Frequent pattern mining(频繁模式挖掘)¶
Pipeline Builder simplifies the process of frequent pattern mining by using the power of the Frequent Pattern Growth (FP-Growth) algorithm in a transform. The algorithm enables you to easily construct and manage mining workflows and discover valuable and frequent patterns in large datasets.
Frequent pattern mining is a data mining technique used to identify recurring patterns or associations within large datasets. The primary goal of frequent pattern mining is to discover relationships between items or events that occur together, more frequently than expected, by chance. These patterns, often referred to as frequent item sets, can help uncover hidden associations and dependencies in the data, facilitating better decision-making and prediction.
Frequent pattern mining can be applied in numerous ways across various domains, including market basket analysis, recommendation systems, bioinformatics, network traffic analysis, customer attribute analysis, explainable AI (XAI), and more. By identifying frequent patterns, organizations can gain valuable insights, enhance their strategies, and improve overall efficiency.
Frequent pattern mining example: Market basket analysis¶
A common application of frequent pattern mining in retail is called "market basket analysis". Using the Pipeline Builder Frequent Pattern Growth transform, you can identify the combinations of products that frequently occur in the same transactions.
For example, a supermarket might have a dataset of past purchases (transactions) by its customers. Each transaction contains a set of products that were bought together. Below is a simplified example dataset of such transactions:
| transaction_id | products_purchased |
|---|---|
| 1 | [Bread, Butter, Milk] |
| 2 | [Bread, Butter] |
| 3 | [Bread, Diapers, Beer] |
| 4 | [Milk, Diapers, Beer, Butter] |
| 5 | [Bread, Butter, Diapers] |
The frequent pattern growth transform takes an Items column and a Minimum support value as inputs. In this example, the products_purchased column is the items column. Since only frequent patterns will be in the output, the Minimum support is set to 0.6; the transform will only return patterns that occur in at least 60% of the transactions. The following screenshot shows how to configure the transform for this example:
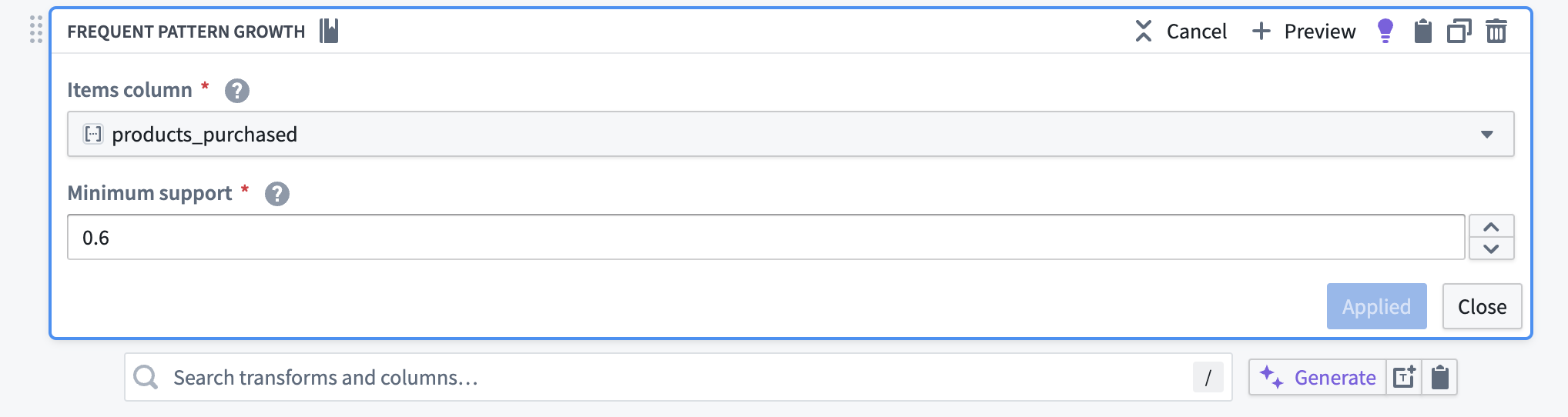
The output dataset of the transform is the following:
| pattern | pattern_occurence | total_count |
|---|---|---|
| [Bread] | 4 | 5 |
| [Butter] | 4 | 5 |
| [Bread, Butter] | 3 | 5 |
| [Diapers] | 3 | 5 |
In this case, frequent pattern mining reveals that Bread and Butter often appear together in transactions (they are a frequent item set that occurs three times in five transactions). This information could be used to drive various business strategies, such as product placements (placing bread and butter close together to increase sales) or promotions (discounts on butter when bought with bread, and vice versa).
The above is a simplified example of much larger and more complex datasets found in real use cases; the use of efficient algorithms like FP-Growth is crucial for effective frequent pattern mining.
中文翻译¶
频繁模式挖掘¶
Pipeline Builder 通过利用转换中的频繁模式增长(FP-Growth)算法,简化了频繁模式挖掘的流程。该算法使您能够轻松构建和管理挖掘工作流,并在大型数据集中发现有价值的频繁模式。
频繁模式挖掘是一种数据挖掘技术,用于识别大型数据集中反复出现的模式或关联关系。频繁模式挖掘的主要目标是发现那些共同出现、且出现频率高于随机预期的事件或项目之间的关联关系。这些模式通常被称为频繁项集,可以帮助揭示数据中隐藏的关联和依赖关系,从而促进更好的决策和预测。
频繁模式挖掘可广泛应用于多个领域的多种场景,包括购物篮分析、推荐系统、生物信息学、网络流量分析、客户属性分析、可解释人工智能(XAI)等。通过识别频繁模式,组织可以获得宝贵的洞察,优化策略,并提升整体效率。
频繁模式挖掘示例:购物篮分析¶
频繁模式挖掘在零售业中的一个常见应用称为"购物篮分析"。使用 Pipeline Builder 的频繁模式增长转换,您可以识别在同一交易中频繁出现的产品组合。
例如,一家超市可能拥有客户历史购买记录(交易)的数据集。每笔交易包含一组同时购买的产品。以下是此类交易的简化示例数据集:
| transaction_id | products_purchased |
|---|---|
| 1 | [面包, 黄油, 牛奶] |
| 2 | [面包, 黄油] |
| 3 | [面包, 尿布, 啤酒] |
| 4 | [牛奶, 尿布, 啤酒, 黄油] |
| 5 | [面包, 黄油, 尿布] |
频繁模式增长转换将项目列和最小支持度值作为输入。在此示例中,products_purchased列即为项目列。由于输出中仅包含频繁模式,因此将最小支持度设置为0.6;该转换将仅返回在至少60%的交易中出现的模式。以下截图展示了如何为此示例配置转换:
该转换的输出数据集如下:
| pattern | pattern_occurrence | total_count |
|---|---|---|
| [面包] | 4 | 5 |
| [黄油] | 4 | 5 |
| [面包, 黄油] | 3 | 5 |
| [尿布] | 3 | 5 |
在此案例中,频繁模式挖掘揭示了面包和黄油经常在交易中同时出现(它们是一个频繁项集,在五笔交易中出现了三次)。这一信息可用于驱动各种业务策略,例如产品摆放(将面包和黄油放在一起以增加销量)或促销活动(购买面包时黄油打折,反之亦然)。
以上是对实际用例中更大、更复杂数据集的简化示例;使用像 FP-Growth 这样的高效算法对于有效的频繁模式挖掘至关重要。