Announcements(公告)¶
REMINDER: Sign up for the Foundry Newsletter to receive a summary of new products, features, and improvements across the platform directly to your inbox. For more information on how to subscribe, see the Foundry Newsletter and Product Feedback channels announcement.
Share your thoughts about these announcements in our Developer Community Forum ↗.
Control transform preview inputs with code-defined input filtering¶
Date published: 2025-12-18
You can now use code-defined input filtering to control preview inputs for your Python transforms with greater precision. Previously, when using the Palantir extension for Visual Studio Code, you were limited to sampled or full dataset previews. With code-defined filtering, you can write custom filtering logic, chain multiple filters together, and combine custom code with built-in filter options for more flexibility. This feature supports Spark, Polars, Lazy Polars, and pandas.
New custom code filters¶
Write filter functions in your transform code to apply custom logic to your preview inputs:
- Parameterized filter functions: Filter functions accept parameters including
boolean,int,float, andstringtypes. - Automatic template generation: The interface automatically generates template code filters with type inference based on your input dataset.
- Drag-and-drop reordering: Add multiple filters and reorder them with drag-and-drop to adjust how they are applied.
- Persistent configuration: Filter configurations are saved locally and restored when you reopen the workspace.
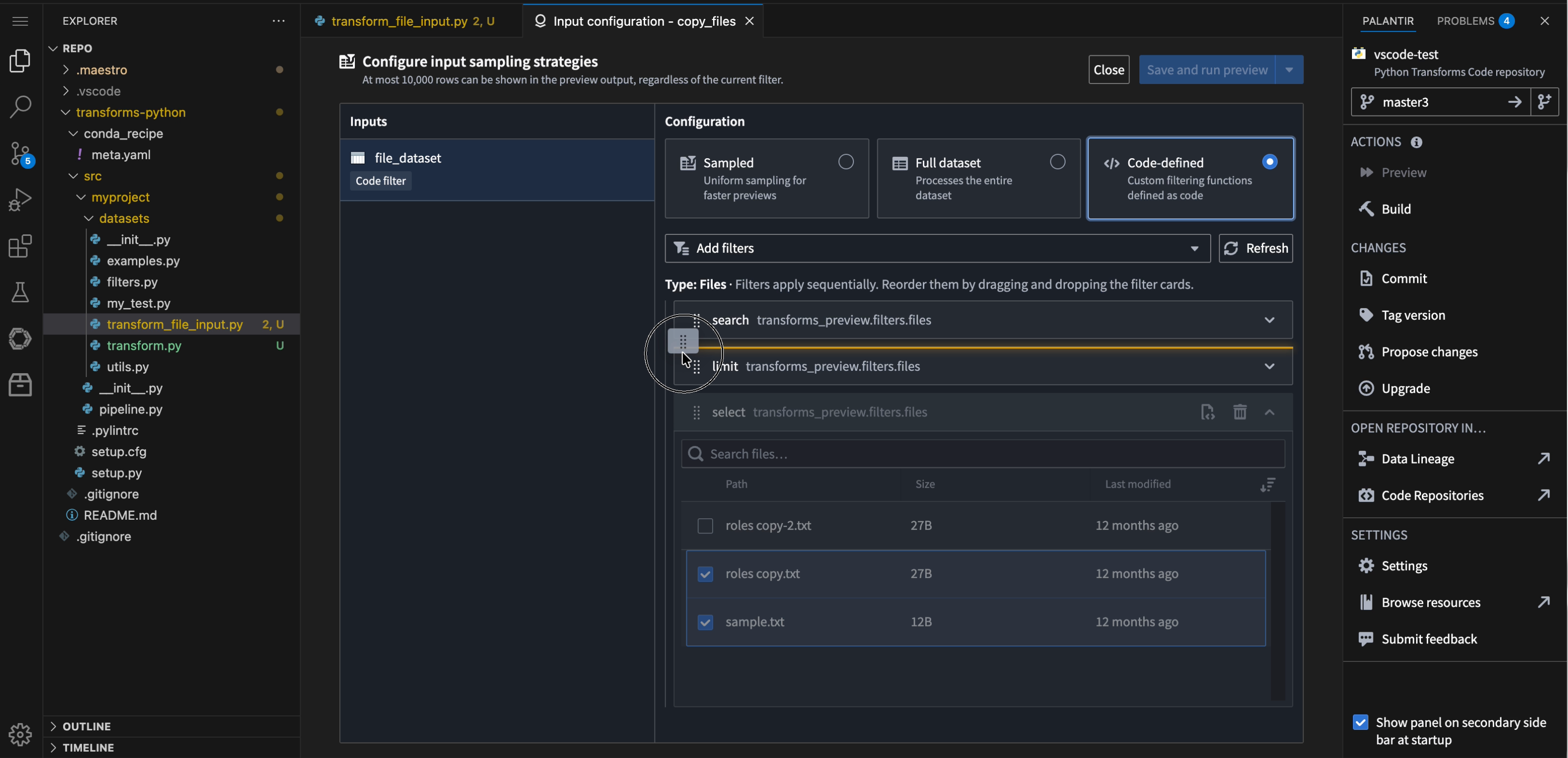
The filter configuration panel, demonstrating the new drag and drop feature for filter reordering.
New built-in file filters¶
When you stack multiple filters together, each filter displays its intermediate results, allowing you to trace the filtering flow at every stage.
New built-in filters simplify working with unstructured datasets:
- Search: Filter files using regex or glob patterns to preview only matching files in your unstructured datasets.
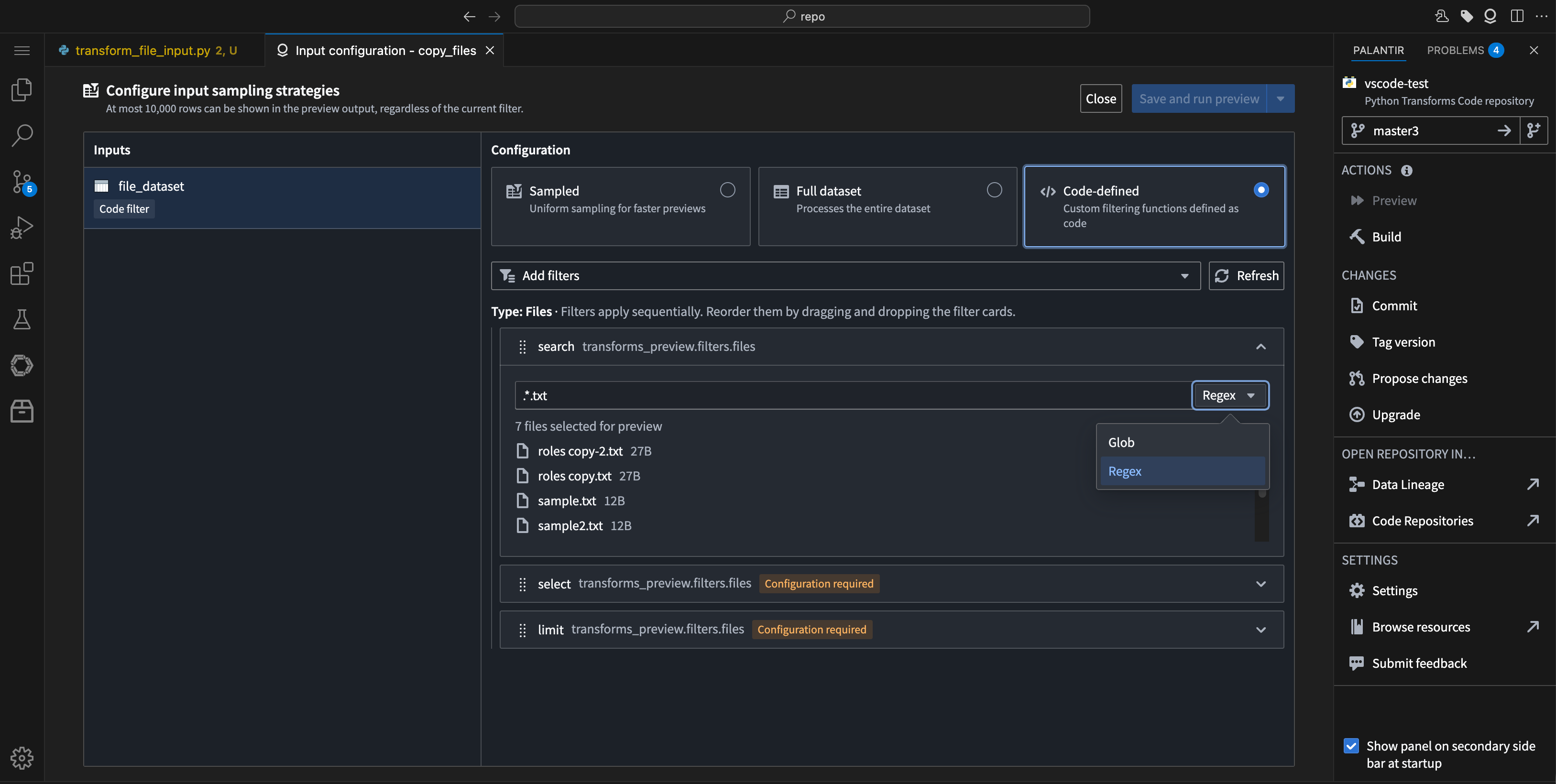
The option to choose between Regex or Glob patterns in the filter search.
- Limit: Constrain the number of results returned. This is especially useful for datasets with many files.
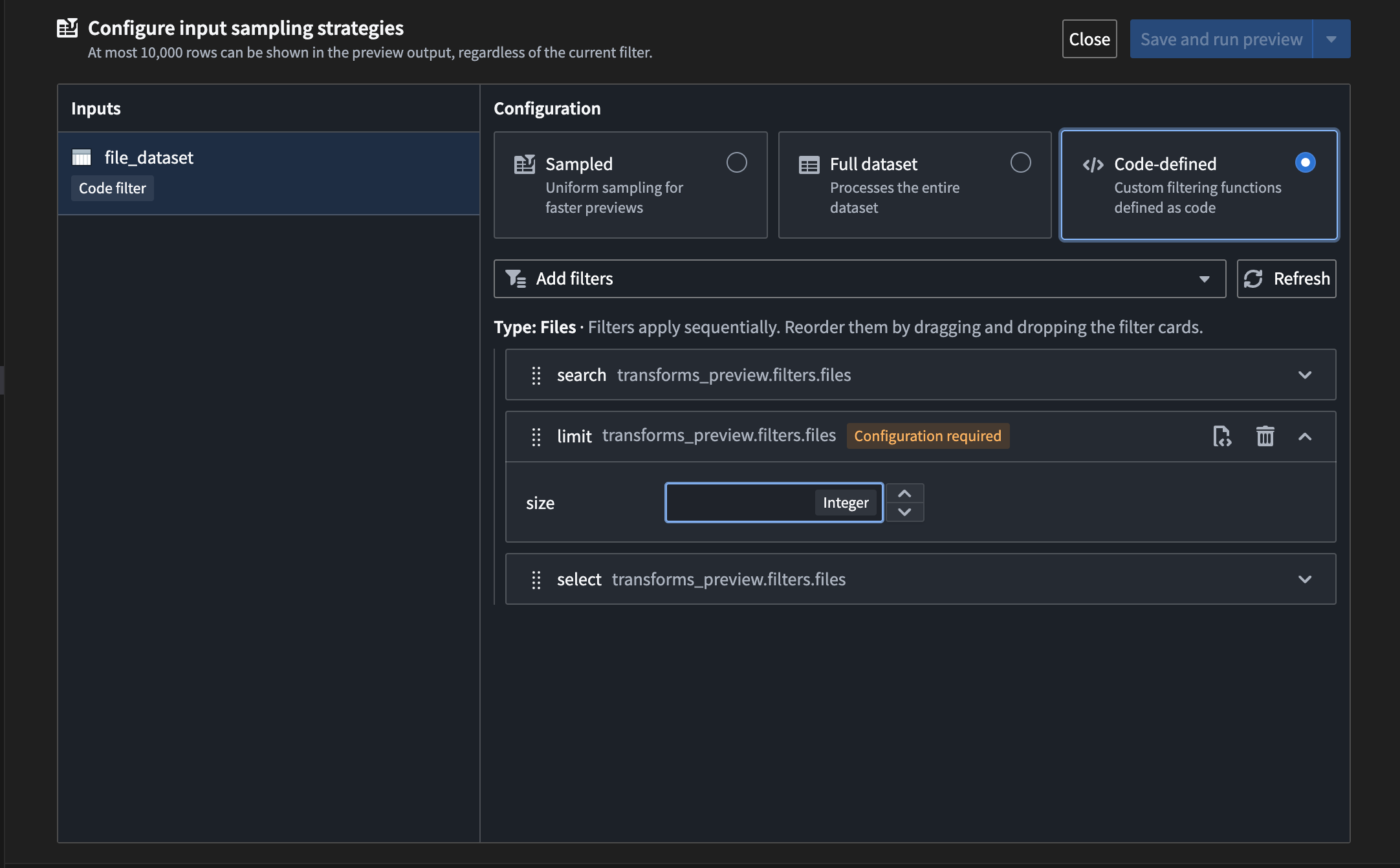
The option to set a size limit filter for file searches.
