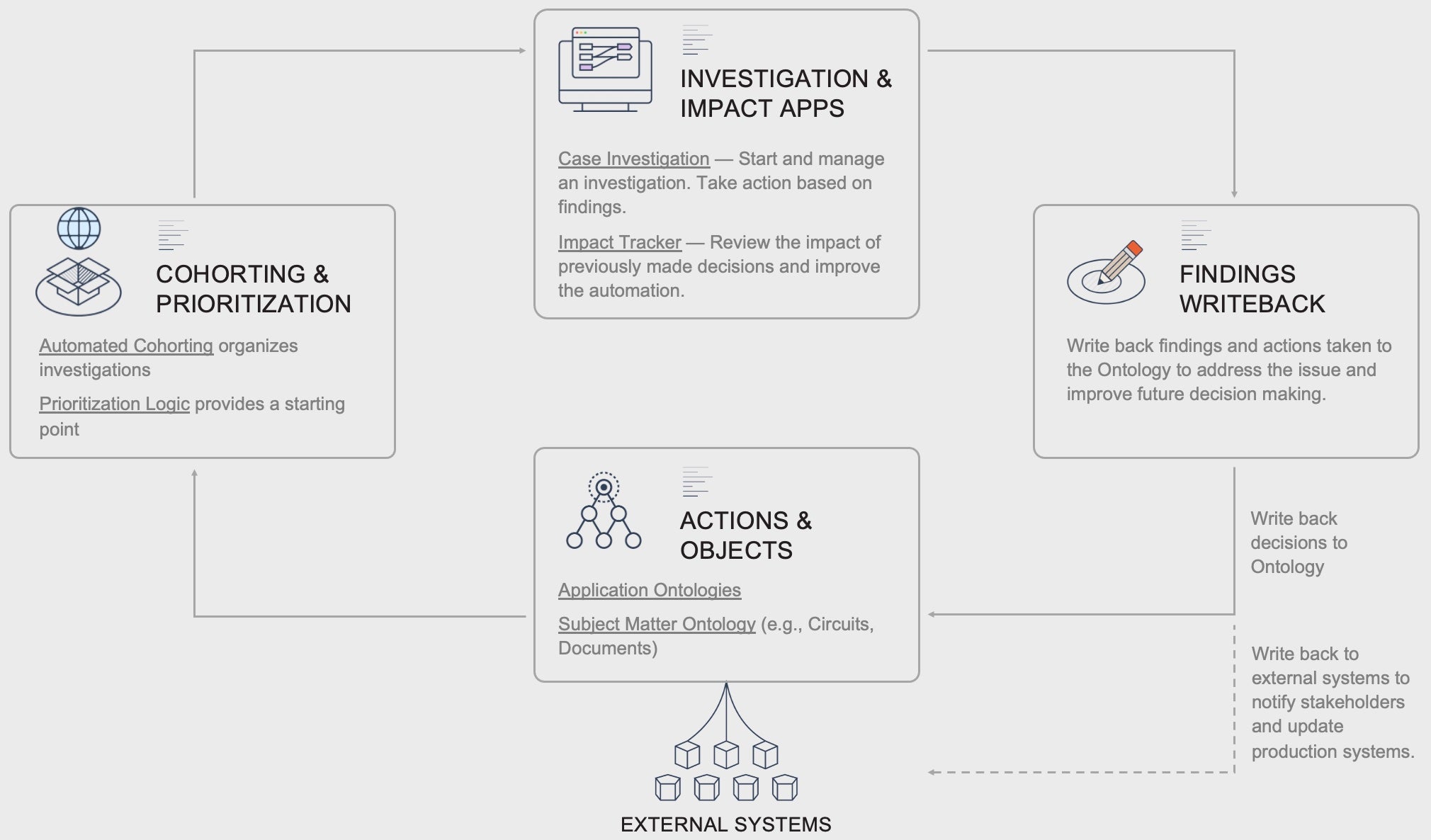
Solution¶
Investigation and Cohorting workflows are designed to understand and group real-world anomalies or problems in your data that represent revenue or savings opportunities, facilitate drilldowns into the issues, and facilitate remediation. They’re used to proactively identify issues or understand relations, following an exploratory approach, in which cohorting logic guides subject-matter expertise from analysts and is used to uncover the anomalies. With the ever-increasing amount of data, the lack of technical skills to handle complex statistical applications often presents an entry barrier for analysts or forces an organization to drastically reduce the complexity of their data.
These workflows nearly always require a toolset that allows for fast analysis and exploration of large, often isolated, data assets. Results would then need to be stored and reused and typically also need to be reproducible.
In Foundry, these workflows combine different tools for users with different skillsets, but all rely on the same data asset, the Ontology, which models the relevant organizational objects and relations between them. Automated business logic and / or ML Cohorting is applied to provide a starting point for investigations and Foundry’s various analysis tools are used to drill down into the issues. Finally, Ontology writeback is used to update the Ontology and external source systems to remediate or action the issue.
