SAP (Custom source)(SAP(自定义源))¶
The SAP (Custom source) connector allows you to connect Foundry to SAP systems using a manually configured source with the magritte-sap-source connector type. This connector uses a custom YAML-based setup rather than the guided configuration available in newer SAP connectors.
:::callout{theme="warning"} New SAP integrations should use the SAP ERP or SAP SLT connectors. These connectors use a newer, more performant API to read data from SAP and provide a guided setup experience. The SAP (Custom source) connector is intended for existing integrations set up before those connector types were available.
Using the SAP (Custom source) connector requires the installation of the Palantir Foundry Connector 2.0 for SAP Applications add-on on the target SAP application layer. :::
Supported capabilities¶
| Capability | Status |
|---|---|
| Exploration | 🟢 Generally available |
| Batch syncs | 🟢 Generally available |
| Incremental | 🟢 Generally available |
| Streaming syncs | 🟡 Beta |
| Webhooks | 🟢 Generally available |
Setup¶
-
Open the Data Connection application and select + New Source in the upper right corner of the screen.
-
Select Add Custom Source.
-
Give the source a name and location.
-
In the custom YAML section, enter the source definition:
type: magritte-sap-source
url: https://<host>:<port>/sap/palantir
usernamePassword: <username>:{{password}}
<host>is the hostname of the SAP application server.<port>is the HTTPS (or HTTP) port for the Internet Communication Manager (ICM).- The username and password are those of the technical user created for Foundry when installing the Connector.
:::callout{theme="warning"}
Enter {{password}} exactly as shown. After saving, enter the password value under Encrypted values on the right side of the dialog.
:::
- Select Save.
Learn more about setting up a connector in Foundry.
Enable streaming syncs (SLT only)¶
To support streaming syncs, the source must be configured with an explicit SLT connection type. Add the connectionType parameter to the source YAML:
type: magritte-sap-source
url: https://<host>:<port>/sap/palantir
usernamePassword: <username>:{{password}}
connectionType:
type: slt
slt:
context: <context>
The context value is the unique identifier of the RFC connection between the SLT Replication Server and the source ERP system. Learn more about configuring SLT.
Source configuration¶
The following parameters can be configured on the source.
| Parameter | Required | Default | Description |
|---|---|---|---|
url |
Yes | Base URL of the SAP add-on service endpoint. | |
usernamePassword |
Yes | Username and password of the technical user created for Foundry. | |
useKernelJsonSerialization |
No | false |
Use kernel JSON serialization for paginated data. Incompatible with useTsvFormat: true. |
useTsvFormat |
No | false |
Use TSV format for paginated data instead of JSON. |
output |
No | 50,000 rows | Maximum Parquet file size (rows or bytes) per request. Can also be overridden per sync. |
convertDatesToStrings |
No | false |
Ingest all dates as strings for all syncs under this source. |
proxy |
No | None | Proxy configuration for connecting to SAP. |
cacheConfigurations |
No | None | Cache timeout configuration per SAP object type. |
Networking and connectivity¶
Make sure to properly configure egress policies to allow Foundry to reach the SAP system. For on-premises SAP environments, agent proxy policies are typically required to route traffic correctly.
Many SAP systems use custom-signed certificates, which can cause SSL handshake exceptions when configuring the connection for the first time. Make sure you have the correct custom certificates from your system and add them to the source.
Source exploration¶
Once the source has been created, use the SAP Source Explorer for interactive exploration.
- Navigate to the source and select Explore and create syncs.
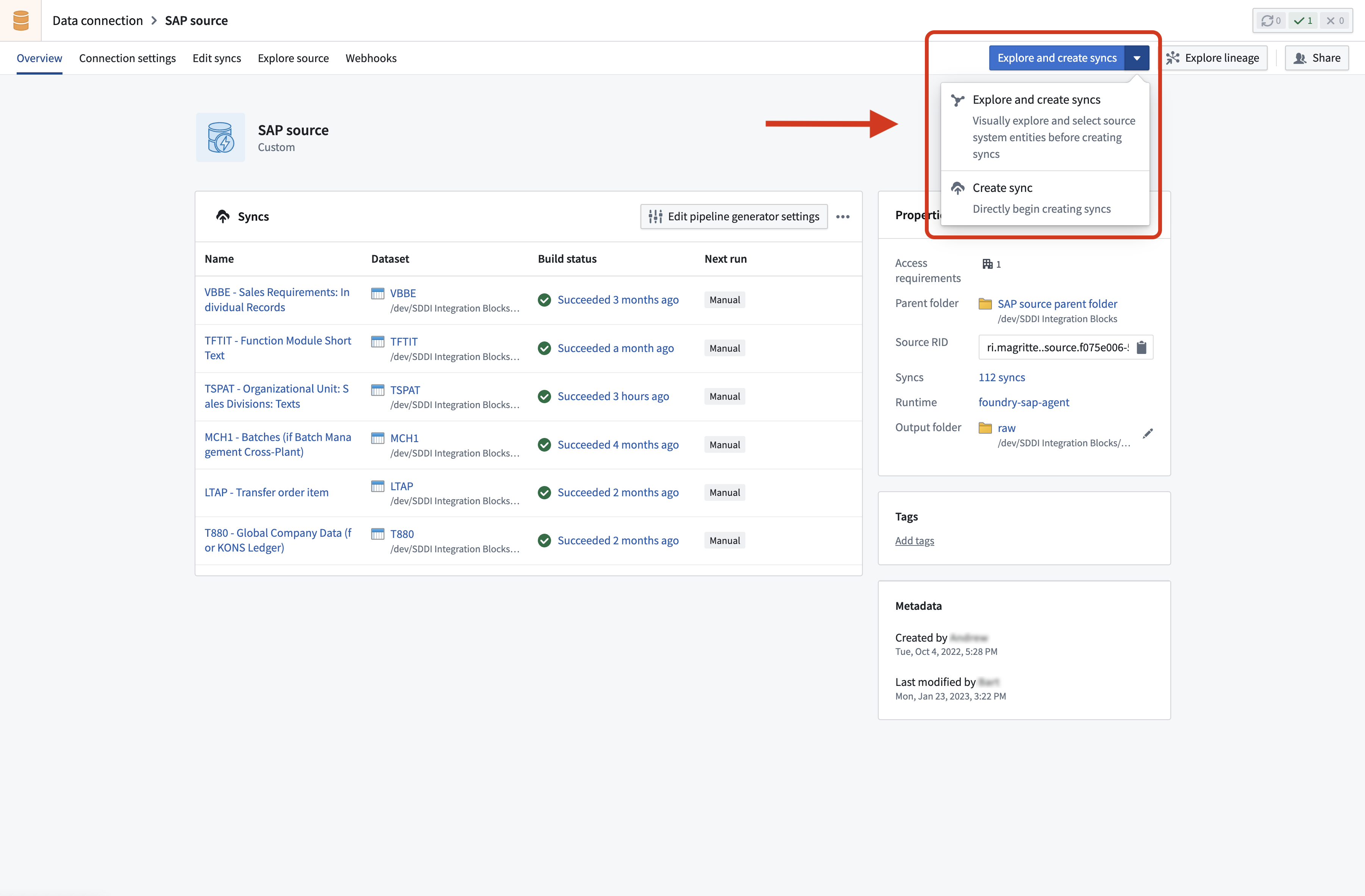
- For remote and SLT connections, select the appropriate context.
