Optimize performance(优化性能)¶
This page describes best practices for optimizing function performance and resource usage. Following these guidelines helps minimize compute consumption and ensures your functions run efficiently.
:::callout{theme="info"} For information about compute costs and how functions are metered, see Compute usage with Ontology queries. :::
Understand function compute costs¶
The cost of a function has multiple components:
- Overhead: Each function execution has a fixed overhead of 4 compute-seconds, regardless of what it does.
- Compute time: The vCPU time the function needs to execute.
- External calls: Calls to other parts of the platform (Ontology queries, model inference, LLM calls) incur their own costs.
For more information about how compute-seconds are calculated and measured in the platform, see Usage types.
Use the Performance tab¶
The performance tab provides a tool to analyze and identify performance issues with your functions.
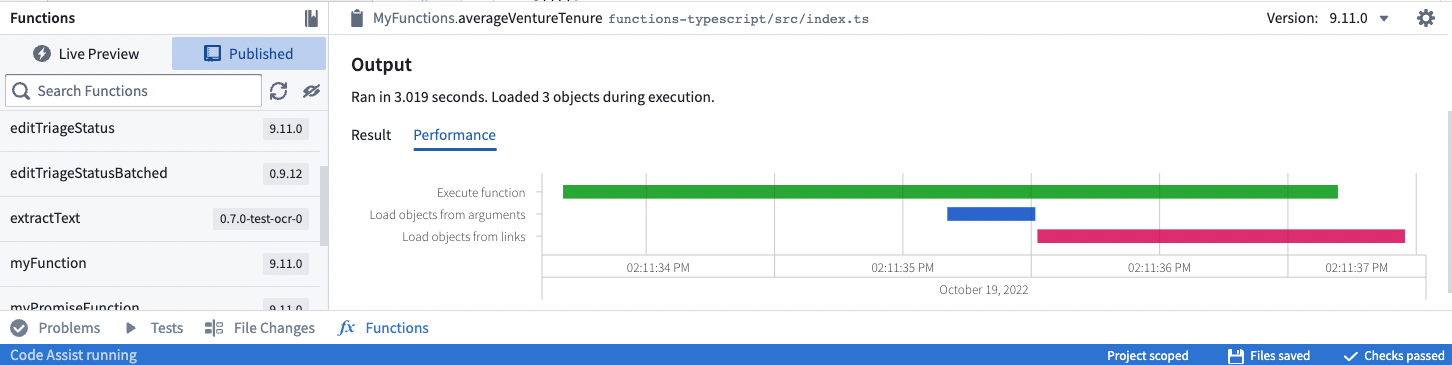
The waterfall graph represents operations as horizontal bars stretched out across time on the X-axis. There are markers for each operation to indicate how time is spent.
- Execute function indicates CPU time spent executing the function code.
- Load objects from arguments and Load objects from links indicate the time spent calling the underlying Ontology backend database service (OSS).
To improve function performance:
- Use the Objects API to aggregate and traverse links more quickly than within function context (as described in Prefer using the Objects API where possible).
- Ensure Ontology backend service calls are done in parallel to avoid sequential loads. If you have multiple
async/awaitcalls, usePromise.allto await all the calls in parallel. - For example, a common pattern is to use
.map()on a list to create Promises, then usePromise.allon the resulting list. - Important: Using
Promise.all()improves execution speed but does not reduce resource consumption or cost. You still make the same number of operations—they just run in parallel. Bulk operations are both faster and more cost-effective. - Avoid unnecessary nested loops, which can increase execution time.
Choose efficient input types¶
When designing functions, the type of input parameter you choose significantly affects performance. Use the most efficient input type that meets your requirements.
Best practice: Use object sets when possible for maximum efficiency and scalability. Acceptable: Use object arrays when you need to work with objects in memory. Anti-pattern: Single object parameters should only be used when your object type contains just one instance or when specific business logic genuinely requires per-object processing.
| Input type | Efficiency | Use case |
|---|---|---|
| Object set | Best | Queryable set of objects; no upfront loading cost if you only need aggregations |
| Object array | Good | When you need to iterate over specific objects |
| Single object | Least efficient | When business logic requires processing one object at a time |
Best practice: Object sets¶
Objects passed as parameters trigger Ontology queries to load the object data. Even a single object input triggers a call to load that object into memory.
