Create unique IDs in Pipeline Builder(在 Pipeline Builder 中创建唯一 ID)¶
In Pipeline Builder, unique IDs facilitate tracking, processing, and analysis of the data, ensuring that each record can be individually identified and properly handled. For this reason, it is often necessary to create unique identifiers (IDs) for records. This section explains why using a monotonically increasing ID is not the best approach and why the preferred method for generating unique IDs is the concatenation of string columns followed by a SHA256 hash.
Using Concatenation of String Columns and SHA256 Hash¶
The best approach to generate unique IDs is to concatenate string columns from the input data and then create a SHA256 hash of the concatenated string.
To generate unique IDs using this method in Pipeline Builder, follow these steps within the Pipeline Builder transform path:
- Identify the string columns that, when combined, can uniquely identify each record in your dataset.
- Concatenate the selected string columns to form a single string for each record.
- Use “Hash sha256” to compute the SHA256 hash of the concatenated string. The resulting 256-bit hash can be represented as a 64-character hexadecimal string, which will serve as the unique ID for each record.

This method has several advantages:
- Consistency: The same input data will always result in the same unique ID, ensuring consistency across different runs of the data pipeline. This makes it easier to track records, identify duplicates, and perform data reconciliation. Notably, if the IDs are used as primary keys for objects, you do not want those primary keys to change as a result of rebuilding the pipeline. Additionally, consider whether someone working on the data downstream at any point might depend on the IDs to be stable.
- Distributed Generation: Since the unique ID is derived from the data itself, multiple processes can generate unique IDs concurrently without the need for synchronization or centralized coordination. This improves scalability and performance in a distributed data processing environment.
By using the concatenation of string columns followed by a SHA256 hash, you can generate unique IDs that are scalable, secure, and consistent, making it an ideal choice for your data pipeline application.
Disadvantages of monotonically increasing IDs¶
While monotonically increasing IDs are not supported in Pipeline Builder, they are often used by data engineers who are familiar with Spark. Monotonically increasing IDs are generated sequentially, such as 1, 2, 3, and so on. While this approach has an inherent simplicity, it has several disadvantages:
- Inconsistency between builds: When using monotonically increasing IDs in Spark, the generated IDs can change between different runs of the same application. This is because the way Spark assigns tasks to its executors can vary, leading to different ID assignment orders. Consequently, this inconsistency can make it difficult to reproduce results, compare different runs, or perform incremental updates, making it a less reliable choice for an ID column. If used as a primary key to an ontology object, this will force a full re-index on every build.
- Reliance on State: Generating monotonically increasing IDs requires maintaining state between rows.
These disadvantages indicate that using monotonically increasing IDs is not the best approach for generating unique identifiers in a data pipeline application. Instead, as detailed in the previous section, we recommend using the concatenation of string columns followed by a SHA256 hash.
If a set of unique columns to hash is not available¶
:::callout{theme="warning"} Be aware that this will not be consistent across builds or previews. This method should be an absolute last resort if a unique set of columns can not be identified. :::
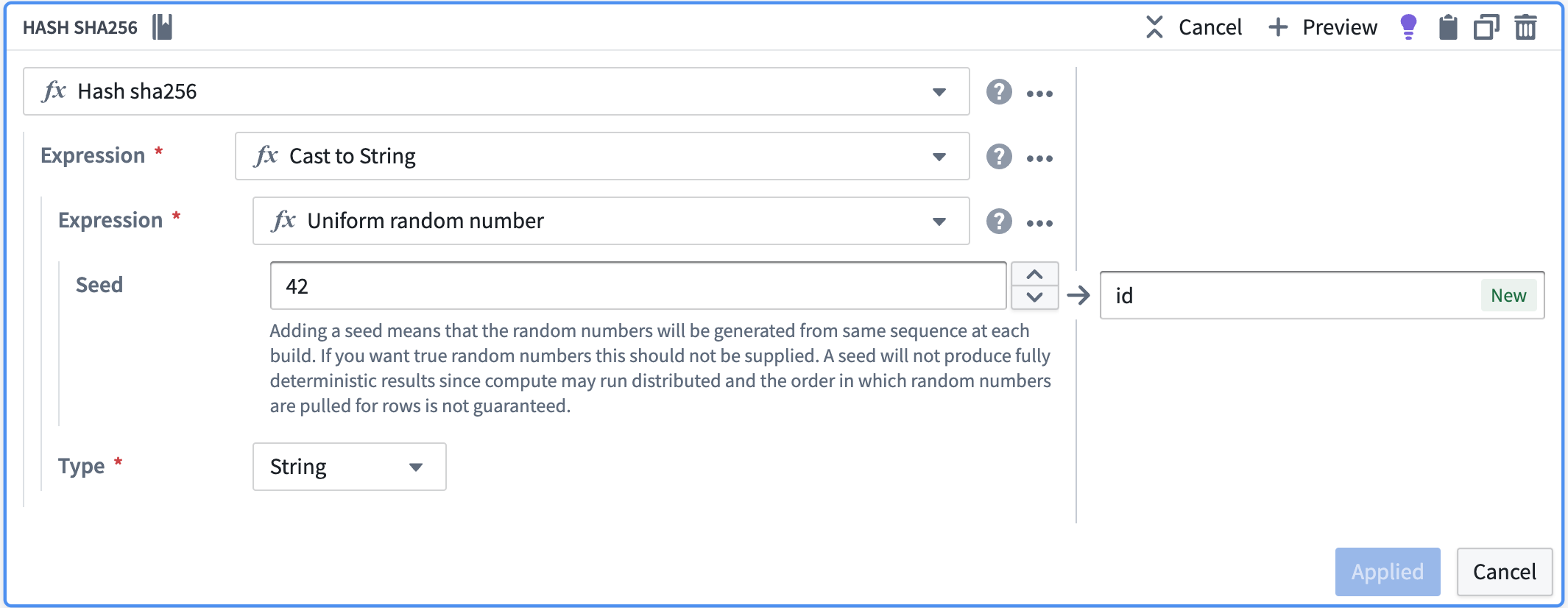
If you do not have a set of columns that define a unique row in your data, you can use the hash of a random number to create the ID. To create an ID in this way, follow the steps below within the Pipeline Builder transform path:
- Create a random number using “Uniform random number”.
