Data expectations(数据期望(Data expectations))¶
Data expectations are requirements that can be applied to dataset outputs. These requirements (known as "expectations") can be used to create checks that improve data pipeline stability.
Data expectations can be set on each pipeline output to define an expectation on the resulting output. Pipeline Builder currently supports two data expectations: primary key and row count.
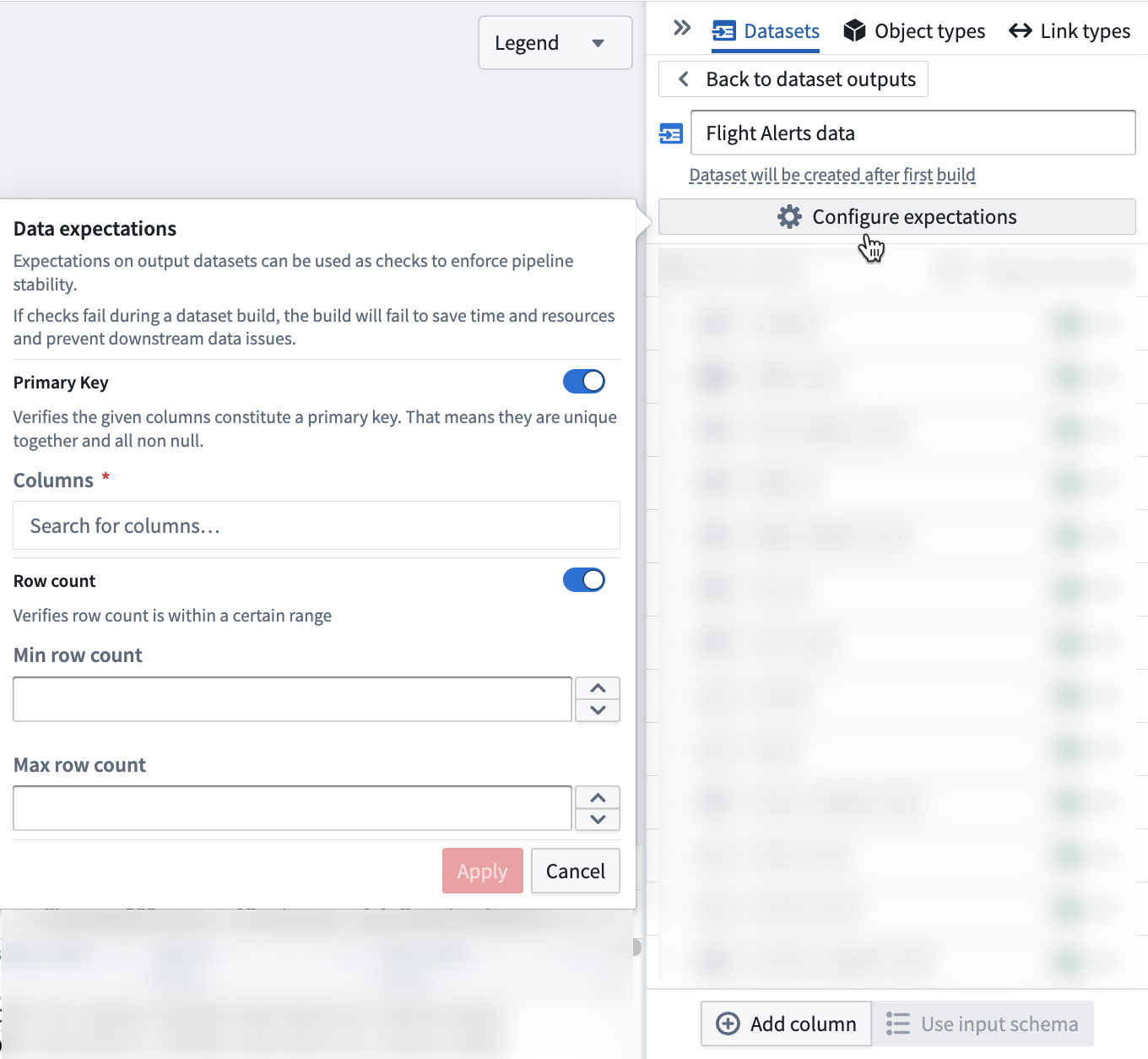
If any expectations fail, the build will fail. The job expectations pane will show which data expectations passed and failed.
Primary key data expectations¶
Primary key expectations are provided with one or more column names and verify:
- Each column has no null values.
- The combination of columns is unique.
:::callout{theme="neutral"} If you have an incremental build, and your primary key check is taking a long time, try adding a projection to your primary key column. :::
Example of a primary key data expectation¶
In the specific column selected, we check that every entry underneath is unique.
If two columns are selected, we check that the combination of both columns are unique.
In our example, we'll use id and time as two columns existing in our dataset.
Example dataset:
| id | time |
|---|---|
| 1 | 8pm |
| 1 | 9pm |
| 2 | 8pm |
| 3 | 8pm |
The above example would pass the check. This is because even though 1 and 8pm are repeated individually, the combination of id and time remains unique.
Conversely, the following would fail:
| id | time |
|---|---|
| 1 | 8pm |
| 2 | 9pm |
| 1 | 8pm |
This table would fail the check because the 1 and 8pm combination is repeated.
Row count data expectations¶
Row count expectations are provided with a minimum and/or maximum row count.
If a minimum row count is provided, the expectation will verify that there are at least the specified amount of rows.
If a maximum row count is provided, the expectation will verify that there are at most this many rows.
中文翻译¶
数据期望(Data expectations)¶
数据期望(Data expectations)是可应用于数据集输出的要求。这些要求(称为"期望")可用于创建检查,从而提高数据管道的稳定性。
可以在每个管道输出上设置数据期望,以定义对最终输出的预期。管道构建器(Pipeline Builder)目前支持两种数据期望:主键(Primary key)和行数(Row count)。
如果任何期望未通过,构建将失败。作业期望面板将显示哪些数据期望通过或未通过。
主键数据期望(Primary key data expectations)¶
主键期望需要提供一个或多个列名,并验证:
- 每列没有空值。
- 列的组合是唯一的。
:::callout{theme="neutral"} 如果您使用增量构建,且主键检查耗时较长,请尝试为主键列添加投影(projection)。 :::
主键数据期望示例¶
在选定的特定列中,我们检查每个条目是否唯一。
如果选择了两列,我们检查这两列的组合是否唯一。
在示例中,我们将使用数据集中的 id 和 time 两列。
示例数据集:
| id | time |
|---|---|
| 1 | 8pm |
| 1 | 9pm |
| 2 | 8pm |
| 3 | 8pm |
上述示例将通过检查。这是因为尽管 1 和 8pm 各自重复出现,但 id 和 time 的组合仍然是唯一的。
相反,以下示例将无法通过:
| id | time |
|---|---|
| 1 | 8pm |
| 2 | 9pm |
| 1 | 8pm |
该表将无法通过检查,因为 1 和 8pm 的组合重复出现了。
行数数据期望(Row count data expectations)¶
行数期望需要提供最小和/或最大行数。
如果提供了最小行数,期望将验证行数是否至少达到指定数量。
如果提供了最大行数,期望将验证行数是否不超过此数量。