Object sets are preferable because they defer loading until you actually need the data. If you only need an aggregation (like count or sum), the Ontology backend computes it without loading individual objects.
```python tab="Python" from functions.api import function, Float from ontology_sdk.ontology.objects import ExampleDataAircraft from ontology_sdk.ontology.object_sets import ExampleDataAircraftObjectSet
Less efficient: Single object triggers upfront loading¶
@function() def get_aircraft_name(aircraft: ExampleDataAircraft) -> str: return aircraft.display_name
Moderate: Array of objects triggers upfront loading¶
@function() def get_aircrafts_names(aircraft_array: list[ExampleDataAircraft]) -> list[str]: return [aircraft.display_name for aircraft in aircraft_array]
Most efficient: Object set defers loading until needed¶
Here, only the aggregated value is loaded in memory of the function¶
@function() def count_aircrafts(aircraft_set: ExampleDataAircraftObjectSet) -> Float: return aircraft_set.count().compute()
```typescript tab="TypeScript v2"
// getAircraftName.ts - Less efficient: Single object triggers upfront loading
import { Osdk } from "@osdk/client";
import { ExampleDataAircraft } from "@ontology/sdk";
export default function getAircraftName(aircraft: Osdk.Instance<ExampleDataAircraft>): string {
return aircraft.displayName!;
}
// getAircraftsNames.ts - Moderate: Array of objects triggers upfront loading
import { Osdk } from "@osdk/client";
import { ExampleDataAircraft } from "@ontology/sdk";
export default function getAircraftsNames(aircraftArray: Osdk.Instance<ExampleDataAircraft>[]): string[] {
return aircraftArray.map(e => e.displayName!);
}
// countAircrafts.ts - Most efficient: Object set defers loading until needed
// Here, only the aggregated value is loaded in memory of the function
import { ObjectSet } from "@osdk/client";
import { Integer } from "@osdk/functions";
import { ExampleDataAircraft } from "@ontology/sdk";
export default async function countAircrafts(aircraftSet: ObjectSet<ExampleDataAircraft>): Promise<Integer> {
const result = await aircraftSet.aggregate({
$select: { $count: "unordered" }
});
return result.$count;
}
```typescript tab="TypeScript v1" import { Function, Integer } from "@foundry/functions-api"; import { ObjectSet, ExampleDataAircraft } from "@foundry/ontology-api";
export class MyFunctions { // Less efficient: Single object triggers upfront loading @Function() public getAircraftName(aircraft: ExampleDataAircraft): string { return aircraft.displayName!; }
// Moderate: Array of objects triggers upfront loading
@Function()
public getAircraftsNames(aircraftArray: ExampleDataAircraft[]): string[] {
return aircraftArray.map(e => e.displayName!);
}
// Most efficient: Object set defers loading until needed
// Here, only the aggregated value is loaded in memory of the function
@Function()
public async countAircrafts(aircraftSet: ObjectSet<ExampleDataAircraft>): Promise<Integer> {
const count = await aircraftSet.count();
return count!;
}
} ```
Load objects efficiently¶
The common source of performance issues in functions comes from loading objects inefficiently. Loading objects one at a time in a loop causes a round-trip to the ontology on each iteration.