- Select: Manually choose specific files from your unstructured dataset to focus on during preview, especially when working with transforms.
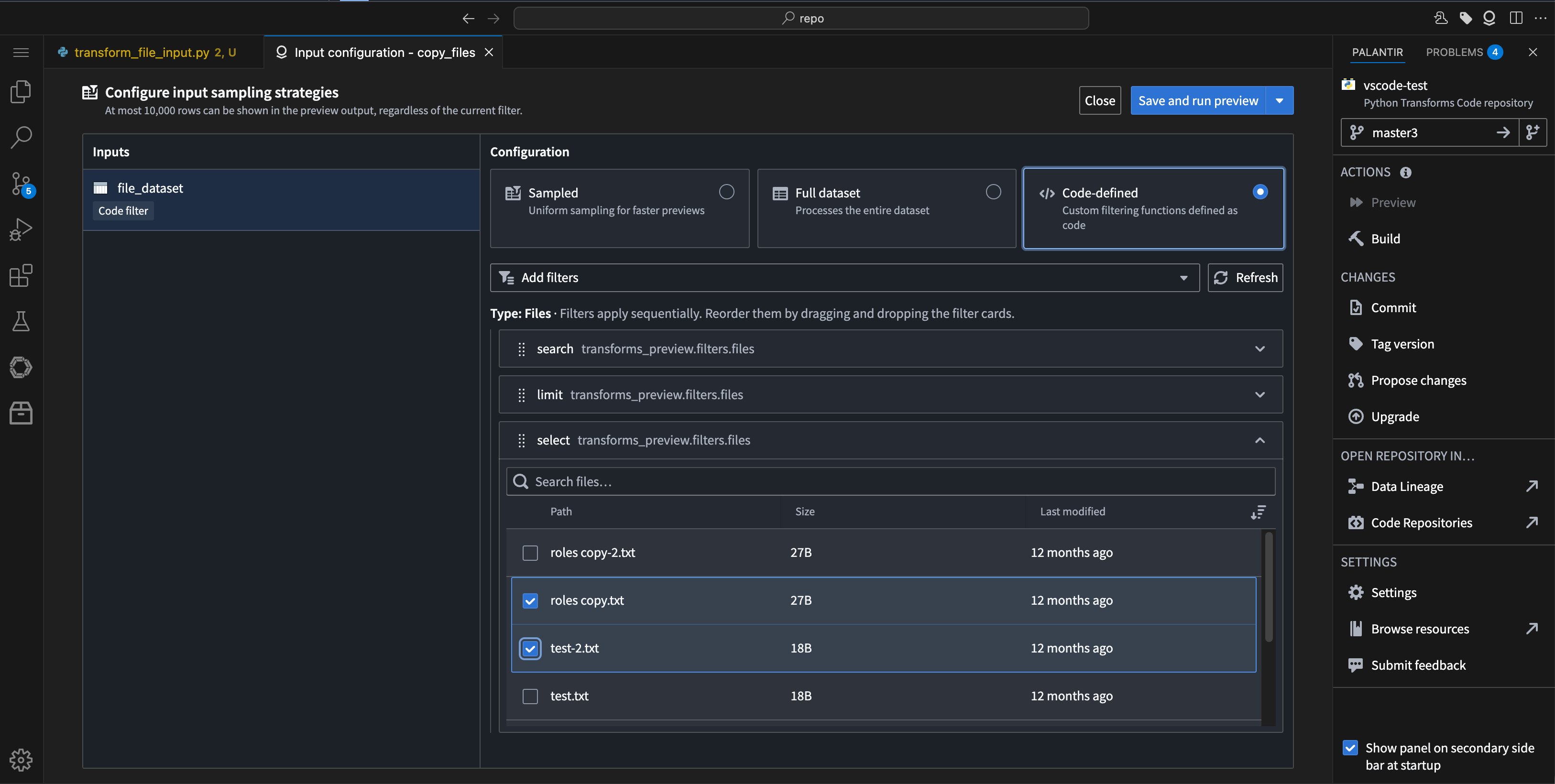
The option to select certain files from an unstructured dataset to preview.
Tell us what you think¶
Let us know about your experience working with code-defined input filtering in the Palantir extension for Visual Studio Code. Leave feedback with our Palantir Support channels or in our Developer Community ↗ using the vscode tag ↗.
New VS Code Workspaces landing page: Discover Palantir extensions and libraries directly¶
Date published: 2025-12-09
A new custom landing page in VS Code Workspaces is now available in your enrollment, designed to deliver a smoother, more intuitive onboarding experience for both new and existing users. When you open a repository, you will see a welcome page that guides you through interactive walkthroughs for Palantir's key libraries and extensions.

New VS Code Landing Page with tabs for Palantir Extension VS Code, Python transforms, and Continue walkthroughs.
What’s new?¶
- Palantir Extension for VS Code: Learn how to seamlessly integrate features from Code Repositories directly into your development workflow, whether you are working within the Palantir platform or local VS Code.
- Python transforms: Explore the core Python library for building robust data processing pipelines, with step-by-step guidance to help you get started quickly.
- Continue: Get up to speed with Continue, an AI-powered development tool, preconfigured with relevant Foundry tools to accelerate your coding and data workflows.
The new landing page replaces the default VS Code walkthrough, offering a tailored experience that makes it easier to discover and use features such as AI-assisted coding, dataset previews, and side panel shortcuts. For teams, this means faster onboarding, clearer best practices, and greater productivity.
Existing users will also benefit from streamlined navigation and quick access to new features and documentation. This upgrade helps you take full advantage of Palantir's development tools, whether you are new or experienced.
Your feedback matters¶
We want to hear about your experiences with the VS Code extension and welcome your feedback. Share your thoughts with Palantir Support channels or our Developer Community ↗ using the vscode↗ tag.
Monitor action and function metrics in near real-time in Ontology Manager¶
Date published: 2025-12-09
With the introduction of near real-time metrics on the actions and functions overview page in Ontology Manager, you can now monitor success rates, failure rates, and the newly added P95 duration chart. Metrics update continuously instead of waiting up to a day, giving you faster, more current insights into your action and function performance.
What’s new?¶
- Near real-time success/failure metrics: View the current status of your actions and functions instantly, enabling you to quickly identify and address issues as they occur.
- P95 duration metrics: Track the 95th percentile execution time for your actions and functions to identify performance bottlenecks and optimize workflows.
- Continuous data updates: Metrics are now continuously updated, providing current insights for debugging and observability.
- Link to run history: Access a complete view of action or function executions over the past seven days.

The new action metrics dashboard in Ontology Manager, indicating degrading performance of an action.

The new function metrics dashboard in Ontology Manager, showing P95 spikes.
Why it matters¶
Previously, action and function metrics could take up to a day to update, delaying troubleshooting and monitoring. With near real-time metrics, you can debug, monitor, and optimize your actions and functions as events happen, ensuring faster response times and improved reliability.
We want to hear from you¶
We hope these enhancements improve your debugging and observability experience. Share your thoughts with Palantir Support channels or on our Developer Community ↗.
Learn more about monitoring views and available monitoring capabilities for actions and functions.
Review checkpoint records with new filtering capabilities¶
Date published: 2025-12-09
Checkpoints enable administrators to review and ensure proper justification for sensitive actions taken in the platform. To simplify this workflow, we are introducing a redesigned interface for Checkpoints with enhanced filtering capabilities that support complex search combinations. Filtered views can be shared and bookmarked via URL, enabling teams to collaborate more efficiently on auditing workflows and quickly access specific records. This interface will be enabled by default the week of December 8.

The refreshed Checkpoints interface provides enhanced filtering capabilities to support complex search combinations.
What's new?¶
Filtering:
- Filter sidebar: Checkpoint record filters are now in a collapsible sidebar.
- Multi-select: All filter types except for time support multi-select (multiple values in a given filter type).
- More combinations: All filter types can be used in combination with each other.
- Sharing: Filter combinations are stored in the URL allowing users to share their current filter view or to bookmark commonly used filter combinations.
Table and details panel:
- New interface: A new modern interface for improved readability.
- Improved rendering: Some checkpointed resources now include more descriptive rendering in the table and details panel.
- Improved performance: Records and their details now load faster.
What's next?¶
We are currently developing the ability to retrieve checkpoint records through the platform SDK.
We want to hear from you!¶
Use the checkpoints tag ↗ in Palantir's Developer Community ↗ forum or contact Palantir Support to share your experience with and feedback on the new Checkpoints review page.
Grok-4.1 Fast (Reasoning), Grok-4.1 Fast (Non-Reasoning) available via xAI¶
Date published: 2025-12-04
Grok-4.1 Fast series of models is now available from xAI on non-georestricted and US georestricted enrollments.
Model overviews¶
Grok-4.1 Fast (Reasoning) ↗ is xAI's newest multimodal model optimized for maximal intelligence, specifically for high-performance agentic tool calling.
Grok-4.1 Fast (Non-Reasoning) ↗ is a faster version of the model prioritizing fast responses and a high bar for intelligence.
Both models share the following specifications:
- Context Window: 2,000,000 tokens
- Modalities: Text, image
- Capabilities: Tool use, Structured outputs
Getting started¶
To use these models:
- Confirm your enrollment administrator has enabled relevant model family
- Review token costs and pricing
- See the complete list of all the models available in AIP
Your feedback matters¶
We want to hear about your experiences using language models in the Palantir platform and welcome your feedback. Share your thoughts with Palantir Support channels or on our Developer Community ↗ using the language-model-service tag ↗.
Claude Opus 4.5 available via Direct Anthropic, Google Vertex, AWS Bedrock¶
Date published: 2025-12-04
Claude Opus 4.5 is now available from Anthropic, Google Vertex and AWS Bedrock on non-georestricted enrollments.
Model overview¶
Anthropic’s newest model, Claude Opus 4.5, is among the best in class LLMs for workflows involving coding, agents, and computer use. Opus 4.5 is available at a price point that is 3x cheaper than previous Opus models, and runs more efficiently with less interventions required. For more information, review Anthropic's documentation on the model ↗.
- Context Window: 200,000 tokens
- Modalities: Text, image
- Capabilities: Extended thinking, function calling
Getting started¶
To use these models:
- Confirm your enrollment administrator has enabled relevant model family or families
- Review token costs and pricing
- See the complete list of all the models available in AIP
Your feedback matters¶
We want to hear about your experiences using language models in the Palantir platform and welcome your feedback. Share your thoughts with Palantir Support channels or on our Developer Community ↗ using the language-model-service tag ↗.
Codex models available in AIP via Azure OpenAI and Direct OpenAI¶
Date published: 2025-12-04
GPT-5.1 Codex, GPT-5.1 Codex mini, GPT-5 Codex are now available on non-georestricted enrollments with Azure OpenAI and/or Direct OpenAI enabled.
Model overviews¶
Three advanced OpenAI models are now available for use: GPT-5-Codex, GPT-5.1-Codex, and GPT-5.1-Codex mini. These models are designed to support a wide range of coding, reasoning, and automation tasks, with the 5.1 series offering the latest advancements in capability and efficiency.
GPT-5.1-Codex ↗ is the latest and most capable agentic coding model from OpenAI, optimized for complex reasoning, code generation, and advanced automation tasks. It is ideal for users seeking the best performance and up-to-date features for demanding applications.
GPT-5.1-Codex mini ↗ is a smaller, more cost-effective variant of GPT-5.1-Codex. It is designed for users who need efficient, scalable solutions for less complex coding and automation tasks.
GPT-5-Codex ↗ is a model optimized for agentic coding tasks and automation.
All three of these models share the following specifications:
- Context Window: 400,000 tokens
- Max Output Tokens: 128,000 tokens
- Knowledge Cutoff: Sep 30, 2024
- Modalities: Text, Image inputs; Text outputs
- Features: Structured outputs, streaming, function calling
Getting started¶
To use these models:
- Confirm your enrollment administrator has enabled relevant model family or families
- Review token costs and pricing
- See the complete list of all the models available in AIP
Your feedback matters¶
We want to hear about your experiences using language models in the Palantir platform and welcome your feedback. Share your thoughts with Palantir Support channels or on our Developer Community ↗ using the language-model-service tag ↗.
Source terminal now available in Data Connection¶
Date published: 2025-12-02
Source terminal is a new tool to help debug connectivity issues of sources using network egress policies. You can run commands in a terminal that has the same networking access as the source, allowing you to test connectivity to external systems with commands like dig, curl, netcat and openssl.
How to use¶
To access the terminal from Data Connection, select Debug in the Network Connectivity panel under Connection details.