Key Elements¶
User Interfaces¶
Exploratory Analysis
To investigate your data and test hypothesis, analysts often rely on exploratory analysis. They would start with a top-down approach, taking a high-level look at large datasets, and from there trimming it down by transforming, filtering, or aggregating it to test their hypothesis. For example, in the Material Yield Application, analysts review the worst-performing materials weekly and drill down via Contour to identify savings opportunities.
In the past, this method was reserved for highly technical analysts who have the skills to use the tools which can handle large datasets and compare results, which often meant that the process was bottlenecked on a few users and iteration speed was slow.
In Foundry, users rely on a set of code and no-code tools to analyze any dataset, regardless of its size, in seconds. Not only does it provide a set of tools to visually explore data, thus decreasing the entry barrier, but by leveraging the Ontology, it also provides a lot of operational context to the user.
Related products:
Case Investigation
Investigations might start as a result from the Alerting Workflow Pattern (e.g. trends or outages in a power grid), a prioritized cohort (e.g. manufacturing processes with the lowest performing yields), or the user looking for an opportunity (e.g. salespeople identifying their next action).
They either start from a single Object or a small subset of Objects. Investigations are rarely open ended; instead, they most often have a defined goal (e.g. understanding why the source of a customer complaint) and it’s the analysts’ task to backtrack the events from the trigger to its root cause.
Related products:
Impact Tracker
Once investigations are finished, a hypothesis has been confirmed, or the analysis has been concluded, an operational decision is taken which triggers a real-world event (e.g. triggering a team to remediate a risky asset).
Ideally, these real-world events would also reduce the risk of running into the same situation again. If this happens, the decision and action taken become important data assets themselves. Knowing when, where, and why decisions were taken, can in turn be leveraged in future investigations and analysis, allowing analysts to compare different situations over time to increase consistency.
Related products:
(Optional) Automated Clustering¶
Manual Rule Creation
Ideally, investigations are triggered proactively. Subject-matter experts may be able to estimate which errors or anomalies might occur at some point and want to monitor the data specifically for these. The thesis can be very specific (in which case they turn to the Alerting Pattern, as in the Asset Failure Operations) use case or loosely (in which case they define KPIs or business logic to look out for in the data, as in the Material Yield Application). At its simplest, the logic follows the steps an analyst would otherwise do manually at the beginning of each investigation or analysis.
Having a (at least partially) automated approach can also be used to ensure deterministic behavior, which might be required by regulators or be valuable to ensure consistency and reduce the chance of risk.
Just as in the Alerting Pattern, users can rely on Foundry’s Alert Automation, or use the same tools as in the Investigation and Exploration.
Related products:
In some cases, investigations or detecting anomalies in data doesn’t require subject-matter expertise to be applied on a case-by-case basis. When a robust and consistent data asset exists, statistical approaches might be better suited to the problem at hand. For humans, it can be hard to detect complex patterns within large amounts of data, especially when the patterns are constantly changing. With Foundry ML, models can be trained and implemented on top of large datasets. The results (whether clusters or predictions) can then be used just as any other datapoint in the platform, meaning that it can be made part of the ontology and picked up in exploratory analysis or investigations.
Related products:
Ontology¶
The Ontology stores information on how different assets are related to one another (e.g. how shipments, customers, and orders are connected), so that the users ask and answer their questions naturally.
Objects:
- Cohort
- Rules
- Subject-Matter Context Objects
Related products:
Requirements¶
Regardless of the Pattern used, the underlying data foundation is constructed from pipelines and syncs to external source systems.
Data Integration Pipelines
Data integration pipelines, written in a variety of languages including SQL, Python, and Java, are used to integrate datasources into the subject matter ontology.
Foundry can sync data from a wide array of sources, including FTP, JDBC, REST API, and S3. Syncing data from a variety of sources and compiling the most complete source of truth possible is key to enabling the highest value decisions.