Anti-pattern: Loading objects one by one¶
Loading objects inside a loop is an anti-pattern that significantly impacts performance. Each iteration makes a separate query to the Ontology: ```python tab="Python" from functions.api import function from ontology_sdk import FoundryClient from ontology_sdk.ontology.objects import ExampleDataAircraft
Anti-pattern: Objects loaded one by one in a loop¶
@function() def for_loop_worst(pks_list: list[str]) -> int: client = FoundryClient() seats_count = 0 for current_pk in pks_list: aircrafts = client.ontology.objects.ExampleDataAircraft.where( ExampleDataAircraft.object_type.tail_number == current_pk ).page() aircraft = aircrafts.data[0] seats_count += aircraft.number_of_seats or 0 return seats_count
Better: Load all objects in one call, then iterate¶
@function() def for_loop_better(pks_list: list[str]) -> int: client = FoundryClient() seats_count = 0 aircrafts = client.ontology.objects.ExampleDataAircraft.where( ExampleDataAircraft.object_type.tail_number.in_(pks_list) ) for aircraft in aircrafts: seats_count += aircraft.number_of_seats or 0 return seats_count
Best: Let the backend perform the aggregation¶
@function() def for_loop_best(pks_list: list[str]) -> int: client = FoundryClient() result = client.ontology.objects.ExampleDataAircraft.where( ExampleDataAircraft.object_type.tail_number.in_(pks_list) ).sum(ExampleDataAircraft.object_type.number_of_seats).compute() return int(result or 0) ```
```typescript tab="TypeScript v2" // forLoopWorst.ts - Anti-pattern: Objects loaded one by one in a loop import { Client, Osdk } from "@osdk/client"; import { ExampleDataAircraft } from "@ontology/sdk"; import { Integer } from "@osdk/functions";
export default async function forLoopWorst(client: Client, pks_list: string[]): Promise
for (const currentPk of pks_list) {
const fetchedPage = await client(ExampleDataAircraft).where({
tailNumber: { $eq: currentPk }
}).fetchPage();
const aircraft = fetchedPage.data[0];
seatsCount += aircraft?.numberOfSeats ?? 0;
}
return seatsCount;
}
// forLoopBetter.ts - Better: Load all objects in one call, then iterate import { Client, Osdk } from "@osdk/client"; import { ExampleDataAircraft } from "@ontology/sdk"; import { Integer } from "@osdk/functions";
export default async function forLoopBetter(client: Client, pks_list: string[]): Promise
const allObjects = client(ExampleDataAircraft).where({
tailNumber: { $in: pks_list }
});
for await (const currentObject of allObjects.asyncIter()) {
seatsCount += currentObject?.numberOfSeats ?? 0;
}
return seatsCount;
}
// forLoopBest.ts - Best: Let the backend perform the aggregation import { Client } from "@osdk/client"; import { ExampleDataAircraft } from "@ontology/sdk"; import { Integer } from "@osdk/functions";
export default async function forLoopBest(client: Client, pks_list: string[]): Promise
return result.numberOfSeats.sum!;
}
typescript tab="TypeScript v1"
import { Function, Integer } from "@foundry/functions-api";
import { Objects, ExampleDataAircraft } from "@foundry/ontology-api";
export class MyFunctions {
// Anti-pattern: Objects loaded one by one in a loop
@Function()
public forLoopWorst(pks_list: string[]): Integer {
let seatsCount = 0;
for (const currentPk of pks_list) {
const aircraft = Objects.search()
.exampleDataAircraft()
.filter(o => o.tailNumber.exactMatch(currentPk))
.all()[0];
seatsCount += aircraft.numberOfSeats ?? 0;
}
return seatsCount;
}
// Better: Bulk load objects, then iterate
@Function()
public forLoopBetter(pks_list: string[]): Integer {
const allObjects = Objects.search()
.exampleDataAircraft()
.filter(o => o.tailNumber.exactMatch(...pks_list))
.all();
let seatsCount = 0;
for (const currentObject of allObjects) {
seatsCount += currentObject.numberOfSeats ?? 0;
}
return seatsCount;
}
// Best: Let the backend perform the aggregation
@Function()
public async forLoopBest(pks_list: string[]): Promise
Best practice: Backend aggregations¶
When you need to compute aggregates like counts, sums, or averages, use the Ontology backend's aggregation capabilities instead of loading objects and computing in your function.
Prefer using the Objects API where possible¶
A common paradigm when using Workshop's derived properties is to calculate the property value by aggregating over each object's links (for example, counting the number of related objects).
Although the code below works, the function itself must retrieve all linked objects, and then perform an aggregation (in this case, calculating the length):
@Function()
public async getEmployeeProjectCount(employees: Employee[]): Promise<FunctionsMap<Employee, Integer>> {
const promises = employees.map(employee => employee.workHistory.allAsync());
const allEmployeeProjects = await Promise.all(promises);
let functionsMap = new FunctionsMap();
for (let i = 0; i < employees.length; i++) {
functionsMap.set(employees[i], allEmployeeProjects[i].length);
}
return functionsMap;
}
While the above takes advantage of the async API and asynchronous functions (see Optimizing link traversals), it's often beneficial to use the aggregation methods provided by the Objects API:
@Function()
public async getEmployeeProjectCount(employees: Employee[]): Promise<FunctionsMap<Employee, Integer>> {
const result: FunctionsMap<Employee, Integer> = new FunctionsMap();
// Get all projects that have an employeeId matching from the employees parameter, then count how many projects are mapped to each employeeId
const aggregation = await Objects.search().project()
.filter(project => project.employeeId.exactMatch(...employees.map(employee => employee.id)))
.groupBy(project => project.employeeId.byFixedWidths(1))
.count();
const map = new Map();
aggregation.buckets.forEach(bucket => {
// bucket.key.min represents the employeeId as each bucket size is 1.