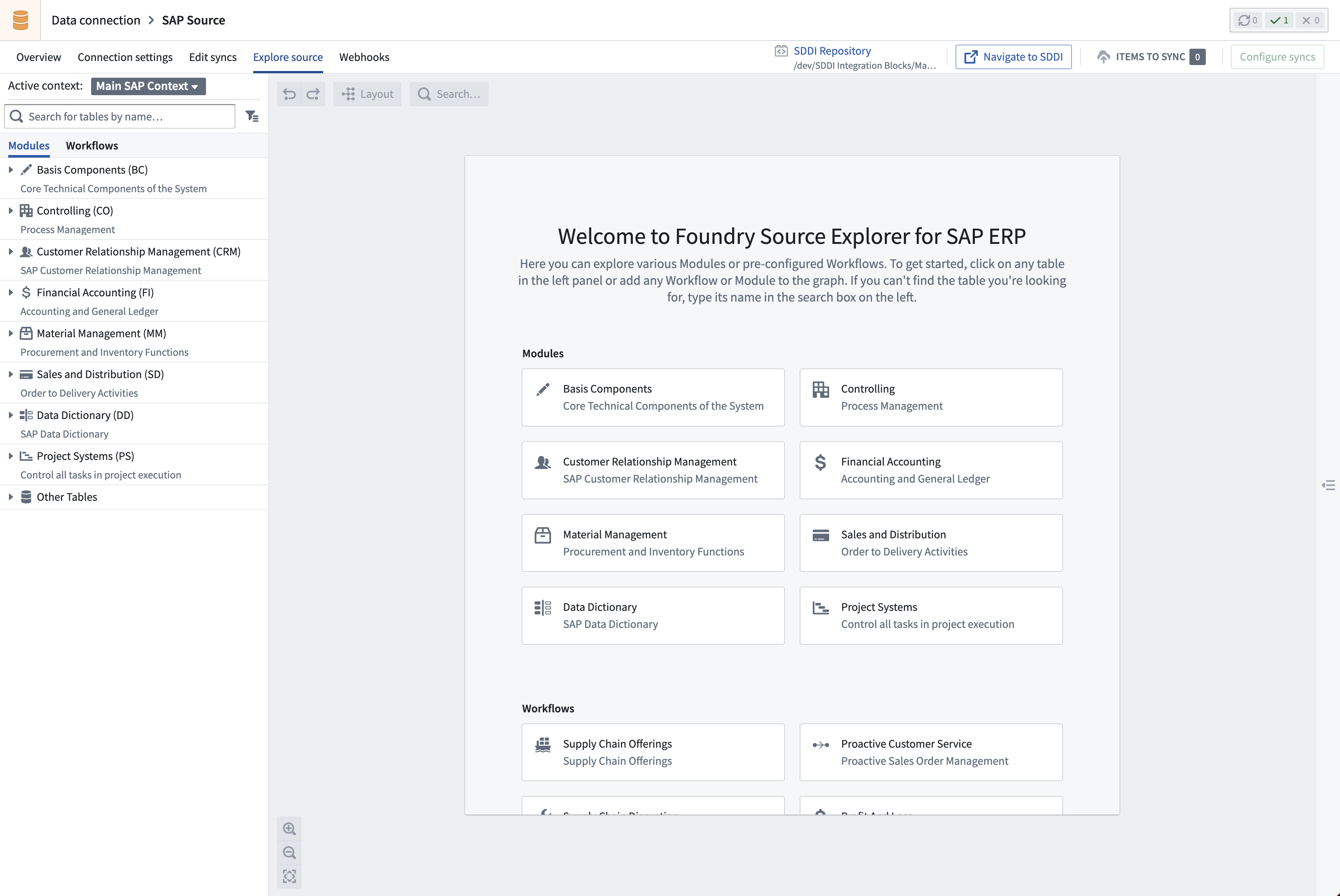
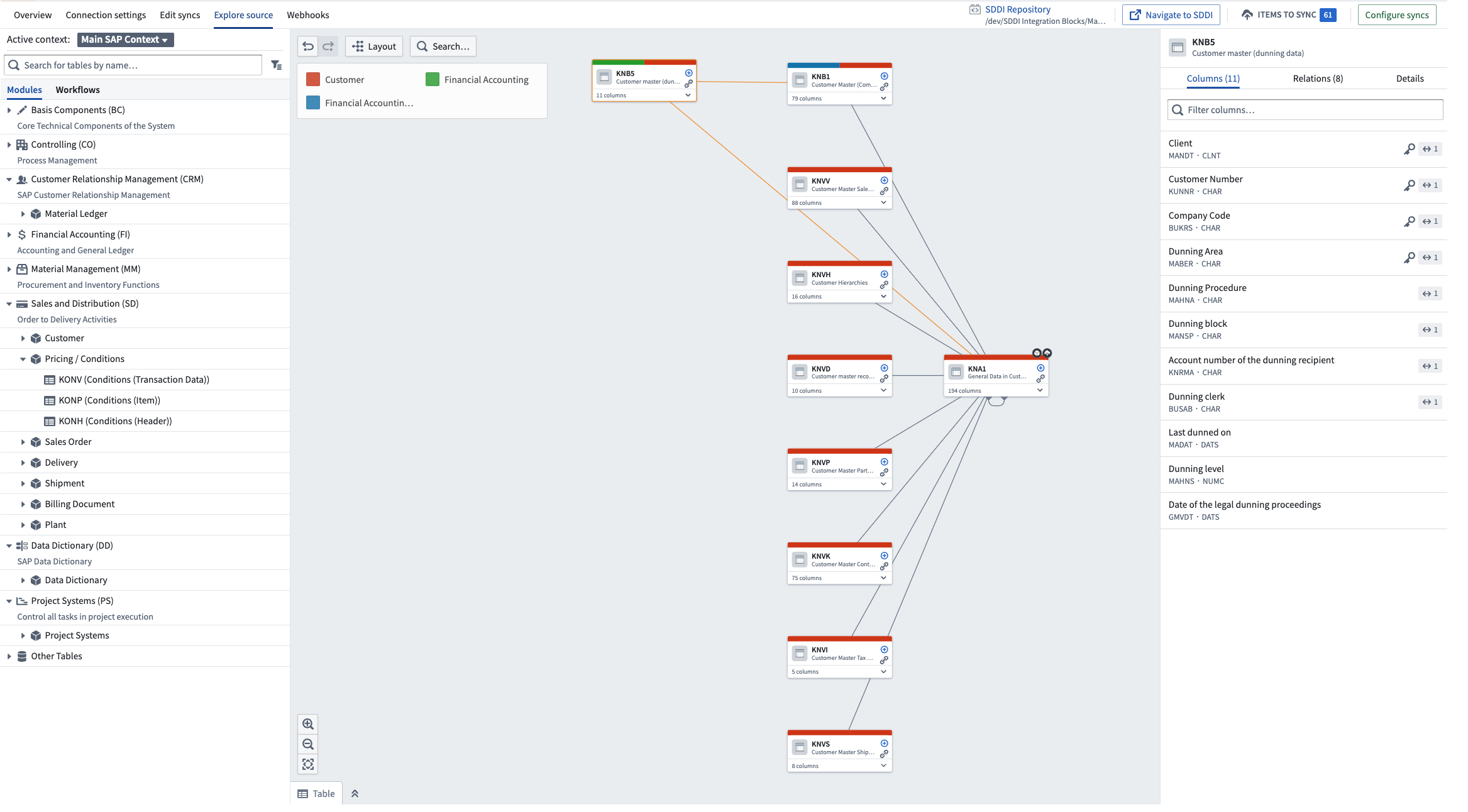
- Select the tables or modules of interest and add them to the graph.
Batch syncs¶
Create a sync¶
Create a sync for each SAP object you want to extract to Foundry.
:::callout{theme="neutral"} The sync configuration UI has two modes: Basic and Advanced. The Advanced tab exposes the full sync definition as YAML and is required for some object types and configuration parameters documented below. You can switch back to the Basic view, but any YAML properties that have no UI equivalent will not be displayed and will be lost. :::
- From the source overview page, select + New next to batch sync.
- Configure the standard settings: name, target dataset, and schedule.
- Set Transaction type to one of the following options:
- APPEND — for incremental updates. See Incremental syncs for details.
- SNAPSHOT — for a full load.
- Select an SAP object type (see SAP object types below).
- If using SLT or connecting to a remote system, select a Context. See Install a remote agent for details on contexts.
- Enter the Object name. As you type, the field suggests matching objects based on the selected SAP object type.
- If configuring an incremental sync, provide an Incremental field.
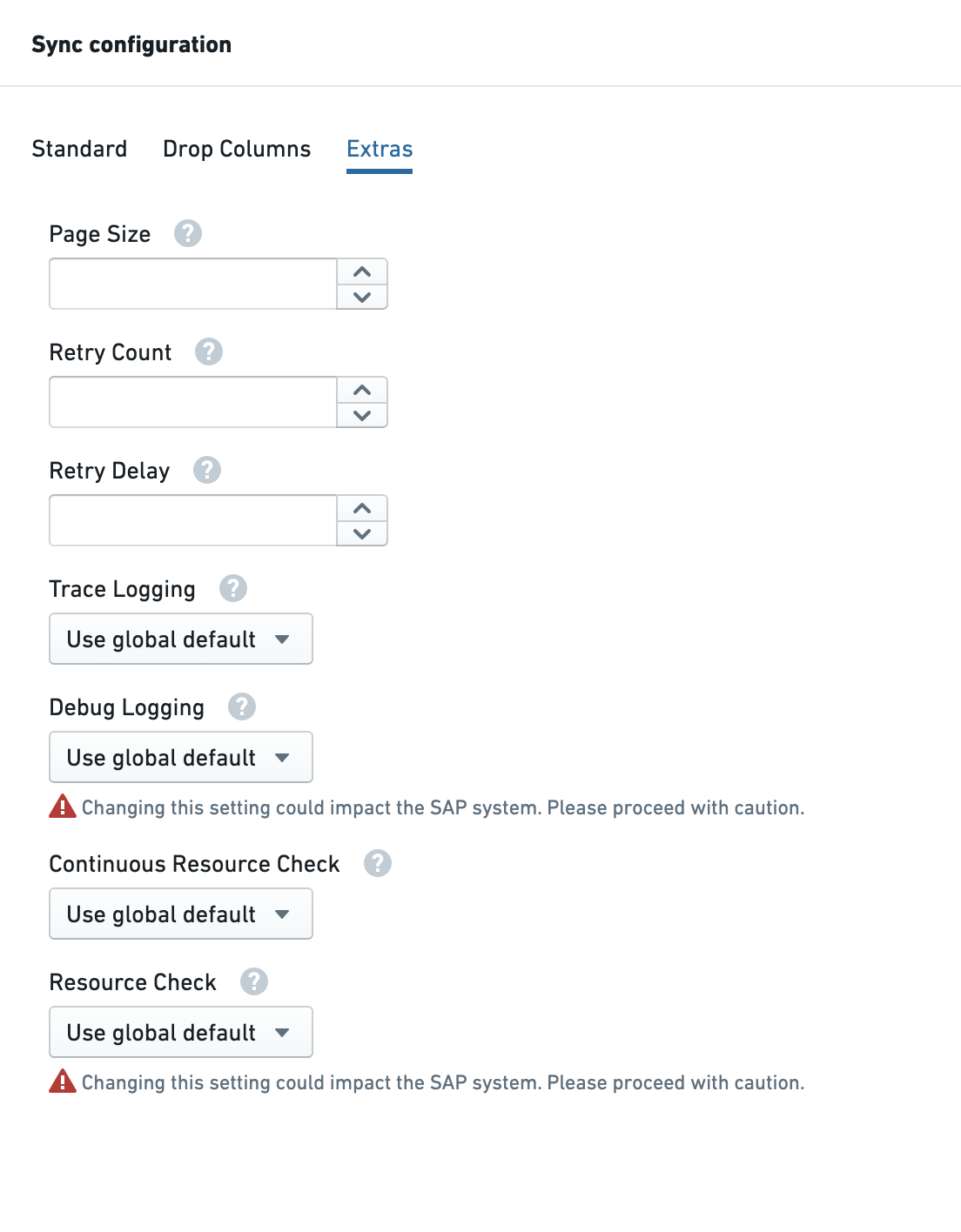
- Optionally, configure additional parameters in the Extras tab.