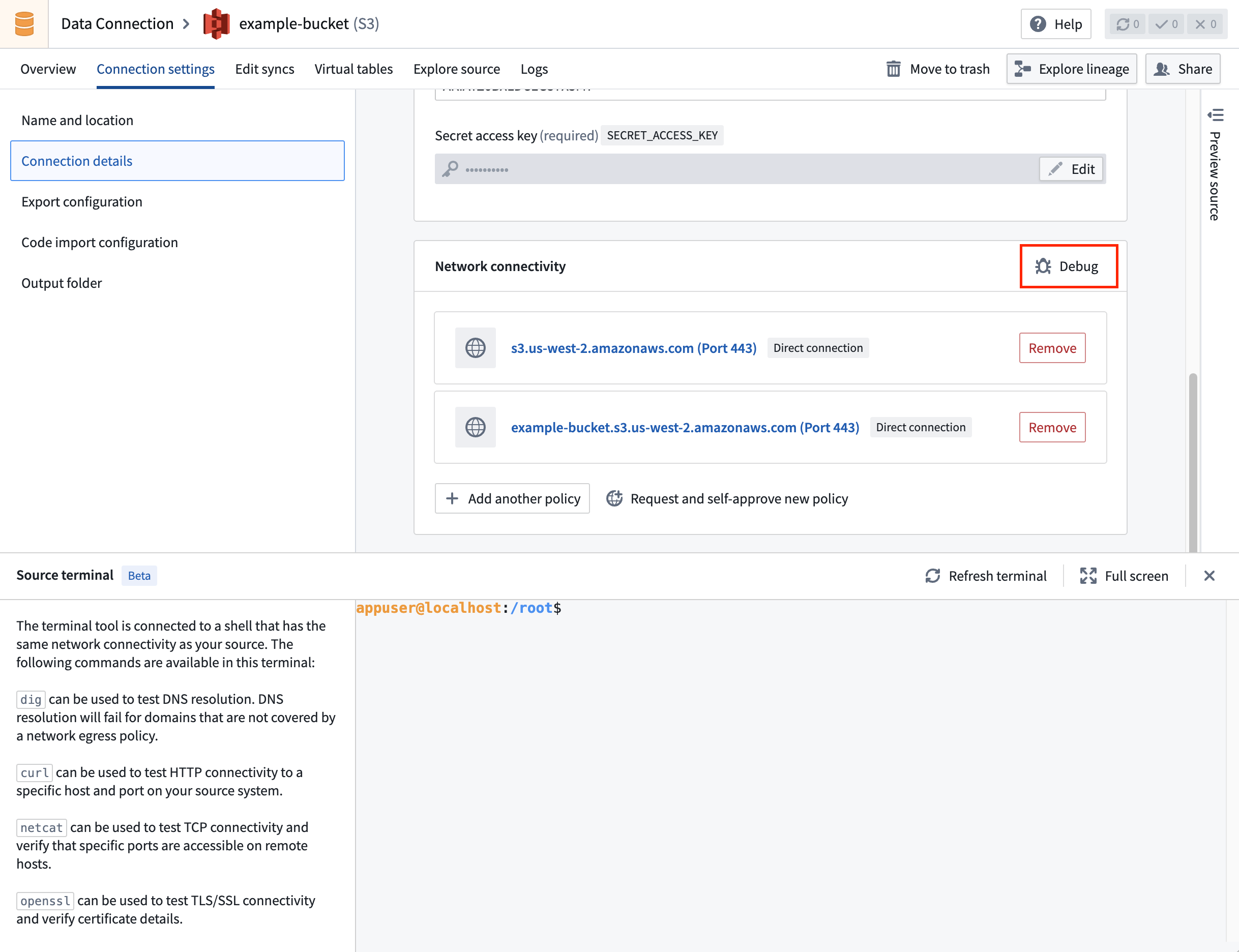
Source terminal is accessible via the Connection settings tab.
Use this feature to significantly improve debugging speed and experience for common network issues: failed DNS resolution, SSL handshake failures due to missing certificates, and firewall-blocked traffic.
Find more details about this feature in the documentation.
Your feedback matters¶
As we continue to add Data Connection features, we want to hear about your experiences and welcome your feedback. Share your thoughts with Palantir Support channels or our Developer Community ↗ or post using the our data-connection tag ↗.
Faster pipelines in Pipeline Builder are now generally available¶
Date published: 2025-12-02
Previously known as lightweight pipelines during their beta phase, faster pipelines created in Pipeline Builder significantly improve execution speed for both batch and incremental pipelines built on datasets of varying sizes. This faster pipeline option is now generally available across Foundry enrollments.
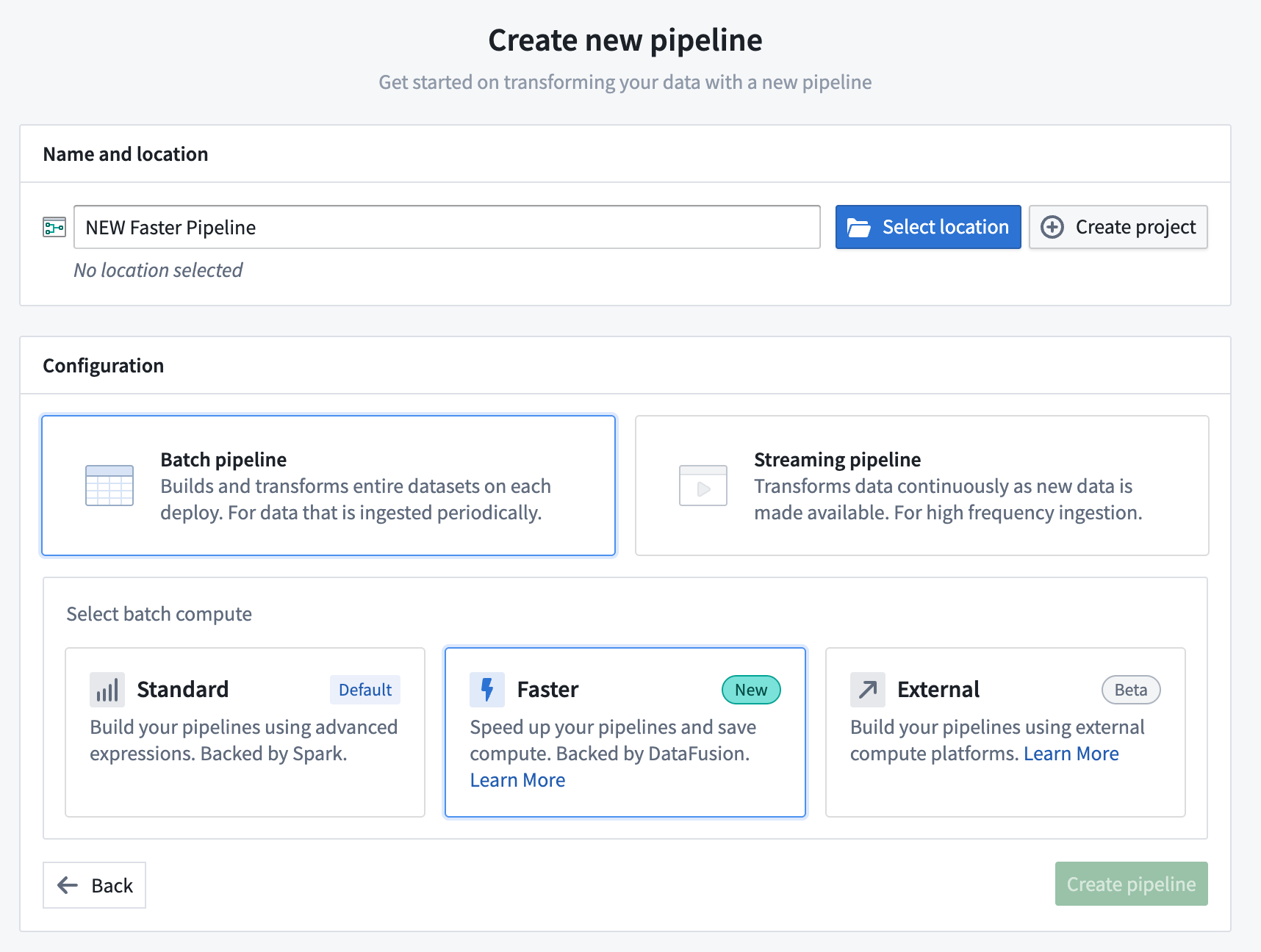
You can configure a Faster pipeline when creating a new pipeline in Pipeline Builder.
What are faster batch pipelines?¶
Powered by DataFusion ↗, an open-source query engine written in Rust ↗, faster pipelines can substantially accelerate compute processes compared to traditional Spark-based pipelines while supporting rapid, low-latency execution.
When to use faster pipelines¶
Pipelines that typically run in under 15 minutes will benefit most from their conversion to a faster pipeline, though builds which take longer or run on large-scale datasets may also experience reduced execution time and compute resource usage. Pipeline Builder enables you to seamlessly convert between standard batch pipelines and faster pipelines at any time through the Settings menu, so you can experiment with different pipeline types to optimize performance for your workflows.
When converting an existing standard batch pipeline to a faster pipeline, Pipeline Builder will warn you if the pipeline contains incompatible transforms or expressions.
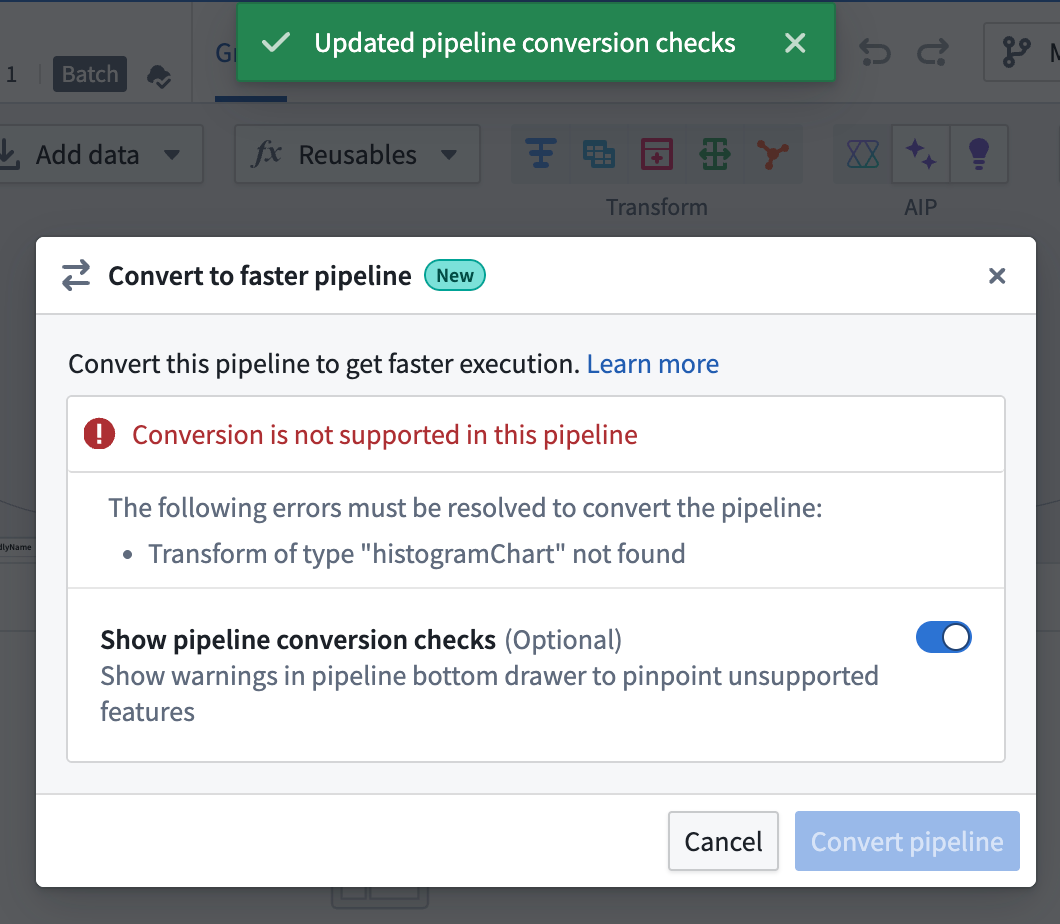
Use the Settings menu to convert an existing pipeline and view incompatible transforms or expressions to resolve.
After you toggle on Show pipeline conversion checks, a Faster conversion compatibility checks section appears in the Pipeline warnings panel at the bottom of the screen.
This section lists any transforms and expressions that are not supported with faster pipelines. You can quickly locate the node with an unsupported transform by selecting the Go to node icon.