Use cases implementing this pattern¶
- Improving production yield through standardized KPI reporting
- Improving retention and collection performance through intelligent repricing
- Increasing client engagement through integrated campaign management
- Preventing transformer failure via alerting and investigation support
Want more information on this use case pattern? Looking to implement something similar? Get started with Palantir. ↗
中文翻译¶
调查与分组(Investigation and Cohorting)¶
如果组织拥有合适的工具来寻找机会,通常能够发现显著的增收或降本空间,例如:识别电网风险、调查潜在欺诈、识别提升材料良率的机会,或寻找最佳下一步销售行动。调查与分组工作流(Investigation and Cohorting workflows)使用户能够创建组织的统一运营视图,结合领域专业知识与数据分析来揭示机会,并实施实际解决方案。
解决方案¶
调查与分组工作流旨在理解并对数据中代表增收或降本机会的真实异常或问题进行分组,促进对问题的深入探究,并推动问题修复。它们采用探索性方法,主动识别问题或理解关联关系,其中分组逻辑(cohorting logic)引导分析师运用领域专业知识,用于发现异常。随着数据量的持续增长,缺乏处理复杂统计应用的技术技能往往成为分析师的门槛,或迫使组织大幅降低数据复杂度。
这些工作流几乎总是需要一套工具集,能够快速分析和探索大型且通常孤立的数据资产。分析结果需要存储和复用,并且通常需要具备可复现性。
在 Foundry 中,这些工作流为不同技能水平的用户组合了多种工具,但都依赖于同一数据资产——本体(Ontology),该本体对相关组织对象及其之间的关系进行建模。通过应用自动化业务逻辑和/或机器学习分组(ML Cohorting),为调查提供起点,并利用 Foundry 的各种分析工具深入探究问题。最后,通过本体回写(Ontology writeback)更新本体和外部源系统,以修复或处理问题。
关键要素¶
用户界面¶
探索性分析(Exploratory Analysis)
为了调查数据并验证假设,分析师通常依赖探索性分析。他们采用自上而下的方法,从宏观层面审视大型数据集,然后通过转换、过滤或聚合来缩小范围,以验证假设。例如,在材料良率应用中,分析师每周审查表现最差的材料,并通过 Contour 深入分析以识别降本机会。
过去,这种方法仅限于具备处理大型数据集和比较结果所需技能的高技术分析师,这通常意味着流程受限于少数用户,迭代速度缓慢。
在 Foundry 中,用户依靠一套编码和无代码工具,在数秒内分析任何规模的数据集。这不仅提供了一套可视化探索数据的工具,降低了入门门槛,而且通过利用本体,为用户提供了丰富的运营上下文。
相关产品:
案件调查(Case Investigation)
调查可能源于告警工作流模式(例如电网中的趋势或中断)、优先分组(例如良率最低的制造流程),或用户主动寻找机会(例如销售人员识别下一步行动)。
调查从一个单一对象(Object)或一小部分对象开始。调查很少是开放式的;相反,它们通常有明确的目标(例如,理解客户投诉的根源),分析师的任务是从触发事件回溯到根本原因。
相关产品:
影响追踪器(Impact Tracker)
调查完成后,假设得到确认或分析得出结论,便会做出运营决策,触发真实世界的事件(例如,触发团队修复风险资产)。
理想情况下,这些真实世界的事件还应降低再次遇到相同情况的风险。如果发生这种情况,所做的决策和采取的行动本身就成为重要的数据资产。了解决策的时间、地点和原因,可以在未来的调查和分析中加以利用,使分析师能够比较不同时期的情况,从而提高一致性。
相关产品:
(可选)自动化聚类¶
手动规则创建(Manual Rule Creation)
理想情况下,调查是主动触发的。领域专家可能能够预估某些错误或异常何时可能发生,并希望专门监控这些数据。假设可以非常具体(此时转向告警模式,如资产故障运营用例),也可以较为宽泛(此时定义 KPI 或业务逻辑以在数据中寻找,如材料良率应用)。最简单的形式是,逻辑遵循分析师在每次调查或分析开始时手动执行的步骤。
采用(至少部分)自动化的方法还可以确保确定性行为,这可能是监管机构的要求,或者对于确保一致性和降低风险具有价值。
与告警模式一样,用户可以依赖 Foundry 的告警自动化(Alert Automation),或使用与调查和探索相同的工具。
相关产品:
在某些情况下,调查或检测数据中的异常不需要逐案应用领域专业知识。当存在稳健且一致的数据资产时,统计方法可能更适合当前问题。对于人类来说,很难在大量数据中检测复杂模式,尤其是当模式不断变化时。借助 Foundry ML,可以在大型数据集之上训练和部署模型。结果(无论是聚类还是预测)可以像平台中的任何其他数据点一样使用,这意味着它可以成为本体的一部分,并在探索性分析或调查中被使用。
相关产品:
本体(Ontology)¶
本体存储了不同资产之间如何关联的信息(例如,发货、客户和订单如何连接),使用户能够自然地提出和回答问题。
对象:
- 分组(Cohort)
- 规则(Rules)
- 领域上下文对象(Subject-Matter Context Objects)
相关产品:
要求¶
无论使用哪种模式,底层数据基础都是由管道(pipelines)构建并与外部源系统同步。
数据集成管道(Data Integration Pipelines)
使用多种语言(包括 SQL、Python 和 Java)编写的数据集成管道,用于将数据源集成到领域本体中。
Foundry 可以从多种来源同步数据,包括 FTP、JDBC、REST API 和 S3。从各种来源同步数据并编译尽可能完整的真实来源,是实现最高价值决策的关键。
采用此模式的用例¶
想了解更多关于此用例模式的信息?希望实施类似方案?立即开始使用 Palantir。↗