SAP object types¶
The following object types are available from the SAP object type dropdown in the sync configuration UI.
| Object type | Description |
|---|---|
| ERP Table | Extracts data from any ERP table or view in the SAP ABAP data dictionary, including custom Z* tables. |
| BW InfoProvider | Extracts data from a BW InfoProvider (InfoCube, DataStore object, or MultiProvider). All SAP BW authorization concepts are inherited. |
| BW BEx Query | Runs a BEx query in a BW system. See BEx query configuration below. |
| SLT | Extracts data from an SLT Operational Delta Queue (ODQ). SLT is a trigger-based replication tool with a built-in CDC mechanism. Requires a Context. |
| BW Content Extractor | Runs an ERP Business Content extractor — ready-to-use structures with built-in business logic and CDC mechanisms. Use APPEND for extractors that support delta extraction. See Configure extractors. |
| Function | Runs a remote-enabled function or BAPI in an ERP or BW system. See Function configuration below. |
| ERP Table Data Model | Reads the relationships between ERP tables based on a primary key/foreign key model. Use the depth parameter to control how many levels of relationships to follow. |
| Remote ERP Table | Extracts data from an ERP table in a remote ERP system. Requires a Context to identify the remote system. |
| Remote BW InfoProvider | Extracts data from a BW InfoProvider in a remote BW system. Requires a Context. |
| Remote BW BEx Query | Runs a BEx query in a remote BW system. Requires a Context. |
| Remote Function | Runs a remote-enabled function in a remote ERP or BW system. Requires a Context. |
| Transaction codes | Extracts data from SAP reports using ABAP List Viewer (ALV). Advanced tab only. |
| HANA views | Extracts data from HANA Views enabled in the SAP application layer. Advanced tab only. |
| CDS views | Extracts data from ABAP CDS (Core Data Services) Views. Advanced tab only. |
Remote object types require a Context value that identifies the remote system. Learn more about remote connections.
BEx query configuration¶
BEx is a multidimensional query framework built on SAP BW InfoProviders. BEx queries use standard SAP BW access methods and inherit all SAP BW authorization concepts. They represent business logic applied to InfoProvider views.
:::callout{theme="neutral"} If the BEx query has dynamic columns (a characteristic on columns with key figures such that every key figure is repeated along with the characteristic value), this creates a dynamic output. Dynamic columns are not supported by Foundry — adjust your query accordingly. :::
When you select BW BEx Query as the object type, the sync editor shows a dedicated BEx query builder with the following options:
| Option | Description |
|---|---|
| Use Technical Names | Toggles between technical and human-readable (language-dependent) column names. |
| Drop columns | Removes key characteristics from the output. |
| Free characteristics | Adds free characteristics (as defined in the BEx query) to the output. |
| Filter | Filters data after the query is run (post-query filter). |
| BEx Query Input Variables | Provides filter values for BEx query input variables. |
For BEx paging configuration, see Advanced YAML parameters in the sync parameters section.
Function configuration¶
SAP function modules can both extract data from and write data back to an SAP system. The Connector can only extract data from functions that have at least one tabular output parameter.
:::callout{theme="neutral"} The Foundry technical user requires the following authorization roles to extract function results:
/PALANTIR/SERVICE_USER/PALANTIR/CONTENT_FUNCTION_ALL- Any authorization role or object required to run the specific function :::
If a function returns more than one output parameter, use the paramName parameter to specify which output to write to the Foundry dataset:
type: magritte-sap-source-adapter
sapType: function
obj: BAPI_USER_GETLIST
paramName: USERLIST
Input parameters can be configured using inputParams. Three value types are supported:
| Type | YAML syntax |
|---|---|
| Single value | PARAM_NAME: 'value' |
| Structure (dictionary) | PARAM_NAME: '{"FIELD1": "value1", "FIELD2": "value2"}' |
| Table (list of dictionaries) | PARAM_NAME: '[{"FIELD1": "value1"}, {"FIELD1": "value2"}]' |
Example with a table-type input parameter:
type: magritte-sap-source-adapter
sapType: function
obj: EM_GET_NUMBER_OF_ENTRIES
inputParams:
IT_TABLES: '[{"TABNAME":"TSTC"}]'
paramName: IT_TABLES
Advanced-only object types¶
The following object types are not available from the dropdown and must be configured from the Advanced tab.
Transaction codes¶
Extracts data generated by SAP reports. Only reports using ABAP List Viewer (ALV) are supported.
By transaction code name:
type: magritte-sap-source-adapter
sapType: tcode
obj: ZTEST_ALV
By program name:
type: magritte-sap-source-adapter
sapType: tcode
obj: RSUSR200
programType: program
The following optional parameters can be added to the sync YAML:
| Parameter | Description |
|---|---|
filter |
Passes user inputs for selection screen variables. Does not filter output fields arbitrarily. |
selectionVariant |
Passes a predefined selection screen variant. If combined with filter, the filter values overwrite matching variant values. |
outputVariant |
Passes the layout name of the program. Only supported for programs with a layout parameter defined on SAP's selection screen. |
ingestionType: spool |
Sends the report output to a printer queue before ingesting. Recommended for large reports that exceed SAP's internal table limits. When set, all columns are ingested as type String. |
HANA views¶
Extracts data from HANA Views enabled in the SAP application layer. See Ingest HANA views from SAP for prerequisites.
type: magritte-sap-source-adapter
sapType: hanaview
obj: ZEXT_SBOOK
CDS views¶
Extracts data from ABAP CDS (Core Data Services) Views. ABAP CDS defines semantic data models on the central database of the application server.
:::callout{theme="neutral"} Extracting data from parametrized CDS views is not currently supported. :::
Incremental syncs¶
Incremental syncs are stateful syncs that enable append-style transactions from the same table. To enable incremental syncs, set Transaction type to APPEND.
The following incremental types are available:
| Incremental type | Description |
|---|---|
| Single field | Imports rows where a single field is greater than or equal to the largest value already imported. |
| Multiple fields | Same as single field but combines multiple fields with an OR operator. Useful when both "created" and "last updated" timestamp fields exist. Separate fields with a comma. |
| Concatenate fields | Same as multiple fields but concatenates fields together rather than combining with OR. Useful when separate "last updated date" and "last updated time" fields exist. |
| Use change document table | Imports rows based on updates in SAP's change document tables (CDHDR and CDPOS). Useful when the target table lacks a monotonically increasing field. Note that inserts may not be captured for some objects. |
| Use twin or twinjoin table | Imports rows from the target table when a field in a separate "twin" table meets the incremental condition. A twinjoin table allows the target to be a join of multiple tables. |
The table below shows which incremental types are supported per object type:
| Object type | Single field | Multiple fields | Concatenate fields | Change document table | Twin table | SAP built-in | Replication | Request based |
|---|---|---|---|---|---|---|---|---|
| Table | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||
| Remote Table | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||
| InfoProvider | ✓ | ✓ | ✓ | |||||
| Remote InfoProvider | ✓ | ✓ | ✓ | |||||
| SLT | ✓ | |||||||
| Extractor | ✓ |
:::callout{theme="neutral"} Incremental updates are not supported for BEx queries or Functions. All syncs for these object types are full extracts. :::
The incremental field should ideally be a monotonically increasing value. The system uses a "greater than or equal to" comparison to avoid missing data if a sync runs midway through a given date. As a result, duplicate values may appear in the Foundry dataset and should be removed as a first step in the transformation pipeline.
Twin table configuration¶
The Incremental Twin Table setting specifies the twin table. The Incremental Twin Mapping setting defines the join conditions between the primary and twin tables.