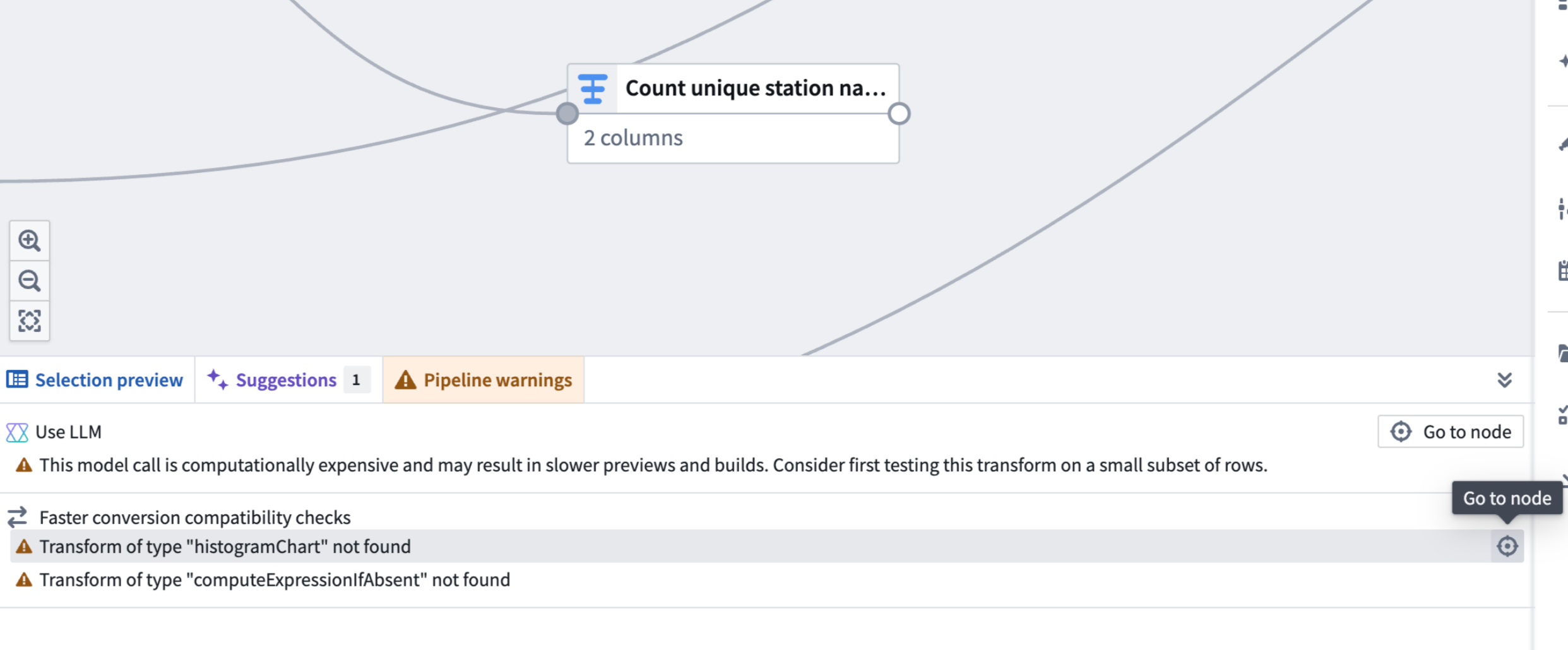
The Pipeline warnings panel displays an incompatible transform.
How to build and use faster pipelines¶
Review the existing documentation to build a faster pipeline or convert an existing standard pipeline.
Manage ontology resource permissions through projects in the Compass filesystem¶
Date published: 2025-12-02
Ontology resources (object types, link types, action types, shared properties, and interfaces) can now be integrated with the Compass filesystem on supported enrollments, with the resources appearing as files within projects alongside other resources like Workshop applications and datasets. You can organize ontology resources into folders, apply tags, add them to the project catalog, and permission them using the same familiar Compass project roles. This unified approach, currently in beta, replaces the previous ontology permission models: ontology roles and datasource-derived permissions. To use, ontology owners must first enable this feature in Ontology Manager — review the How to enable section below for details.
Read more about project-based ontology permissions in our documentation.
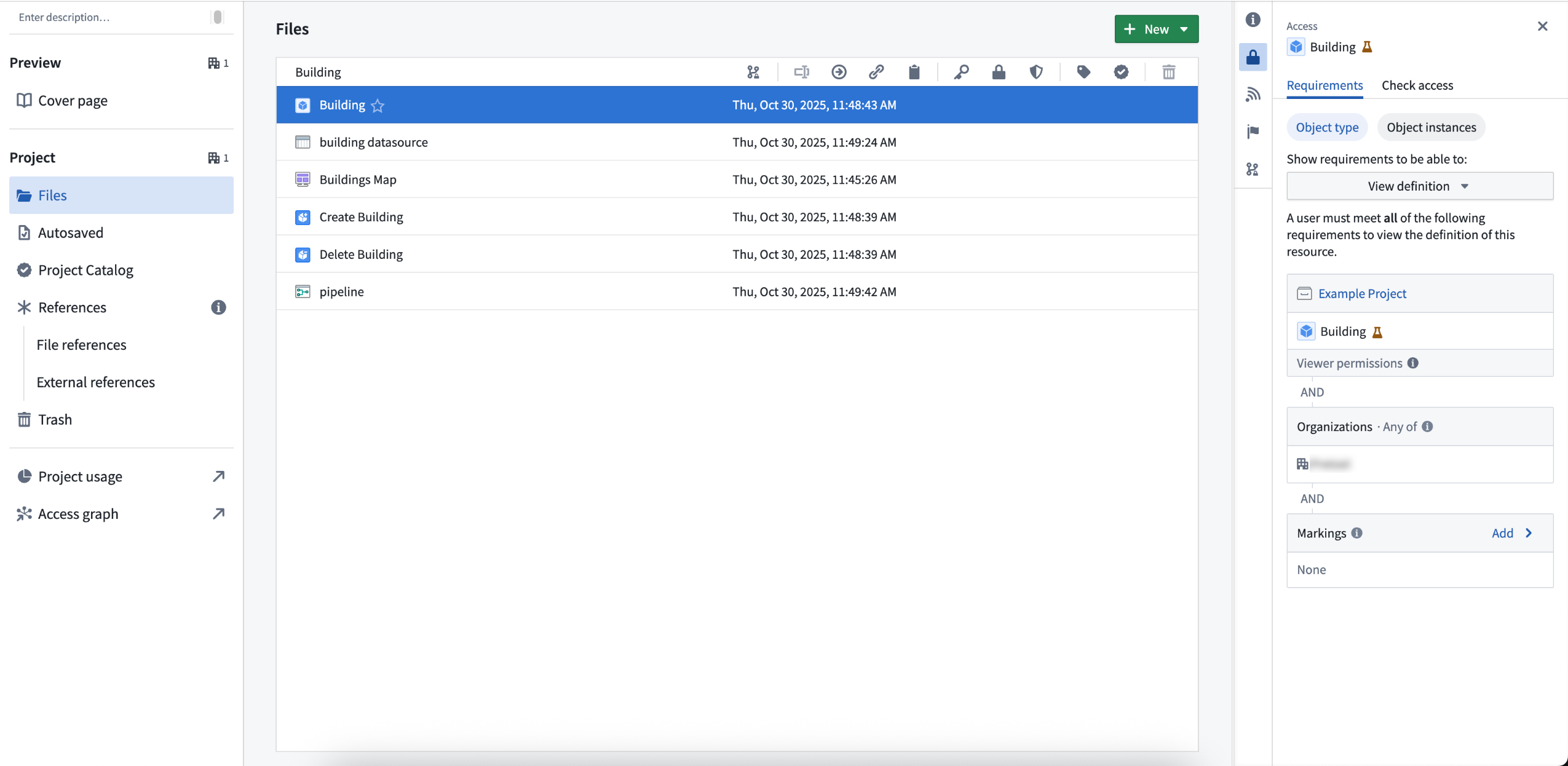
When this feature is turned on, new ontology resources will be permissioned through projects in the Compass filesystem.
Example of how the new permission model works¶
For example, consider an object type called Building, now saved as a file in project A. Your ability to view, edit, or manage Building depends on your role in project A. If you are an editor in project A, you can edit the Building object type.
To view specific Building objects (like Empire State Building), you need the Viewer role on both the object type and its datasource. If you only have viewing rights for the object type, you can only see information such as schema and contact information, not the actual data. If you need help understanding the permissions required, review the Compass project side-panel for more details.
This approach makes managing permissions in the Palantir platform easier by allowing all resource types to be managed as project resources, enabling you to permission entire workflows in the filesystem.
How to enable¶
To save new ontology resources into projects by default, ontology owners can navigate to the Ontology configuration tab in Ontology Manager and toggle on Require new ontology resources be saved in project. Once enabled, you will be prompted to choose a save location when creating new ontology resources. Turning this feature on does not affect existing ontology resources.
To migrate existing ontology resources, use the migration assistant in the Ontology configuration tab of Ontology Manager, which will suggest filesystem locations for each resource. You can migrate a resource if you are an Owner on it and at least an Editor on the chosen project. Learn more about migrating existing ontology resources using migration assistant.
Limitations¶
This feature is not available for default ontologies or with classification-based access controls.
We want to hear from you¶
As we continue developing new features for the ontology, we welcome your feedback. Share your thoughts with Palantir Support channels or our Developer Community ↗ and use the ontology-management ↗ tag.
Use Workflow Lineage to visualize and manage workflows¶
Date published: 2025-12-02
Easily track and update workflow resources and relationships with Workflow Lineage (previously known as Workflow Builder). Now generally available, Workflow Lineage enables better management of the resources that power your applications, with features spanning AI model visibility, bulk updating resources and user permissions, and Marketplace packaging assistance.
The graph and application views of Workflow Lineage.
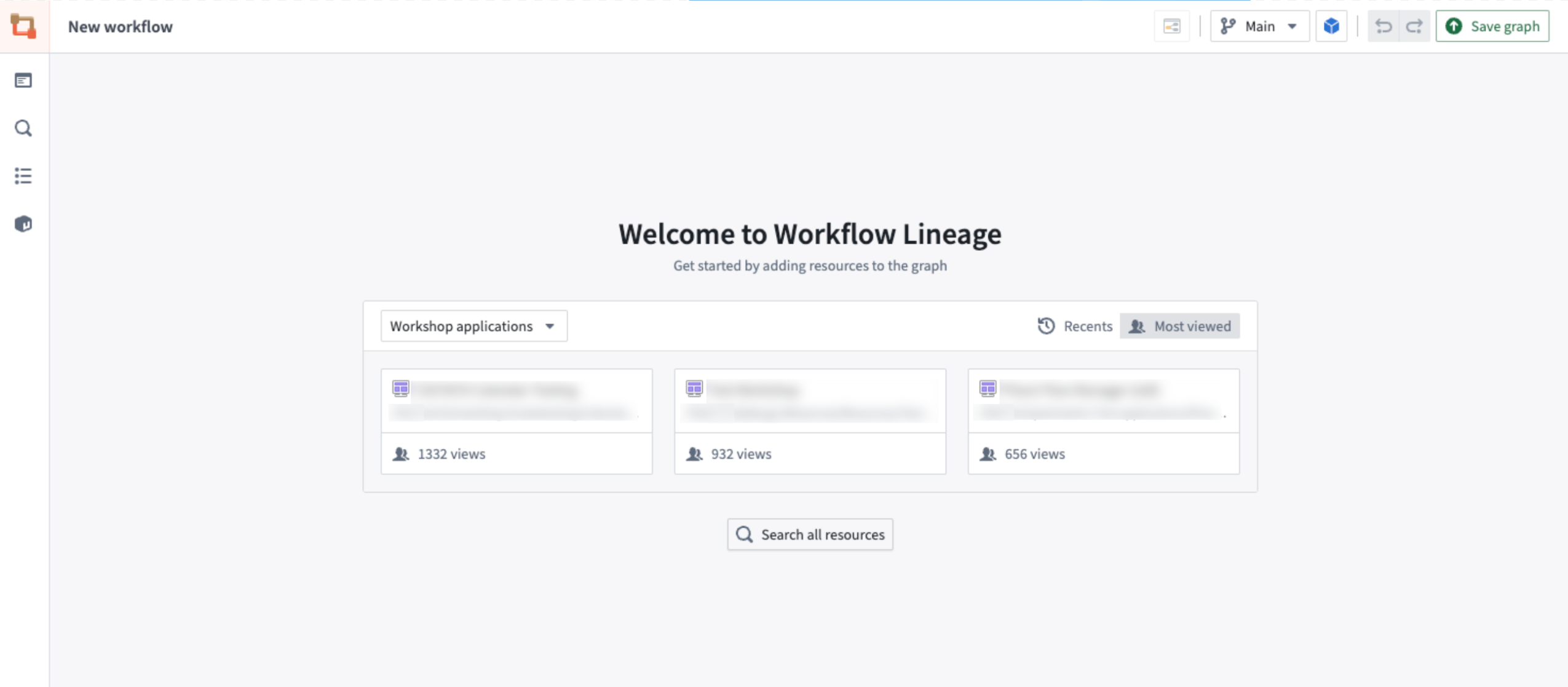
The Workflow Lineage landing pages displays Workshop modules to quick-start a lineage graph.