- Cast the column to string.
- Use “Hash sha256” to hash that column.
中文翻译¶
在 Pipeline Builder 中创建唯一 ID¶
在 Pipeline Builder 中,唯一 ID 有助于数据的追踪、处理和分析,确保每条记录都能被单独识别和妥善处理。因此,通常需要为记录创建唯一标识符(ID)。本节将解释为什么使用单调递增 ID 并非最佳方案,以及生成唯一 ID 的首选方法是拼接字符串列后使用 SHA256 哈希。
使用字符串列拼接和 SHA256 哈希¶
生成唯一 ID 的最佳方法是将输入数据中的字符串列拼接起来,然后对拼接后的字符串创建 SHA256 哈希。
要在 Pipeline Builder 中使用此方法生成唯一 ID,请按照 Pipeline Builder 转换路径中的以下步骤操作:
- 确定那些组合起来能够唯一标识数据集中每条记录的字符串列。
- 将选定的字符串列拼接起来,为每条记录形成一个单独的字符串。
- 使用 "Hash sha256" 计算拼接字符串的 SHA256 哈希。生成的 256 位哈希值可以表示为 64 个字符的十六进制字符串,它将作为每条记录的唯一 ID。
此方法具有以下几个优点:
- 一致性: 相同的输入数据始终会产生相同的唯一 ID,确保数据管道在不同运行之间的一致性。这使得追踪记录、识别重复项和执行数据对账变得更加容易。值得注意的是,如果这些 ID 被用作对象的主键,您不希望这些主键因重建管道而发生变化。此外,还需考虑下游处理数据的任何人是否可能依赖于这些 ID 的稳定性。
- 分布式生成: 由于唯一 ID 是从数据本身派生出来的,多个进程可以同时生成唯一 ID,无需同步或集中协调。这提高了分布式数据处理环境中的可扩展性和性能。
通过使用字符串列拼接后接 SHA256 哈希的方法,您可以生成可扩展、安全且一致的唯一 ID,使其成为数据管道应用的理想选择。
单调递增 ID 的缺点¶
虽然 Pipeline Builder 不支持单调递增 ID,但熟悉 Spark 的数据工程师经常使用它们。单调递增 ID 是按顺序生成的,例如 1、2、3 等。虽然这种方法具有固有的简单性,但它有几个缺点:
- 构建间的不一致性: 在 Spark 中使用单调递增 ID 时,生成的 ID 可能会在同一应用程序的不同运行之间发生变化。这是因为 Spark 将任务分配给执行器的方式可能不同,导致 ID 分配顺序不同。因此,这种不一致性会使重现结果、比较不同运行或执行增量更新变得困难,使其成为 ID 列中不太可靠的选择。如果用作本体对象(Ontology Object)的主键,这将导致每次构建时都需要进行完全重新索引。
- 依赖状态: 生成单调递增 ID 需要在行之间维护状态。
这些缺点表明,在数据管道应用中使用单调递增 ID 并非生成唯一标识符的最佳方法。相反,如上一节所述,我们建议使用字符串列拼接后接 SHA256 哈希的方法。
如果没有可哈希的唯一列组合¶
:::callout{theme="warning"} 请注意,此方法在构建或预览之间将不一致。只有在无法确定唯一列组合的情况下,才应将其作为万不得已的方法。 :::
如果您的数据中没有能够定义唯一行的列组合,您可以使用随机数的哈希来创建 ID。要以此方式创建 ID,请按照 Pipeline Builder 转换路径中的以下步骤操作:
- 使用 "Uniform random number" 创建一个随机数。
- 将该列转换为字符串类型。
- 使用 "Hash sha256" 对该列进行哈希处理。