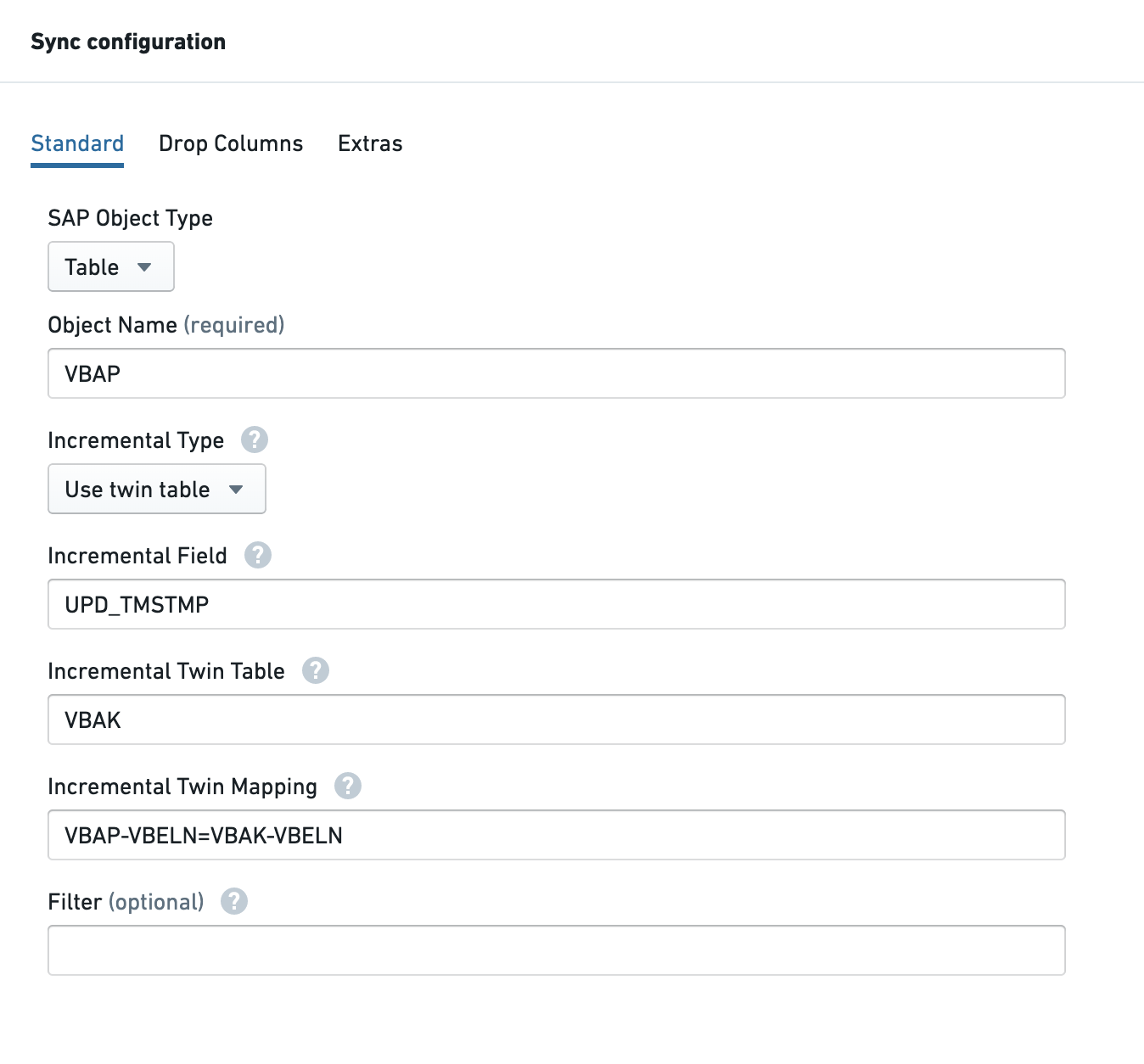
Mapping syntax:
{PRIMARY_TABLE_NAME}-{FIELD_NAME}={TWIN_TABLE_NAME}-{FIELD_NAME}
Multiple join conditions can be combined with a semicolon (AND operator).
Request-based incremental for InfoProviders¶
In SAP BW, DSOs and InfoCubes are loaded using Data Transfer Processes (DTPs). Each DTP creates a loading request, and the Connector uses these requests to capture changed data.
:::callout{theme="warning"} This feature is only supported for non-compressed requests. Requests must not be compressed before loading to Foundry. If a request is compressed before loading, the sync will fail and the initial load must be repeated. :::
Configure via the Advanced tab:
type: magritte-sap-source-adapter
sapType: infoprovider
obj: <technical-name-of-infoprovider>
incrementalType: REQUEST
Reset incremental state¶
To force a full reload and re-initialize incremental ingest:
- Switch to the Advanced tab in the sync configuration.
- Add
resetIncrementalState: trueto the YAML. - Set the transaction type to SNAPSHOT (keep any
incremental*parameters in place). - Run the sync. This performs a full snapshot, replacing all files in the dataset.
- Remove
resetIncrementalState: truefrom the YAML. - Set the transaction type back to APPEND.
Subsequent syncs will resume incremental appends as normal.
Sync parameters¶
The following parameters are available in the Extras tab or via the Advanced YAML view.
General parameters¶
| Parameter | Applicable to | Description |
|---|---|---|
| Drop columns | ERP Table, Remote ERP Table | Excludes selected columns before extraction. Improves performance and prevents ingestion of sensitive or unnecessary fields. |
| Timestamp | All | Adds /PALANTIR/TIMESTAMP (sync run time) and /PALANTIR/ROWNO (record order within a sync) columns. Useful for deduplicating records downstream. /PALANTIR/ROWNO is only meaningful when using SLT or CDPOS/CDHDR incremental mode — a higher value indicates a more recent change. |
| Page size | All | Rows returned per page. Default is 50,000. Values below the default have no effect; reducing the default requires a system call to the SAP add-on. |
| Retry count | All | Number of retries when a request fails due to a resource shortage. |
| Retry delay | All | Delay in seconds between retry attempts. |
| Param name | Function | Selects which output table to write to the Foundry dataset when a function returns multiple output parameters. |
| Depth | ERP Table Data Model | Number of relationship levels to follow. Use 1 for first-order, 2 for second-order, and so on. |
| Trace logging | All | Set to On to enable trace logging for this sync. |
| Fetch option | SLT | XML fetches using zipped data (faster). Direct fetches as a string. Use Direct if you encounter data content errors with XML. |
| Debug logging | All | Enables debug logging. Starts a background process in SAP for the sync duration — can drain resources. Use with caution. |
| Continuous resource check | All | Controls whether all paging requests or only the initial request are subject to a resource check. |
| Resource check | All | Disabling removes all resource checks. Can put excess load on SAP. Use with caution. |
| Filter | All | Filters extracted data using SAP field values and operators. Supports dynamic filter keywords. |
| Advanced YAML parameters | Varies | maxRowsPerSync, bexSettings, ignoreUnexpectedValues, outputSettingsOverride. |
Debug logging¶
:::callout{theme="danger"} Debug logging starts a background process in the SAP system that runs during the sync. This can drain resources and impact other users. Use with caution. :::
Set to On to enable debug logging for this sync.
Continuous resource check¶
When On, all paging requests are subject to a resource check (memory, CPU). When Off, only the initial page request is checked. See performance parameters for details.
Resource check¶
:::callout{theme="danger"} Disabling the resource check causes syncs to run regardless of available memory, CPU, and processes. This can put excess load on the SAP system. Use with caution. :::
Set to Off to disable all resource checks for this sync.
Filter¶
Filters the data extracted from SAP. All field names must match the data dictionary.
| Operator | Meaning |
|---|---|
, |
OR |
; |
AND |
: |
Between |
= |
Equals |
!= |
Not equals |
>, >=, <, <= |
Comparison |
* |
Wildcard |
Examples:
- Price between 500 and 650:
PRICE=500:650 - Customer A, B, or C:
CUSTOMER=A,B,C - Price between 500 and 650 AND customer A, B, or C:
PRICE=500:650;CUSTOMER=A,B,C - Material starting with PAL, DIS, or SAP:
MATERIAL=PAL*,DIS*,SAP* - Date on or after 9 August 2019 (format YYYYMMDD):
DATE>=20190809
Dynamic filters¶
Dynamic filters use special keywords and functions to create more flexible filter expressions. Available from add-on version SP26 and later.