Getting started¶
Use Cmd + I (macOS) or Ctrl + I (Windows) to automatically generate a Workflow Lineage graph depicting the relevant objects, actions, and functions. Alternatively, open an existing Data Lineage graph and select Workflow Lineage in the top right corner to open the corresponding graph.

The option to create a Workflow Lineage graph from the Data Lineage application header.
Streamline your workflow management¶
You can use Workflow Lineage to bulk change and update versions and criteria across your resources:
- Keep workflows up-to-date with bulk update features for function-backed actions, functions in Workshop modules, and logic. Use the Out-of-date dependencies color mode to select the nodes you wish to update, then choose to bulk update from the bottom panel.
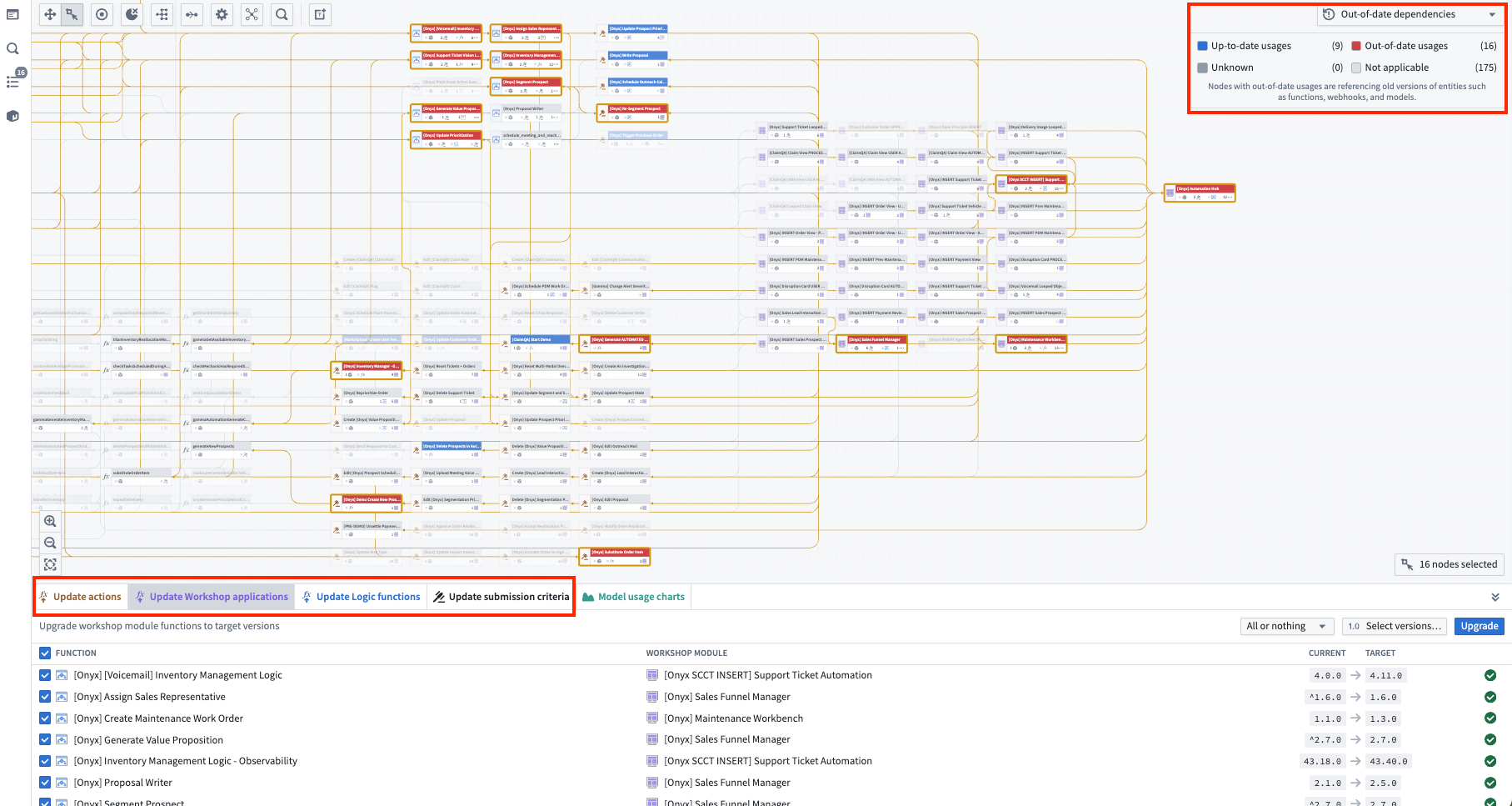
The bottom upgrade panel allows you to upgrade all function versions at once.
- Manage resources with tools to bulk delete object types and bulk publish Workshop modules. Right-click on selected nodes to perform bulk actions.
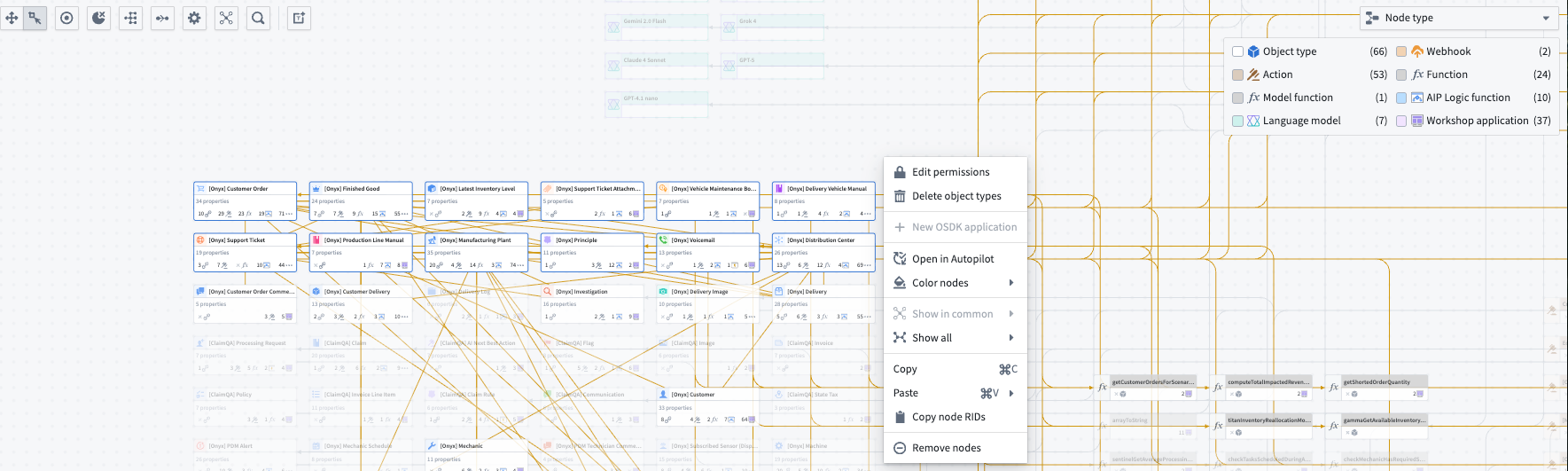
The right-click menu on selected nodes to apply bulk actions.
- Track property usage across all downstream usages of properties and resources including object types, automations, functions, Workshop modules, and actions. Select an object and use the Selection details panel on the left to view the properties and their usages.
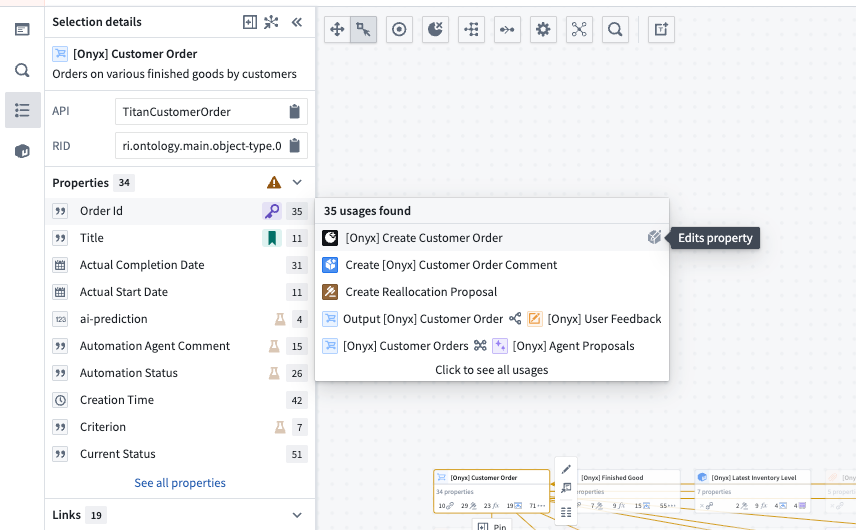
The Selection details side panel reveals downstream property usages in one easy view.
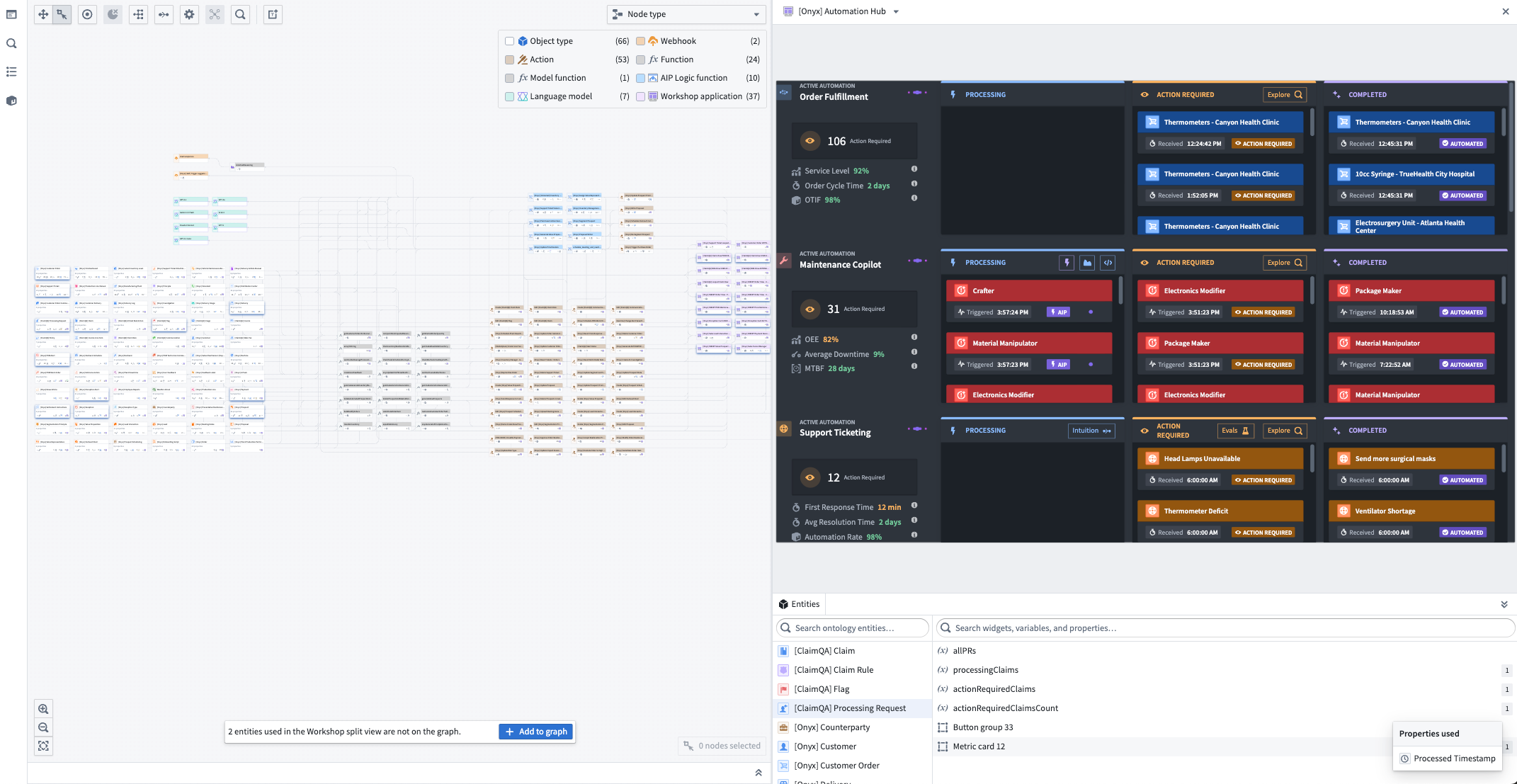
Track AI usage and performance¶
Visualize and monitor token and model usage with detailed success vs. rate-limit breakdowns, plus comprehensive charts showing usage trends over time.