Fixed keywords
| Keyword | Description |
|---|---|
[CURRENTYEAR] |
Current year in YYYY format. |
[TODAY] |
Today's date in YYYYMMDD format. |
[LASTDAYOFMONTH] |
Last day of the current month in YYYYMMDD format. |
[LASTDAYOFLASTMONTH] |
Last day of the previous month in YYYYMMDD format. |
[FIRSTDAYOFMONTH] |
First day of the current month in YYYYMMDD format. |
[FIRSTDAYOFLASTMONTH] |
First day of the previous month in YYYYMMDD format. |
Date calculation functions
| Function | Description |
|---|---|
[ADDDAY] |
Adds days to the selected date. Example: [ADDDAY(22102022,1)] → 23102022. |
[ADDMONTH] |
Adds months to the selected date. |
[ADDYEAR] |
Adds years to the selected date. |
[GETMONTH] |
Returns the month of the selected date as a 2-digit value (01–12). |
[GETDAY] |
Returns the day of the month as a 2-digit value. |
[GETYEAR] |
Returns the year of the selected date. |
Functions can be used directly with fixed keywords or nested:
- Single function:
[ADDDAY([TODAY], 1)] - Nested:
[GETDAY([ADDDAY([FIRSTDAYOFMONTH], -1)])]
Examples:
- Records after today:
BUDAT>[TODAY] - Records after the last day of the previous month:
BUDAT>[ADDDAY([FIRSTDAYOFMONTH], -1)]
Advanced YAML parameters¶
The following parameters require the Advanced tab and have no Basic view equivalent.
maxRowsPerSync(SLT only): Limits the number of rows returned per sync run (approximate). Useful for splitting the initial sync of a very large table into smaller runs:
maxRowsPerSync: 500000
bexSettings(BEx only): Configures BEx query paging. Available from Connector version SP22 onward:
bexSettings:
bexPaging: true
bexMemberLimit: 10
bexPaging: Enables paging using automatically generated filters. Default isfalse.bexMemberLimit: Threshold for filter candidate selection. InfoObjects with more members than this value are excluded from filter generation. Default is200. Minimum is2.
-ignoreUnexpectedValues: If a sync fails with Unexpected value encountered in SAP data Failed to parse value XXX in field YYY, a date or number value cannot be parsed. To continue syncing and set unparsable values to null:
ignoreUnexpectedValues: true
A warning is logged at the end of the sync with a summary of parse exceptions.
:::callout{theme="warning"} This setting has no Basic view equivalent. If you switch back to the Basic view, this setting will be lost. :::
-outputSettingsOverride: Overrides the source-level Parquet file size setting for a specific sync:
outputSettingsOverride:
maxFileSize:
type: rows
rows:
max: 10000
outputSettingsOverride:
maxFileSize:
type: bytes
bytes:
approximateMax: 400MB
:::callout{theme="warning"} Specifying a maximum size in bytes is approximate — the resulting file sizes may be slightly smaller or larger. The byte value must be at least twice the in-memory buffer size of the Parquet writer, which defaults to 128 MB. :::
Streaming syncs¶
:::callout{theme="neutral" title="Beta"} Streaming syncs from SAP are in the beta phase of development and may not be available on your enrollment. Functionality may change during active development. :::
Streaming syncs are only supported for connections via an SAP SLT Replication Server and require a source configured with an explicit SLT connection type (see Enable streaming syncs above).
Each streaming sync creates and subscribes to its own Operational Delta Queue (ODQ) in the SLT Replication Server. Foundry polls the queue periodically (default interval: 1 second):
- If the queue is empty, no further requests are made until the next poll.
- If there are 50,000 records or fewer on the queue, they are consumed synchronously.
- If there are more than 50,000 records, consumption is paginated.
For lowest latency, the SLT Replication Server should have at least as many available dialog work processes as there are active streaming syncs.
Create a streaming sync¶
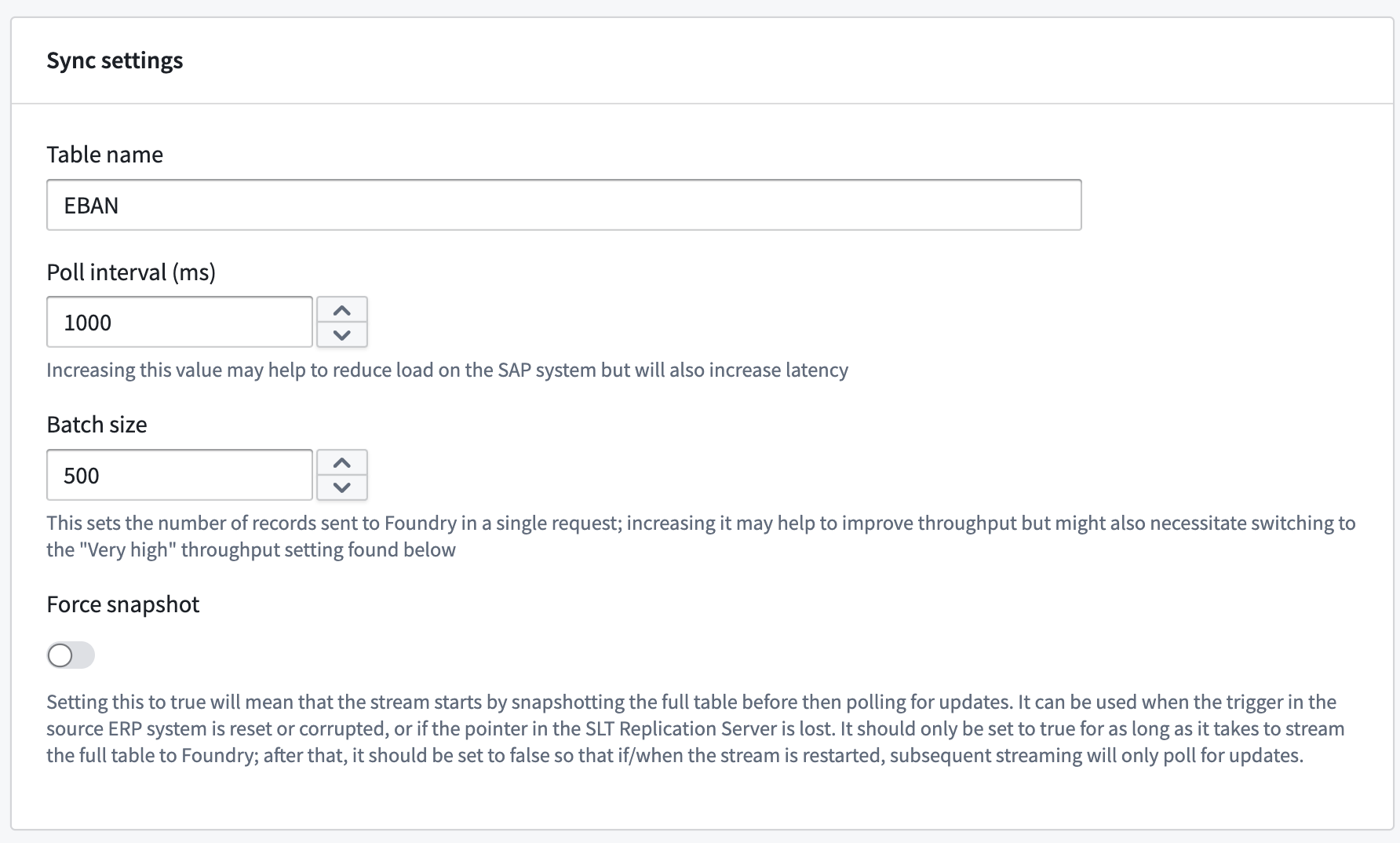
- Open the SAP source. On the Overview page, scroll down to the streaming syncs table and select + Create streaming sync.

- Enter the name of the SAP table to stream.
- Choose a location for the output streaming dataset.
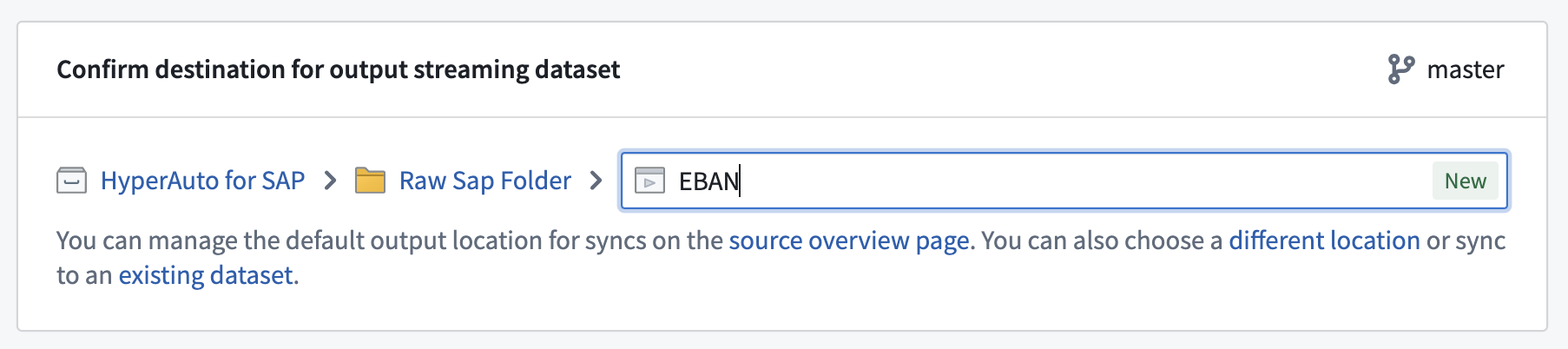
:::callout{theme="warning"} Before proceeding, ensure the preview pane at the bottom of the screen has finished loading. The schema for the streaming dataset is derived from this preview. In some cases, the preview may only display the schema without data — this is sufficient. :::
- Select Create streaming sync. You can choose to start the stream immediately or start it manually after creation.
:::callout{theme="neutral"} To ensure a stream automatically restarts after Data Connection agent or SAP system downtime, set a schedule on the streaming dataset with a 1-minute time trigger. :::
Throughput and partition keys¶
Switching the throughput setting from Normal to Very high may improve performance but increases the number of partitions used. When more than one partition is used, partition keys must be set to guarantee ordering between unique records from SAP. These keys should correspond to the primary key of the table in SAP.
Webhooks¶
SAP webhooks allow you to write data back to SAP by invoking Business APIs (BAPIs) from Foundry. See Webhooks for an overview of how to set up a webhook.
:::callout{theme="success"} SAP webhooks support Foundry worker connections in Foundry-managed cloud compute. We recommend this runtime for SAP webhooks instead of executing them through a data connection agent. Existing SAP sources configured on a Foundry worker automatically benefit from cloud execution with no migration required; SAP sources running on a data connection agent should be switched to a Foundry worker to take advantage of cloud-executed webhooks. :::
The only task type available for SAP webhooks is sap-run-function-webhook-task-v0. The following example invokes BAPI_SALESORDER_CHANGE to modify the purchase date for a given sales document:
{
"function-name": "BAPI_SALESORDER_CHANGE",
"inputs": {
"SALESDOCUMENT": {{json sales-doc-id}},
"ORDER_HEADER_IN": {
"PURCH_DATE": {{json purchase-date}}
},
"ORDER_HEADER_INX": {
"UPDATEFLAG": "U",
"PURCH_DATE": "X"
}
},
"output": "RETURN"
}
To target a remote SAP system, add a remote field to the task body:
{
...
"output": "RETURN",
"remote": {
"context": "<SAP_CONTEXT_NAME>"
}
}
Related documentation¶
The following guides cover workflows that involve both SAP-side and Foundry-side configuration:
- Extract long text from SAP: Decompress and ingest long texts from the
STXLtable. - Configure custom authorizations and role management: Set up custom authorization roles for the SAP add-on.
- Configure extractors: Configure SAP BW Business Content extractors.
- Ingest HANA views from SAP: Publish and ingest HANA external views.
- User-attributed SAP writeback with OAuth 2.0: Configure OAuth 2.0 for named-user writeback to SAP.
中文翻译¶
SAP(自定义源)¶
SAP(自定义源)连接器允许您使用手动配置的源(连接器类型为 magritte-sap-source)将 Foundry 连接到 SAP 系统。该连接器使用基于 YAML 的自定义设置,而非较新 SAP 连接器中提供的引导式配置。
:::callout{theme="warning"} 新的 SAP 集成应使用 SAP ERP 或 SAP SLT 连接器。这些连接器使用更新、性能更优的 API 从 SAP 读取数据,并提供引导式设置体验。SAP(自定义源)连接器适用于在这些连接器类型可用之前建立的现有集成。
使用 SAP(自定义源)连接器需要在目标 SAP 应用层安装 Palantir Foundry Connector 2.0 for SAP Applications 插件。 :::
支持的能力¶
| 能力 | 状态 |
|---|---|
| 探索(Exploration) | 🟢 正式可用 |
| 批量同步(Batch syncs) | 🟢 正式可用 |
| 增量同步(Incremental) | 🟢 正式可用 |
| 流式同步(Streaming syncs) | 🟡 Beta 版 |
| Webhook | 🟢 正式可用 |
设置¶
-
打开 Data Connection 应用,选择屏幕右上角的 + New Source。
-
选择 Add Custom Source。
-
为源指定名称和位置。
-
在自定义 YAML 部分,输入源定义:
type: magritte-sap-source
url: https://<host>:<port>/sap/palantir
usernamePassword: <username>:{{password}}
<host>是 SAP 应用服务器的主机名。<port>是 Internet Communication Manager (ICM) 的 HTTPS(或 HTTP)端口。- 用户名和密码是在安装 Connector 时为 Foundry 创建的技术用户凭据。
:::callout{theme="warning"}
请完全按照所示输入 {{password}}。保存后,在对话框右侧的 Encrypted values 下输入密码值。
:::
- 选择 Save。
了解更多关于在 Foundry 中 设置连接器 的信息。
启用流式同步(仅限 SLT)¶
要支持流式同步,源必须配置为显式的 SLT 连接类型。在源 YAML 中添加 connectionType 参数:
type: magritte-sap-source
url: https://<host>:<port>/sap/palantir
usernamePassword: <username>:{{password}}
connectionType:
type: slt
slt:
context: <context>
context 值是 SLT 复制服务器与源 ERP 系统之间 RFC 连接的唯一标识符。了解更多关于 配置 SLT 的信息。
源配置¶
以下参数可在源上进行配置。
| 参数 | 必填 | 默认值 | 描述 |
|---|---|---|---|
url |
是 | SAP 插件服务端点的基础 URL。 | |
usernamePassword |
是 | 为 Foundry 创建的技术用户的用户名和密码。 | |
useKernelJsonSerialization |
否 | false |
对分页数据使用内核 JSON 序列化。与 useTsvFormat: true 不兼容。 |
useTsvFormat |
否 | false |
对分页数据使用 TSV 格式而非 JSON。 |
output |
否 | 50,000 行 | 每次请求的最大 Parquet 文件大小(行数或字节数)。也可在 每个同步中覆盖。 |
convertDatesToStrings |
否 | false |
将此源下的所有同步中的日期作为字符串摄取。 |
proxy |
否 | 无 | 用于连接 SAP 的代理配置。 |
cacheConfigurations |
否 | 无 | 按 SAP 对象类型配置缓存超时。 |
网络与连接¶
确保正确配置 出口策略,以允许 Foundry 访问 SAP 系统。对于本地 SAP 环境,通常需要 代理策略 来正确路由流量。
许多 SAP 系统使用自定义签名证书,这可能在首次配置连接时导致 SSL 握手异常。请确保从系统中获取正确的自定义证书,并 将其添加到源中。
源探索¶
创建源后,使用 SAP Source Explorer 进行交互式探索。
- 导航到源,选择 Explore and create syncs。
- 对于远程和 SLT 连接,选择适当的上下文。
- 选择感兴趣的表或模块,并将其添加到图中。
批量同步¶
创建同步¶
为每个要提取到 Foundry 的 SAP 对象创建同步。
:::callout{theme="neutral"} 同步配置 UI 有两种模式:Basic 和 Advanced。Advanced 选项卡以 YAML 形式显示完整的同步定义,某些对象类型和下面记录的配置参数需要此模式。您可以切换回 Basic 视图,但任何没有 UI 对应项的 YAML 属性将不会显示并会丢失。 :::
- 从源概览页面,选择批量同步旁边的 + New。
- 配置标准设置:名称、目标数据集和调度。
- 将 Transaction type 设置为以下选项之一:
- APPEND — 用于增量更新。详见 增量同步。
- SNAPSHOT — 用于全量加载。
- 选择 SAP object type(见下文 SAP 对象类型)。
- 如果使用 SLT 或连接到远程系统,请选择 Context。有关上下文的详细信息,请参阅 安装远程代理。
- 输入 Object name。输入时,该字段会根据所选 SAP 对象类型建议匹配的对象。
- 如果配置增量同步,请提供 Incremental field。
- 可选地,在 Extras 选项卡中配置其他参数。
SAP 对象类型¶
以下对象类型可从同步配置 UI 的 SAP object type 下拉菜单中获得。
| 对象类型 | 描述 |
|---|---|
| ERP Table | 从 SAP ABAP 数据字典中的任何 ERP 表或视图中提取数据,包括自定义 Z* 表。 |
| BW InfoProvider | 从 BW InfoProvider(InfoCube、DataStore 对象或 MultiProvider)中提取数据。继承所有 SAP BW 授权概念。 |