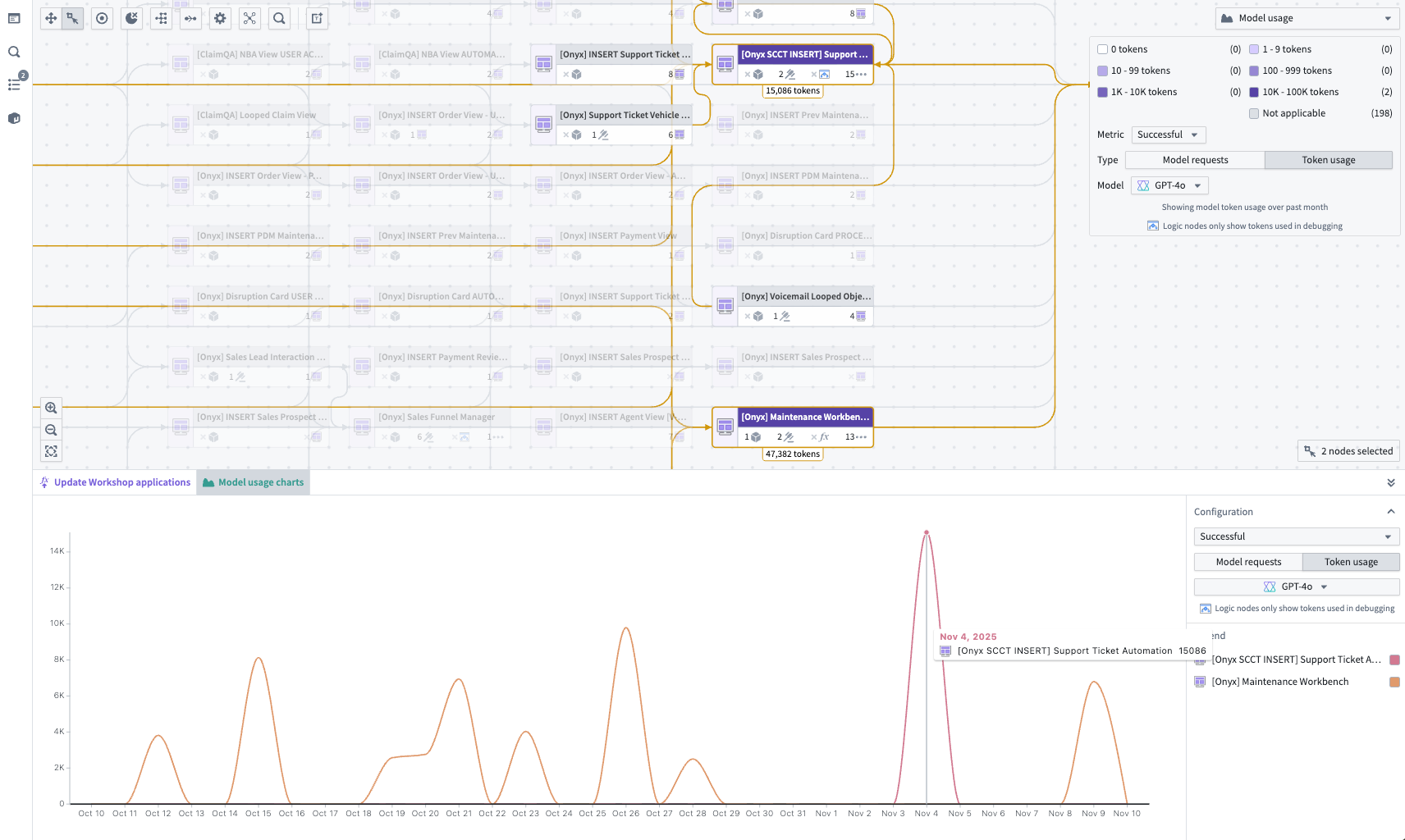
The Model usage color legend in the top right and Model usage charts in the bottom panel offer different views to understand trends of token and model utilization over time
Observe user permissions¶
Bulk update submission criteria across multiple actions and easily find actions with matching criteria for faster permission management. Manage and align submission criteria using color modes and bulk upgrade functionality.
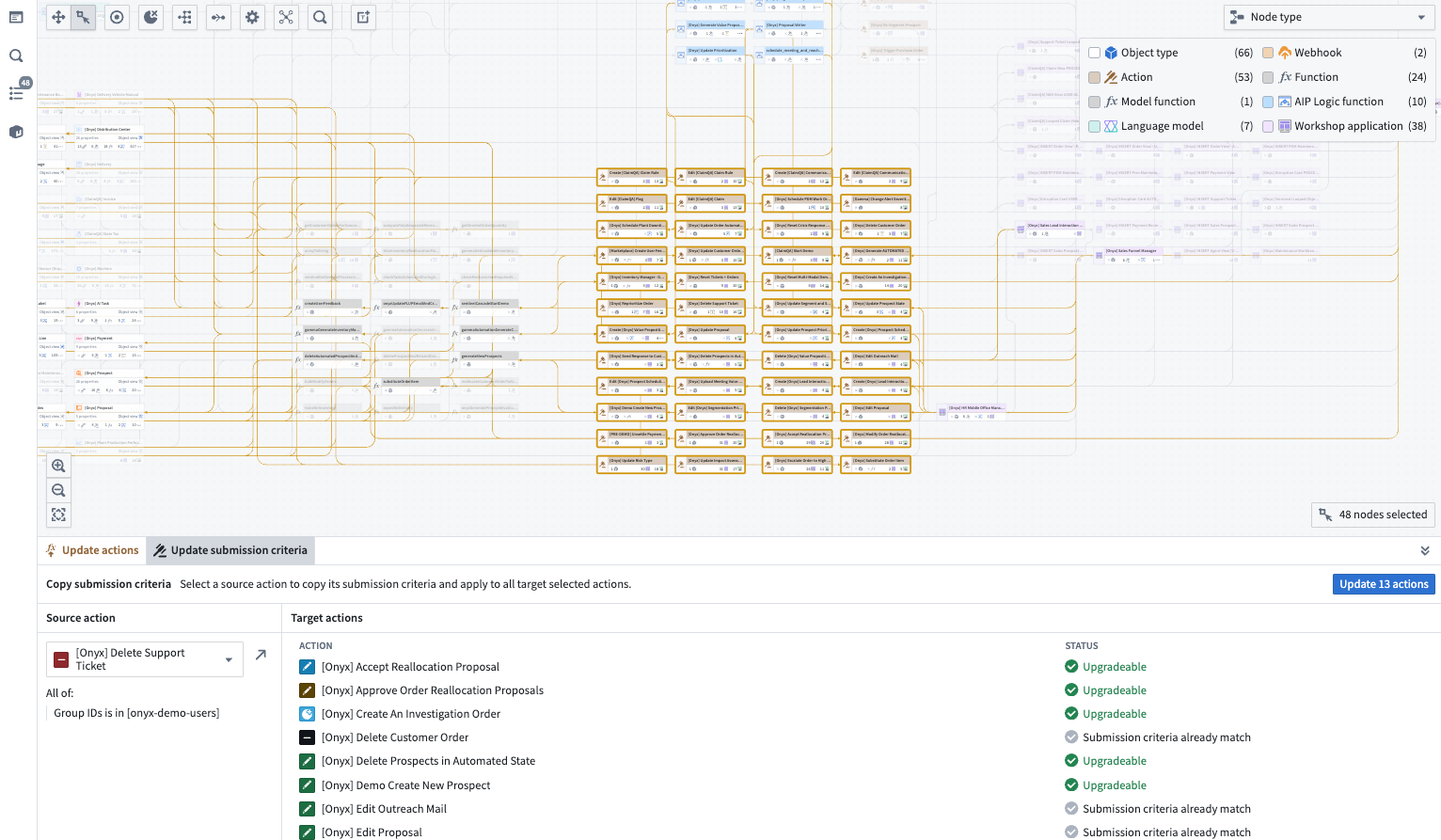
A view of action submission criteria available to bulk update in a Workflow Lineage graph.
Monitor run history and action logs¶
View run history and action metrics in the bottom panel to help debug and pinpoint changes.
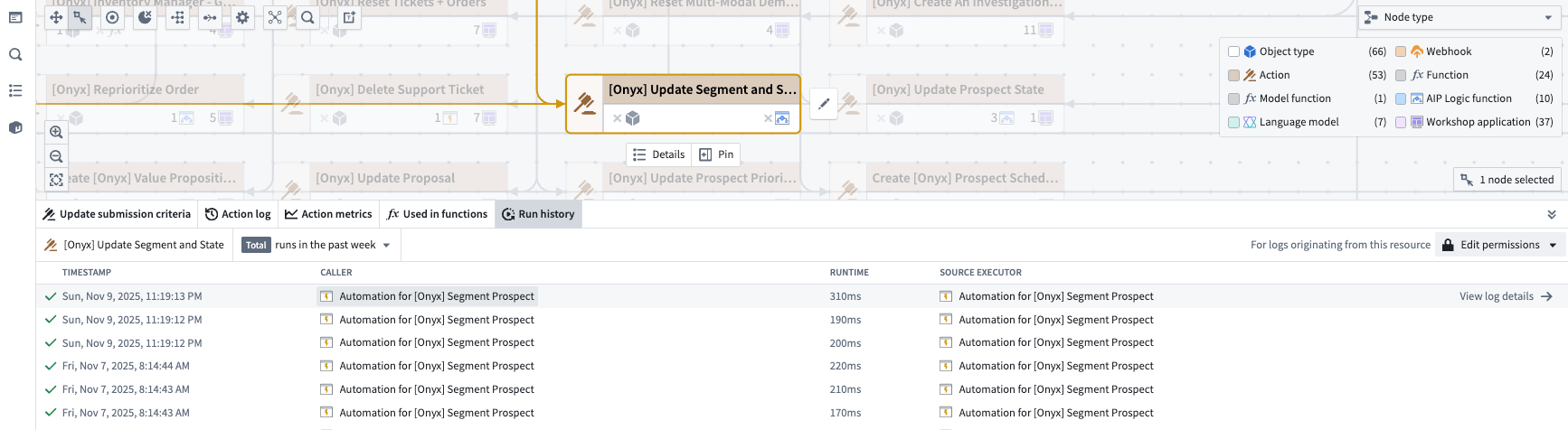
The run history of a selected action node.
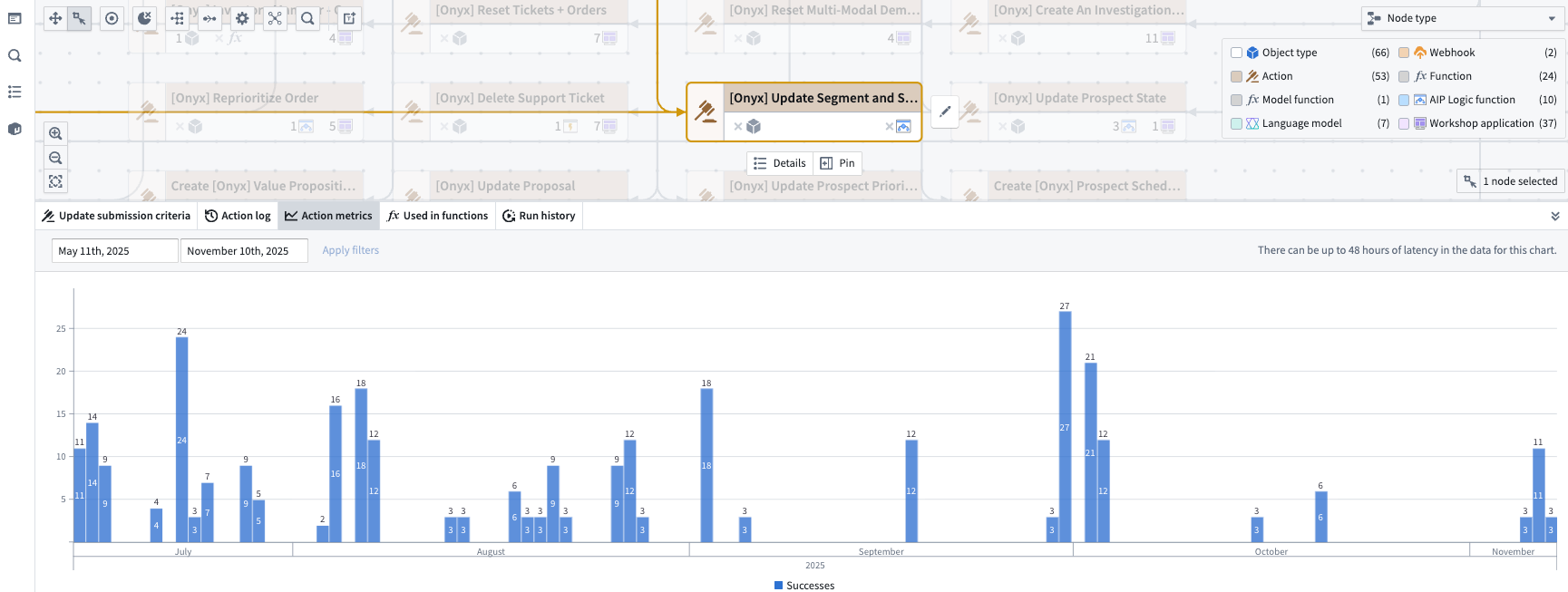
The metrics of a selected action node.