| BW BEx Query | 在 BW 系统中运行 BEx 查询。见下文 BEx 查询配置。 |
| SLT | 从 SLT Operational Delta Queue (ODQ) 中提取数据。SLT 是一种基于触发器的复制工具,具有内置的 CDC 机制。需要 Context。 |
| BW Content Extractor | 运行 ERP Business Content 提取器——具有内置业务逻辑和 CDC 机制的即用型结构。对于支持增量提取的提取器,使用 APPEND。见 配置提取器。 |
| Function | 在 ERP 或 BW 系统中运行远程启用的函数或 BAPI。见下文 函数配置。 |
| ERP Table Data Model | 基于主键/外键模型读取 ERP 表之间的关系。使用 depth 参数控制要跟踪的关系层级数。 |
| Remote ERP Table | 从远程 ERP 系统中的 ERP 表中提取数据。需要 Context 来标识远程系统。 |
| Remote BW InfoProvider | 从远程 BW 系统中的 BW InfoProvider 中提取数据。需要 Context。 |
| Remote BW BEx Query | 在远程 BW 系统中运行 BEx 查询。需要 Context。 |
| Remote Function | 在远程 ERP 或 BW 系统中运行远程启用的函数。需要 Context。 |
| Transaction codes | 使用 ABAP List Viewer (ALV) 从 SAP 报表中提取数据。仅限 Advanced 选项卡。 |
| HANA views | 从 SAP 应用层启用的 HANA 视图中提取数据。仅限 Advanced 选项卡。 |
| CDS views | 从 ABAP CDS (Core Data Services) 视图中提取数据。仅限 Advanced 选项卡。 |
远程对象类型需要标识远程系统的 Context 值。了解更多关于 远程连接 的信息。
BEx 查询配置¶
BEx 是一个基于 SAP BW InfoProvider 构建的多维查询框架。BEx 查询使用标准的 SAP BW 访问方法,并继承所有 SAP BW 授权概念。它们表示应用于 InfoProvider 视图的业务逻辑。
:::callout{theme="neutral"} 如果 BEx 查询具有动态列(关键值在列上的特征,使得每个关键值都随特征值重复),则会产生动态输出。Foundry 不支持动态列——请相应调整您的查询。 :::
当您选择 BW BEx Query 作为对象类型时,同步编辑器会显示一个专用的 BEx 查询构建器,包含以下选项:
| 选项 | 描述 |
|---|---|
| Use Technical Names | 在技术列名和人类可读(依赖于语言)列名之间切换。 |
| Drop columns | 从输出中移除关键特征。 |
| Free characteristics | 将自由特征(如 BEx 查询中定义的)添加到输出中。 |
| Filter | 在查询运行后过滤数据(查询后过滤)。 |
| BEx Query Input Variables | 为 BEx 查询输入变量提供过滤值。 |
有关 BEx 分页配置,请参见同步参数部分中的 高级 YAML 参数。
函数配置¶
SAP 函数模块既可以从 SAP 系统提取数据,也可以将数据写回 SAP 系统。Connector 只能从至少有一个表格输出参数的函数中提取数据。
:::callout{theme="neutral"} Foundry 技术用户需要以下授权角色才能提取函数结果:
/PALANTIR/SERVICE_USER/PALANTIR/CONTENT_FUNCTION_ALL- 运行特定函数所需的任何授权角色或对象 :::
如果函数返回多个输出参数,请使用 paramName 参数指定要写入 Foundry 数据集的输出:
type: magritte-sap-source-adapter
sapType: function
obj: BAPI_USER_GETLIST
paramName: USERLIST
输入参数可以使用 inputParams 进行配置。支持三种值类型:
| 类型 | YAML 语法 |
|---|---|
| 单值 | PARAM_NAME: 'value' |
| 结构体(字典) | PARAM_NAME: '{"FIELD1": "value1", "FIELD2": "value2"}' |
| 表(字典列表) | PARAM_NAME: '[{"FIELD1": "value1"}, {"FIELD1": "value2"}]' |
带有表类型输入参数的示例:
type: magritte-sap-source-adapter
sapType: function
obj: EM_GET_NUMBER_OF_ENTRIES
inputParams:
IT_TABLES: '[{"TABNAME":"TSTC"}]'
paramName: IT_TABLES
仅限高级的对象类型¶
以下对象类型无法从下拉菜单中获得,必须在 Advanced 选项卡中配置。
事务代码(Transaction codes)¶
提取 SAP 报表生成的数据。仅支持使用 ABAP List Viewer (ALV) 的报表。
按事务代码名称:
type: magritte-sap-source-adapter
sapType: tcode
obj: ZTEST_ALV
按程序名称:
type: magritte-sap-source-adapter
sapType: tcode
obj: RSUSR200
programType: program
以下可选参数可以添加到同步 YAML 中:
| 参数 | 描述 |
|---|---|
filter |
为选择屏幕变量传递用户输入。不能任意过滤输出字段。 |
selectionVariant |
传递预定义的选择屏幕变体。如果与 filter 结合使用,filter 值会覆盖匹配的变体值。 |
outputVariant |
传递程序的布局名称。仅支持在 SAP 选择屏幕上定义了布局参数的程序。 |
ingestionType: spool |
在摄取前将报表输出发送到打印机队列。建议用于超过 SAP 内部表限制的大型报表。设置后,所有列都以 String 类型摄取。 |
HANA 视图¶
从 SAP 应用层启用的 HANA 视图中提取数据。有关先决条件,请参阅 从 SAP 摄取 HANA 视图。
type: magritte-sap-source-adapter
sapType: hanaview
obj: ZEXT_SBOOK
CDS 视图¶
从 ABAP CDS (Core Data Services) 视图中提取数据。ABAP CDS 在应用服务器的中央数据库上定义语义数据模型。
:::callout{theme="neutral"} 目前不支持从参数化 CDS 视图中提取数据。 :::
增量同步¶
增量同步是有状态的同步,允许从同一表进行追加类型的事务。要启用增量同步,请将 Transaction type 设置为 APPEND。
以下增量类型可用:
| 增量类型 | 描述 |
|---|---|
| Single field | 导入单个字段大于或等于已导入最大值的行。 |
| Multiple fields | 与单字段相同,但使用 OR 运算符组合多个字段。当同时存在"创建时间"和"最后更新时间"时间戳字段时很有用。用逗号分隔字段。 |
| Concatenate fields | 与多字段相同,但将字段连接在一起而不是使用 OR 组合。当存在单独的"最后更新日期"和"最后更新时间"字段时很有用。 |
| Use change document table | 基于 SAP 变更文档表(CDHDR 和 CDPOS)中的更新导入行。当目标表缺少单调递增字段时很有用。请注意,某些对象的插入可能不会被捕获。 |
| Use twin or twinjoin table | 当单独"孪生"表中的字段满足增量条件时,从目标表导入行。twinjoin 表允许目标表是多个表的连接。 |
下表显示了每种对象类型支持的增量类型:
| 对象类型 | 单字段 | 多字段 | 连接字段 | 变更文档表 | 孪生表 | SAP 内置 | 复制 | 基于请求 |
|---|---|---|---|---|---|---|---|---|
| 表 | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||
| 远程表 | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||
| InfoProvider | ✓ | ✓ | ✓ | |||||
| 远程 InfoProvider | ✓ | ✓ | ✓ | |||||
| SLT | ✓ | |||||||
| 提取器 | ✓ |
:::callout{theme="neutral"} BEx 查询或函数不支持增量更新。这些对象类型的所有同步都是全量提取。 :::
增量字段理想情况下应为单调递增的值。系统使用"大于或等于"比较,以避免在同步运行于某个日期中间时丢失数据。因此,Foundry 数据集中可能会出现重复值,应在转换管线的第一步中将其移除。
孪生表配置¶
Incremental Twin Table 设置指定孪生表。Incremental Twin Mapping 设置定义主表和孪生表之间的连接条件。
映射语法:
{PRIMARY_TABLE_NAME}-{FIELD_NAME}={TWIN_TABLE_NAME}-{FIELD_NAME}
多个连接条件可以用分号(AND 运算符)组合。
基于 InfoProvider 的请求增量¶
在 SAP BW 中,DSO 和 InfoCube 使用数据传输过程 (DTP) 加载。每个 DTP 创建一个加载请求,Connector 使用这些请求来捕获更改的数据。
:::callout{theme="warning"} 此功能仅支持未压缩的请求。在加载到 Foundry 之前,请求不得被压缩。如果在加载前压缩了请求,同步将失败,必须重复初始加载。 :::
通过 Advanced 选项卡配置:
type: magritte-sap-source-adapter
sapType: infoprovider
obj: <technical-name-of-infoprovider>
incrementalType: REQUEST
重置增量状态¶
要强制全量重新加载并重新初始化增量摄取:
- 切换到同步配置中的 Advanced 选项卡。
- 在 YAML 中添加
resetIncrementalState: true。 - 将事务类型设置为 SNAPSHOT(保留所有
incremental*参数)。 - 运行同步。这将执行全量快照,替换数据集中的所有文件。
- 从 YAML 中移除
resetIncrementalState: true。 - 将事务类型设置回 APPEND。
后续同步将正常恢复增量追加。
同步参数¶
以下参数可在 Extras 选项卡或通过 Advanced YAML 视图中使用。
通用参数¶
| 参数 | 适用于 | 描述 |
|---|---|---|
| Drop columns | ERP Table, Remote ERP Table | 在提取前排除所选列。提高性能并防止摄取敏感或不必要的字段。 |
| Timestamp | 所有 | 添加 /PALANTIR/TIMESTAMP(同步运行时间)和 /PALANTIR/ROWNO(同步内记录顺序)列。有助于下游去重记录。/PALANTIR/ROWNO 仅在使用 SLT 或 CDPOS/CDHDR 增量模式时有意义——值越高表示更改越新。 |
| Page size | 所有 | 每页返回的行数。默认值为 50,000。低于默认值的值无效;减少默认值需要调用 SAP 插件系统。 |
| Retry count | 所有 | 当请求因资源短缺失败时的重试次数。 |
| Retry delay | 所有 | 重试尝试之间的延迟(秒)。 |
| Param name | Function | 当函数返回多个输出参数时,选择要写入 Foundry 数据集的输出表。 |
| Depth | ERP Table Data Model | 要跟踪的关系层级数。使用 1 表示一级,2 表示二级,依此类推。 |
| Trace logging | 所有 | 设置为 On 以启用此同步的跟踪日志记录。 |
| Fetch option | SLT | XML 使用压缩数据获取(更快)。Direct 以字符串形式获取。如果在使用 XML 时遇到数据内容错误,请使用 Direct。 |
| Debug logging | 所有 | 启用调试日志记录。在同步期间在 SAP 中启动后台进程——可能消耗资源。请谨慎使用。 |
| Continuous resource check | 所有 | 控制所有分页请求还是仅初始请求受资源检查约束。 |
| Resource check | 所有 | 禁用将移除所有资源检查。可能给 SAP 带来过多负载。请谨慎使用。 |
| Filter | 所有 | 使用 SAP 字段值和运算符过滤提取的数据。支持 动态过滤关键字。 |
| Advanced YAML parameters | 因情况而异 | maxRowsPerSync, bexSettings, ignoreUnexpectedValues, outputSettingsOverride。 |
调试日志记录¶
:::callout{theme="danger"} 调试日志记录会在 SAP 系统中启动一个后台进程,该进程在同步期间运行。这可能消耗资源并影响其他用户。请谨慎使用。 :::
设置为 On 以启用此同步的调试日志记录。
持续资源检查¶
当设置为 On 时,所有分页请求都受资源检查(内存、CPU)约束。当设置为 Off 时,仅检查初始页面请求。有关详细信息,请参阅 性能参数。
资源检查¶
:::callout{theme="danger"} 禁用资源检查会导致同步无论可用内存、CPU 和进程如何都运行。这可能给 SAP 系统带来过多负载。请谨慎使用。 :::
设置为 Off 以禁用此同步的所有资源检查。
过滤器¶
过滤从 SAP 提取的数据。所有字段名称必须与数据字典匹配。
| 运算符 | 含义 |
|---|---|
, |
OR |
; |
AND |
: |
Between |
= |
等于 |
!= |
不等于 |
>, >=, <, <= |
比较 |
* |
通配符 |
示例:
- 价格在 500 到 650 之间:
PRICE=500:650 - 客户 A、B 或 C:
CUSTOMER=A,B,C - 价格在 500 到 650 之间且客户为 A、B 或 C:
PRICE=500:650;CUSTOMER=A,B,C - 物料以 PAL、DIS 或 SAP 开头:
MATERIAL=PAL*,DIS*,SAP* - 日期为 2019 年 8 月 9 日或之后(格式 YYYYMMDD):
DATE>=20190809
动态过滤器¶
动态过滤器使用特殊关键字和函数创建更灵活的过滤表达式。从插件版本 SP26 及更高版本可用。
固定关键字
| 关键字 | 描述 |
|---|---|
[CURRENTYEAR] |
当前年份,格式为 YYYY。 |
[TODAY] |
今天的日期,格式为 YYYYMMDD。 |
[LASTDAYOFMONTH] |
当前月份的最后一天,格式为 YYYYMMDD。 |
[LASTDAYOFLASTMONTH] |
上个月的最后一天,格式为 YYYYMMDD。 |
[FIRSTDAYOFMONTH] |
当前月份的第一天,格式为 YYYYMMDD。 |
[FIRSTDAYOFLASTMONTH] |
上个月的第一天,格式为 YYYYMMDD。 |
日期计算函数
| 函数 | 描述 |
|---|---|
[ADDDAY] |
向所选日期添加天数。示例:[ADDDAY(22102022,1)] → 23102022。 |
[ADDMONTH] |
向所选日期添加月数。 |
[ADDYEAR] |
向所选日期添加年数。 |
[GETMONTH] |
返回所选日期的月份,为 2 位数值(01–12)。 |
[GETDAY] |
返回所选日期的天数,为 2 位数值。 |
[GETYEAR] |
返回所选日期的年份。 |
函数可以直接与固定关键字一起使用,也可以嵌套使用:
- 单函数:
[ADDDAY([TODAY], 1)] - 嵌套:
[GETDAY([ADDDAY([FIRSTDAYOFMONTH], -1)])]
示例:
- 今天之后的记录:
BUDAT>[TODAY] - 上个月最后一天之后的记录:
BUDAT>[ADDDAY([FIRSTDAYOFMONTH], -1)]
高级 YAML 参数¶
以下参数需要 Advanced 选项卡,在 Basic 视图中没有对应项。
maxRowsPerSync(仅限 SLT):限制每次同步运行返回的行数(近似值)。用于将非常大的表的初始同步拆分为较小的运行:
maxRowsPerSync: 500000
bexSettings(仅限 BEx):配置 BEx 查询分页。从 Connector 版本 SP22 起可用:
bexSettings:
bexPaging: true
bexMemberLimit: 10
bexPaging:启用使用自动生成过滤器的分页。默认值为false。bexMemberLimit:过滤器候选选择的阈值。成员数超过此值的 InfoObject 将从过滤器生成中排除。默认值为200。最小值为2。
-ignoreUnexpectedValues:如果同步失败并显示 Unexpected value encountered in SAP data Failed to parse value XXX in field YYY,则表示日期或数值无法解析。要继续同步并将无法解析的值设置为 null:
ignoreUnexpectedValues: true
同步结束时将记录一条警告,其中包含解析异常的摘要。
:::callout{theme="warning"} 此设置在 Basic 视图中没有对应项。如果切换回 Basic 视图,此设置将丢失。 :::
-outputSettingsOverride:覆盖特定同步的源级 Parquet 文件大小设置:
outputSettingsOverride:
maxFileSize:
type: rows
rows:
max: 10000
outputSettingsOverride:
maxFileSize:
type: bytes
bytes:
approximateMax: 400MB
:::callout{theme="warning"} 以字节为单位指定最大大小是近似值——生成的文件大小可能略小或略大。字节值必须至少是 Parquet 写入器内存缓冲区大小的两倍,默认值为 128 MB。 :::
流式同步¶
:::callout{theme="neutral" title="Beta"} 来自 SAP 的流式同步处于 beta 开发阶段,可能在您的环境中不可用。功能在活跃开发期间可能会发生变化。 :::
流式同步仅支持通过 SAP SLT 复制服务器 的连接,并且需要配置了显式 SLT 连接类型的源(见上文 启用流式同步)。
每个流式同步在 SLT 复制服务器中创建并订阅自己的 Operational Delta Queue (ODQ)。Foundry 定期轮询队列(默认间隔:1 秒):
- 如果队列为空,则在下一次轮询之前不会发出更多请求。
- 如果队列上有 50,000 条或更少的记录,则同步消费它们。
- 如果超过 50,000 条记录,则分页消费。
为获得最低延迟,SLT 复制服务器应至少拥有与活跃流式同步数量相同的可用对话工作进程。
创建流式同步¶
- 打开 SAP 源。在 Overview 页面上,向下滚动到流式同步表,选择 + Create streaming sync。
- 输入要流式传输的 SAP 表的名称。
- 选择输出流式数据集的位置。
:::callout{theme="warning"} 在继续之前,请确保屏幕底部的预览窗格已完成加载。流式数据集的模式源自此预览。在某些情况下,预览可能仅显示模式而不显示数据——这已足够。 :::
- 选择 Create streaming sync。您可以选择立即启动流,或在创建后手动启动。
:::callout{theme="neutral"} 为确保流在 Data Connection 代理或 SAP 系统停机后自动重启,请在流式数据集上 设置调度,使用 1 分钟的时间触发器。 :::
吞吐量和分区键¶
将吞吐量设置从 Normal 切换到 Very high 可能会提高性能,但会增加使用的分区数量。当使用多个分区时,必须设置分区键以保证来自 SAP 的唯一记录之间的顺序。这些键应对应于 SAP 中表的主键。
Webhook¶
SAP webhook 允许您通过从 Foundry 调用业务 API (BAPI) 将数据写回 SAP。有关如何设置 webhook 的概述,请参阅 Webhooks。
:::callout{theme="success"} SAP webhook 支持 Foundry 管理的云计算中的 Foundry worker 连接。我们建议将此类运行时用于 SAP webhook,而不是通过 data connection agent 执行它们。在 Foundry worker 上配置的现有 SAP 源自动受益于云执行,无需迁移;在 data connection agent 上运行的 SAP 源应 切换到 Foundry worker,以利用云执行的 webhook。 :::
SAP webhook 唯一可用的任务类型是 sap-run-function-webhook-task-v0。以下示例调用 BAPI_SALESORDER_CHANGE 来修改给定销售文档的采购日期:
{
"function-name": "BAPI_SALESORDER_CHANGE",
"inputs": {
"SALESDOCUMENT": {{json sales-doc-id}},
"ORDER_HEADER_IN": {
"PURCH_DATE": {{json purchase-date}}
},
"ORDER_HEADER_INX": {
"UPDATEFLAG": "U",
"PURCH_DATE": "X"
}
},
"output": "RETURN"
}
要定位远程 SAP 系统,请在任务主体中添加 remote 字段:
{
...
"output": "RETURN",
"remote": {
"context": "<SAP_CONTEXT_NAME>"
}
}
相关文档¶
以下指南涵盖了涉及 SAP 端和 Foundry 端配置的工作流程:
- 从 SAP 提取长文本:解压缩并从
STXL表摄取长文本。 - 配置自定义授权和角色管理:为 SAP 插件设置自定义授权角色。
- 配置提取器:配置 SAP BW Business Content 提取器。
- 从 SAP 摄取 HANA 视图:发布和摄取 HANA 外部视图。
- 使用 OAuth 2.0 的用户属性 SAP 回写:配置 OAuth 2.0 以实现命名用户回写到 SAP。