Package for Marketplace¶
Inspect the resources used in your products and view overlaps and dependencies. You can package your workflow graph together and visualize your Marketplace-packaged resources and their connections in the graph.
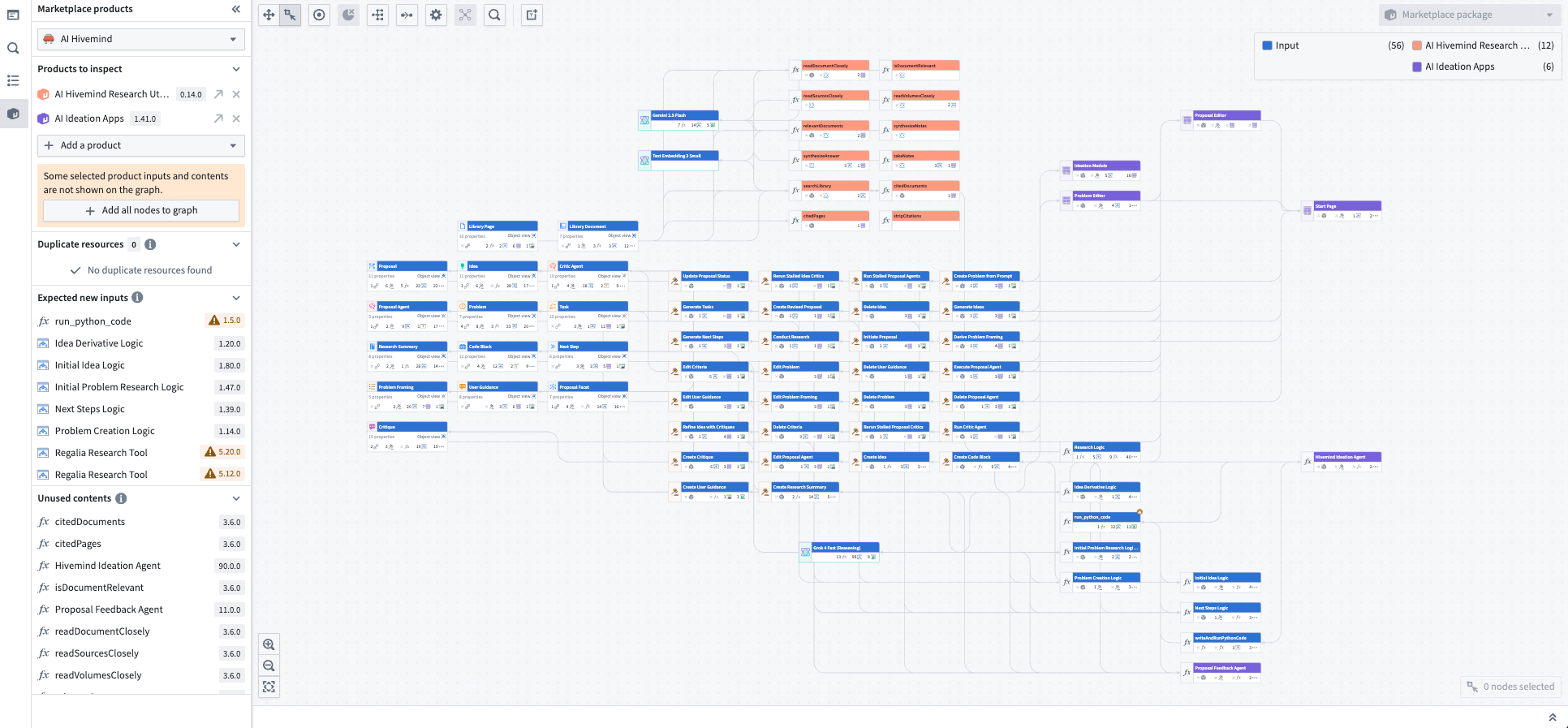
The graph of a packaged Marketplace product showing all connected resources.
Share your thoughts, and join our AMA!¶
We are holding an AMA session with the Workflow Lineage team to share what's happening behind the scenes and hear about your experiences. This AMA will run asynchronously in our Developer Community forum ↗ from Monday, December 1 through Tuesday, December 16, with Workflow Lineage team members monitoring this thread daily and responding to your questions and comments.
We also welcome your feedback in our Palantir Support channels, and you can post in our Developer Community ↗ using the workflow-lineage tag ↗.
GPT-5.1 available via Azure OpenAI, Direct OpenAI on non-georestricted enrollments¶
Date published: 2025-12-01
GPT-5.1 is now available from Azure OpenAI and Direct OpenAI on non-georestricted enrollments.
Model overview¶
GPT-5.1 balances intelligence and speed by dynamically adapting how much time the model spends thinking based on the complexity of the task. It also features a “no reasoning” mode to respond faster on tasks that don’t require deep thinking. For more information, review OpenAI’s documentation on the model ↗, and their GPT-5.1 prompting guide ↗.
- Context Window: 400,000 tokens
- Modalities: Text, Image
- Capabilities: Structured outputs, function calling, reasoning effort
Getting started¶
To use these models:
- Confirm your enrollment administrator has enabled relevant model family or families
- Review token costs and pricing
- See the complete list of all the models available in AIP
Your feedback matters¶
We want to hear about your experiences using language models in the Palantir platform and welcome your feedback. Share your thoughts with Palantir Support channels or on our Developer Community ↗ using the language-model-service tag ↗.
中文翻译¶
公告¶
提醒: 订阅 Foundry 新闻通讯(Newsletter),即可直接在收件箱中接收关于新产品、功能及平台改进的摘要。有关如何订阅的更多信息,请参阅 Foundry 新闻通讯与产品反馈渠道公告。
欢迎在我们的开发者社区论坛 ↗分享您对这些公告的看法。
通过代码定义的输入过滤控制转换预览输入¶
发布日期:2025-12-18
您现在可以使用代码定义的输入过滤更精确地控制 Python 转换(transform)的预览输入。此前,在使用 Palantir Visual Studio Code 扩展时,您只能使用采样或完整数据集预览。借助代码定义的过滤,您可以编写自定义过滤逻辑、将多个过滤器串联在一起,并将自定义代码与内置过滤选项相结合,以获得更高的灵活性。此功能支持 Spark、Polars、Lazy Polars 和 pandas。
新的自定义代码过滤器¶
在转换代码中编写过滤器函数,将自定义逻辑应用于预览输入:
- 参数化过滤器函数: 过滤器函数接受包括
boolean、int、float和string类型的参数。 - 自动模板生成: 界面会根据您的输入数据集自动生成带有类型推断的模板代码过滤器。
- 拖放重新排序: 添加多个过滤器并通过拖放重新排序,以调整它们的应用方式。
- 持久化配置: 过滤器配置会保存在本地,并在您重新打开工作区时恢复。
过滤器配置面板,展示了用于过滤器重新排序的新拖放功能。
新的内置文件过滤器¶
当您将多个过滤器堆叠在一起时,每个过滤器都会显示其中间结果,使您能够追踪每个阶段的过滤流程。
新的内置过滤器简化了非结构化数据集的处理:
- 搜索: 使用正则表达式(regex)或通配符(glob)模式过滤文件,仅预览非结构化数据集中匹配的文件。
在过滤器搜索中选择正则表达式或通配符模式的选项。
- 限制: 限制返回的结果数量。这对于包含大量文件的数据集尤其有用。
为文件搜索设置大小限制过滤器的选项。
- 选择: 手动从非结构化数据集中选择特定文件,以便在预览时重点关注,尤其是在处理转换时。
从非结构化数据集中选择特定文件进行预览的选项。
告诉我们您的想法¶
请告诉我们您在使用 Palantir Visual Studio Code 扩展中的代码定义输入过滤时的体验。通过我们的 Palantir 支持渠道或在我们的开发者社区 ↗中使用 vscode 标签 ↗ 留下反馈。
新的 VS Code Workspaces 登录页面:直接发现 Palantir 扩展和库¶
发布日期:2025-12-09
您的注册环境中现已提供 VS Code Workspaces 中新的自定义登录页面,旨在为新老用户提供更流畅、更直观的入门体验。当您打开一个仓库时,您将看到一个欢迎页面,引导您完成 Palantir 关键库和扩展的交互式演练。
新的 VS Code 登录页面,包含 Palantir 扩展 VS Code、Python 转换和 Continue 演练的标签页。
新增功能¶
- Palantir VS Code 扩展: 了解如何将代码仓库(Code Repositories)的功能无缝集成到您的开发工作流中,无论您是在 Palantir 平台内还是本地 VS Code 中工作。
- Python 转换: 探索用于构建健壮数据处理管道的核心 Python 库,并提供分步指导帮助您快速上手。
- Continue: 快速了解 Continue,这是一个 AI 驱动的开发工具,预配置了相关的 Foundry 工具,可加速您的编码和数据工作流。
新的登录页面取代了默认的 VS Code 演练,提供了量身定制的体验,使发现和使用 AI 辅助编码、数据集预览和侧面板快捷方式等功能变得更加容易。对于团队而言,这意味着更快的入门、更清晰的最佳实践和更高的生产力。
现有用户也将受益于简化的导航和对新功能及文档的快速访问。无论您是新手还是经验丰富的用户,此升级都能帮助您充分利用 Palantir 的开发工具。
您的反馈很重要¶
我们想听听您对 VS Code 扩展的体验,并欢迎您的反馈。通过 Palantir 支持渠道或我们的开发者社区 ↗使用 vscode 标签 ↗ 分享您的想法。
在 Ontology Manager 中近乎实时地监控操作和函数指标¶
发布日期:2025-12-09
随着 Ontology Manager 中操作和函数概览页面引入近乎实时的指标,您现在可以监控成功率、失败率以及新增的 P95 持续时间图表。指标会持续更新,而无需等待长达一天的时间,从而为您提供关于操作和函数性能的更快、更及时的洞察。
新增功能¶
- 近乎实时的成功/失败指标: 即时查看操作和函数的当前状态,使您能够快速识别并处理出现的问题。
- P95 持续时间指标: 跟踪操作和函数的第 95 百分位执行时间,以识别性能瓶颈并优化工作流。
- 持续数据更新: 指标现在持续更新,为调试和可观测性提供当前洞察。
- 链接到运行历史: 访问过去七天内操作或函数执行的完整视图。
Ontology Manager 中新的操作指标仪表板,显示某个操作性能下降。
Ontology Manager 中新的函数指标仪表板,显示 P95 峰值。
为何重要¶
此前,操作和函数指标可能需要长达一天的时间才能更新,从而延迟了故障排除和监控。借助近乎实时的指标,您可以在事件发生时进行调试、监控和优化操作及函数,确保更快的响应时间和更高的可靠性。
我们期待您的反馈¶
我们希望这些增强功能能改善您的调试和可观测性体验。通过 Palantir 支持渠道或我们的开发者社区 ↗分享您的想法。
了解有关监控视图的更多信息以及适用于操作和函数的可用监控功能。
使用新的过滤功能审查检查点记录¶
发布日期:2025-12-09
检查点(Checkpoints)使管理员能够审查并确保对平台中执行的敏感操作有适当的理由。为简化此工作流,我们引入了重新设计的检查点界面,并增强了支持复杂搜索组合的过滤功能。过滤后的视图可以通过 URL 共享和添加书签,使团队能够更高效地协作进行审计工作流并快速访问特定记录。此界面将于 12 月 8 日那周默认启用。
刷新后的检查点界面提供了增强的过滤功能,以支持复杂的搜索组合。
新增功能¶
过滤:
- 过滤侧边栏: 检查点记录过滤器现在位于可折叠的侧边栏中。
- 多选: 除时间外,所有过滤器类型都支持多选(同一过滤器类型中的多个值)。
- 更多组合: 所有过滤器类型可以相互组合使用。
- 共享: 过滤器组合存储在 URL 中,允许用户共享其当前的过滤器视图或为常用过滤器组合添加书签。
表格和详情面板:
- 新界面: 新的现代化界面,提高了可读性。
- 改进的渲染: 某些检查点资源现在在表格和详情面板中包含更具描述性的渲染。
- 改进的性能: 记录及其详情现在加载更快。
后续计划¶
我们目前正在开发通过平台 SDK 检索检查点记录的功能。
我们期待您的反馈!¶
在 Palantir 的开发者社区 ↗论坛中使用 checkpoints 标签 ↗ 或联系 Palantir 支持,分享您对新检查点审查页面的体验和反馈。
Grok-4.1 Fast(推理型)和 Grok-4.1 Fast(非推理型)现可通过 xAI 获取¶
发布日期:2025-12-04
Grok-4.1 Fast 系列模型现已在非地理限制和美国地理限制的注册环境中通过 xAI 提供。
模型概述¶
Grok-4.1 Fast(推理型)↗ 是 xAI 最新的多模态模型,针对最大智能进行了优化,特别适用于高性能的代理工具调用(agentic tool calling)。
Grok-4.1 Fast(非推理型)↗ 是该模型的更快版本,优先考虑快速响应和高智能水平。
两个模型共享以下规格:
- 上下文窗口: 2,000,000 个令牌(token)
- 模态: 文本、图像
- 能力: 工具使用、结构化输出
开始使用¶
要使用这些模型:
- 确认您的注册管理员已启用相关模型系列
- 查看令牌成本和定价
- 查看 AIP 中所有可用模型的完整列表
您的反馈很重要¶
我们想听听您在 Palantir 平台中使用语言模型的体验,并欢迎您的反馈。通过 Palantir 支持渠道或我们的开发者社区 ↗使用 language-model-service 标签 ↗ 分享您的想法。
Claude Opus 4.5 现可通过 Direct Anthropic、Google Vertex、AWS Bedrock 获取¶
发布日期:2025-12-04
Claude Opus 4.5 现已在非地理限制的注册环境中通过 Anthropic、Google Vertex 和 AWS Bedrock 提供。
模型概述¶
Anthropic 的最新模型 Claude Opus 4.5 是涉及编码、代理(agent)和计算机使用工作流中同类最佳的 LLM 之一。Opus 4.5 的价格比之前的 Opus 模型便宜 3 倍,运行效率更高,所需干预更少。有关更多信息,请查看 Anthropic 关于该模型的文档 ↗。
- 上下文窗口: 200,000 个令牌
- 模态: 文本、图像
- 能力: 扩展思考、函数调用
开始使用¶
要使用这些模型:
- 确认您的注册管理员已启用相关模型系列
- 查看令牌成本和定价
- 查看 AIP 中所有可用模型的完整列表
您的反馈很重要¶
我们想听听您在 Palantir 平台中使用语言模型的体验,并欢迎您的反馈。通过 Palantir 支持渠道或我们的开发者社区 ↗使用 language-model-service 标签 ↗ 分享您的想法。
Codex 模型现可通过 Azure OpenAI 和 Direct OpenAI 在 AIP 中使用¶
发布日期:2025-12-04
GPT-5.1 Codex、GPT-5.1 Codex mini、GPT-5 Codex 现已在启用了 Azure OpenAI 和/或 Direct OpenAI 的非地理限制注册环境中提供。
模型概述¶
现在可以使用三个高级 OpenAI 模型:GPT-5-Codex、GPT-5.1-Codex 和 GPT-5.1-Codex mini。这些模型旨在支持广泛的编码、推理和自动化任务,其中 5.1 系列提供了能力和效率方面的最新进展。
GPT-5.1-Codex ↗ 是 OpenAI 最新、功能最强的代理编码模型,针对复杂推理、代码生成和高级自动化任务进行了优化。它非常适合寻求最佳性能和最新功能以满足苛刻应用需求的用户。
GPT-5.1-Codex mini ↗ 是 GPT-5.1-Codex 的一个更小、更具成本效益的变体。它专为需要针对不太复杂的编码和自动化任务提供高效、可扩展解决方案的用户而设计。
GPT-5-Codex ↗ 是一个针对代理编码任务和自动化进行优化的模型。
这三个模型共享以下规格:
- 上下文窗口: 400,000 个令牌
- 最大输出令牌: 128,000 个令牌
- 知识截止日期: 2024 年 9 月 30 日
- 模态: 文本、图像输入;文本输出
- 特性: 结构化输出、流式传输、函数调用
开始使用¶
要使用这些模型:
- 确认您的注册管理员已启用相关模型系列
- 查看令牌成本和定价
- 查看 AIP 中所有可用模型的完整列表
您的反馈很重要¶
我们想听听您在 Palantir 平台中使用语言模型的体验,并欢迎您的反馈。通过 Palantir 支持渠道或我们的开发者社区 ↗使用 language-model-service 标签 ↗ 分享您的想法。
Data Connection 中现已提供源终端¶
发布日期:2025-12-02
源终端(Source terminal)是一个新工具,用于帮助调试使用网络出口策略的源的连接问题。您可以在一个与源具有相同网络访问权限的终端中运行命令,从而允许您使用 dig、curl、netcat 和 openssl 等命令测试与外部系统的连接。
使用方法¶
要从 Data Connection 访问终端,请在连接详情下的网络连接面板中选择调试。
源终端可通过连接设置标签页访问。
使用此功能可显著提高常见网络问题的调试速度和体验:DNS 解析失败、因缺少证书导致的 SSL 握手失败以及防火墙阻止的流量。
您的反馈很重要¶
随着我们继续添加 Data Connection 功能,我们想听听您的体验并欢迎您的反馈。通过 Palantir 支持渠道或我们的开发者社区 ↗分享您的想法,或使用我们的 data-connection 标签 ↗ 发帖。
Pipeline Builder 中的更快管道现已正式发布¶
发布日期:2025-12-02
此前在测试版中被称为轻量级管道,在 Pipeline Builder 中创建的更快管道显著提高了构建在各种规模数据集上的批量和增量管道的执行速度。此更快管道选项现已在 Foundry 注册环境中正式发布。
在 Pipeline Builder 中创建新管道时,您可以配置更快管道。
什么是更快的批量管道?¶
由用 Rust ↗ 编写的开源查询引擎 DataFusion ↗ 提供支持,与传统基于 Spark 的管道相比,更快的管道可以显著加速计算过程,同时支持快速、低延迟的执行。
何时使用更快的管道¶
通常运行时间在 15 分钟以内的管道将从转换为更快管道中获益最多,尽管运行时间更长或在大规模数据集上运行的构建也可能体验到执行时间和计算资源使用的减少。Pipeline Builder 使您能够随时通过设置菜单在标准批量管道和更快管道之间无缝转换,因此您可以尝试不同的管道类型以优化工作流的性能。
将现有的标准批量管道转换为更快管道时,如果管道包含不兼容的转换或表达式,Pipeline Builder 会向您发出警告。
使用设置菜单转换现有管道并查看需要解决的不兼容转换或表达式。
在您打开显示管道转换检查后,屏幕底部的管道警告面板中会出现一个更快转换兼容性检查部分。
此部分列出了更快管道不支持的转换和表达式。您可以通过选择转到节点图标快速定位包含不受支持转换的节点。
管道警告面板显示不兼容的转换。
如何构建和使用更快的管道¶
查看现有文档以构建更快的管道或转换现有的标准管道。
通过 Compass 文件系统中的项目管理本体资源权限¶
发布日期:2025-12-02
本体资源(对象类型、链接类型、操作类型、共享属性和接口)现在可以在支持的注册环境中与 Compass 文件系统集成,这些资源作为文件出现在项目中,与 Workshop 应用程序和数据集等其他资源并列。您可以将本体资源组织到文件夹中、应用标签、将其添加到项目目录,并使用相同的熟悉 Compass 项目角色进行权限管理。这种统一的方法目前处于测试阶段,取代了之前的本体权限模型:本体角色和数据源派生权限。要使用此功能,本体所有者必须首先在 Ontology Manager 中启用此功能 — 请查看下面的如何启用部分了解详情。
当此功能开启时,新的本体资源将通过 Compass 文件系统中的项目进行权限管理。
新权限模型如何工作的示例¶
例如,考虑一个名为 Building 的对象类型,现在作为文件保存在项目 A 中。您查看、编辑或管理 Building 的能力取决于您在项目 A 中的角色。如果您是项目 A 的编辑者,您可以编辑 Building 对象类型。
要查看特定的 Building 对象(如 Empire State Building),您需要同时拥有对象类型及其数据源的 Viewer 角色。如果您只有对象类型的查看权限,则只能看到模式(schema)和联系信息等信息,而无法看到实际数据。如果您需要帮助理解所需的权限,请查看 Compass 项目侧面板以获取更多详细信息。
这种方法通过允许所有资源类型作为项目资源进行管理,使在 Palantir 平台中管理权限变得更加容易,使您能够在文件系统中对整个工作流进行权限管理。
如何启用¶
要将新的本体资源默认保存到项目中,本体所有者可以导航到 Ontology Manager 中的本体配置标签页,并打开要求新的本体资源保存在项目中。启用后,在创建新的本体资源时,系统会提示您选择保存位置。开启此功能不会影响现有的本体资源。
要迁移现有的本体资源,请使用 Ontology Manager 的本体配置标签页中的迁移助手,它会为每个资源建议文件系统位置。如果您是资源的 Owner 并且至少是所选项目的 Editor,则可以迁移该资源。了解有关使用迁移助手迁移现有本体资源的更多信息。
限制¶
此功能不适用于默认本体或基于分类的访问控制。
我们期待您的反馈¶
随着我们继续开发本体的新功能,我们欢迎您的反馈。通过 Palantir 支持渠道或我们的开发者社区 ↗分享您的想法,并使用 ontology-management 标签 ↗。
使用工作流沿袭可视化和管理工作流¶
发布日期:2025-12-02
使用工作流沿袭(Workflow Lineage)(以前称为 Workflow Builder)轻松跟踪和更新工作流资源及关系。现已正式发布,工作流沿袭能够更好地管理为您的应用程序提供支持资源的资源,其功能涵盖 AI 模型可见性、批量更新资源和用户权限以及 Marketplace 打包协助。
工作流沿袭的图形和应用程序视图。
工作流沿袭登录页面显示 Workshop 模块,可快速启动沿袭图。
开始使用¶
使用 Cmd + I(macOS)或 Ctrl + I(Windows)自动生成描述相关对象、操作和函数的工作流沿袭图。或者,打开现有的数据沿袭图,然后选择右上角的工作流沿袭以打开相应的图形。
从数据沿袭应用程序标题创建工作流沿袭图的选项。
简化您的工作流管理¶
您可以使用工作流沿袭批量更改和更新资源中的版本和条件:
- 保持工作流最新,使用函数支持的操作、Workshop 模块中的函数和逻辑的批量更新功能。使用过时的依赖项颜色模式选择要更新的节点,然后从底部面板选择批量更新。
底部升级面板允许您一次升级所有函数版本。
- 管理资源,使用批量删除对象类型和批量发布 Workshop 模块的工具。右键单击选定的节点以执行批量操作。
在选定节点上右键单击菜单以应用批量操作。
- 跟踪属性使用情况,跨属性和资源的所有下游使用情况,包括对象类型、自动化、函数、Workshop 模块和操作。选择一个对象并使用左侧的选择详情面板查看属性及其使用情况。
选择详情侧面板在一个易于查看的视图中显示下游属性使用情况。
跟踪 AI 使用情况和性能¶
可视化和监控令牌及模型使用情况,包含详细的成功与速率限制细分,以及显示随时间变化的使用趋势的综合图表。
右上角的模型使用颜色图例和底部面板中的模型使用图表提供了不同的视图来了解令牌和模型利用率随时间变化的趋势
观察用户权限¶
批量更新多个操作的提交条件,并轻松找到具有匹配条件的操作以加快权限管理。使用颜色模式和批量升级功能管理和对齐提交条件。
工作流沿袭图中可批量更新的操作提交条件视图。
监控运行历史和操作日志¶
在底部面板中查看运行历史和操作指标,以帮助调试和定位更改。
选定操作节点的运行历史。
选定操作节点的指标。
打包到 Marketplace¶
检查产品中使用的资源,并查看重叠和依赖关系。您可以将工作流图打包在一起,并在图中可视化您的 Marketplace 打包资源及其连接。
打包的 Marketplace 产品的图形,显示所有连接的资源。
分享您的想法,并加入我们的 AMA!¶
我们正在与工作流沿袭团队举办一场 AMA 会议,分享幕后发生的事情并听取您的体验。此 AMA 将在我们的开发者社区论坛 ↗中异步进行,时间为12 月 1 日星期一至 12 月 16 日星期二,工作流沿袭团队成员将每天监控此主题并回复您的问题和评论。
我们也欢迎您通过我们的 Palantir 支持渠道提供反馈,您可以在我们的开发者社区 ↗中使用 workflow-lineage 标签 ↗ 发帖。
GPT-5.1 现可通过 Azure OpenAI、Direct OpenAI 在非地理限制注册环境中获取¶
发布日期:2025-12-01
GPT-5.1 现已在非地理限制的注册环境中通过 Azure OpenAI 和 Direct OpenAI 提供。
模型概述¶
GPT-5.1 通过根据任务的复杂性动态调整模型思考所花费的时间来平衡智能和速度。它还具有"无推理"模式,可以在不需要深度思考的任务上更快地响应。有关更多信息,请查看 OpenAI 关于该模型的文档 ↗ 及其 GPT-5.1 提示指南 ↗。
- 上下文窗口: 400,000 个令牌
- 模态: 文本、图像
- 能力: 结构化输出、函数调用、推理努力
开始使用¶
要使用这些模型:
- 确认您的注册管理员已启用相关模型系列
- 查看令牌成本和定价
- 查看 AIP 中所有可用模型的完整列表
您的反馈很重要¶
我们想听听您在 Palantir 平台中使用语言模型的体验,并欢迎您的反馈。通过 Palantir 支持渠道或我们的开发者社区 ↗使用 language-model-service 标签 ↗ 分享您的想法。