map.set(bucket.key.min, bucket.value);
});
employees.forEach(employee => {
const value = map.get(employee.primaryKey);
if (value === undefined) {
return;
}
result.set(employee, value);
});
return result;
}
In this way, you can perform the aggregation in a single step without needing to pull in all linked projects first.
:::callout{theme="neutral"}
Note that the usual limitations of aggregations still apply. In particular, .topValues() on string IDs will only return the top 1000 values. Aggregations are currently limited to a maximum of 10K buckets, so you may need to perform multiple aggregations to retrieve the desired result. See Computing Aggregations for more details.
:::
Optimizing link traversals¶
The most common source of performance issues in functions comes from traversing links in an inefficient manner. Often, this occurs when you write code that loops over many objects and calls an API to load related objects on every iteration of the loop.
for (const employee of employees) {
const pastProjects = employee.workHistory.all();
}
In this example, each iteration of the loop will load an individual employee's past projects, causing a round-trip to the database. To avoid this slowdown, you can use the asynchronous link traversal APIs (getAsync() and allAsync()) when traversing many links at once. Below is an example of a function that is written to load links asynchronously:
@Function()
public async findEmployeeWithMostProjects(employees: Employee[]): Promise<Employee> {
// Create a Promise to load projects for each employee
const promises = employees.map(employee => employee.workHistory.allAsync());
// Dispatch all the promises, which will load all links in parallel
const allEmployeeProjects = await Promise.all(promises);
// Iterate through the results to find the employee who has the greatest number of projects
let result;
let maxProjectsLength;
for (let i = 0; i < employees.length; i++) {
const employee = employees[i];
const projects = allEmployeeProjects[i];
if (!result || projects.length > maxProjectsLength) {
result = employee;
maxProjectsLength = projects.length;
}
}
return result;
}
This example uses an ES6 async function ↗, which makes it convenient to handle the Promise return values that are returned from the .getAsync() and .allAsync() methods.
Understand async operations and resource usage¶
Asynchronous operations can speed up function execution, but they may not reduce resource usage. Understanding this distinction is important for cost optimization.
```python tab="Python" from functions.api import function, Float from ontology_sdk.ontology.object_sets import ExampleDataAircraftObjectSet
Best: Bulk operation using search around¶
@function def bulk_processing(aircraft_set: ExampleDataAircraftObjectSet) -> Float: all_maintenance_events = aircraft_set.search_around_example_data_aircraft_maintenance_event() return all_maintenance_events.count().compute()
```typescript tab="TypeScript v2"
// forLoopAsync.ts - Faster execution, but still multiple Ontology calls
import { Client, ObjectSet, Osdk } from "@osdk/client";
import { ExampleDataAircraft } from "@ontology/sdk";
import { Integer } from "@osdk/functions";
async function getMaintenanceEventCount(
client: Client,
aircraft: Osdk.Instance<ExampleDataAircraft>
): Promise<Integer> {
const aircraftSet = client(ExampleDataAircraft).where({
tailNumber: { $eq: aircraft.tailNumber }
});
const maintenanceEvents = aircraftSet.pivotTo("exampleDataAircraftMaintenanceEvent");
const result = await maintenanceEvents.aggregate({
$select: { $count: "unordered" }
});
return result.$count ?? 0;
}
export default async function forLoopAsync(
client: Client,
aircraftSet: ObjectSet<ExampleDataAircraft>
): Promise<Integer> {
const allObjects: Osdk.Instance<ExampleDataAircraft>[] = [];
for await (const obj of aircraftSet.asyncIter()) {
allObjects.push(obj);
}
const futures = allObjects.map(obj => getMaintenanceEventCount(client, obj));
const results = await Promise.all(futures);
return results.reduce((sum, count) => sum + count, 0);
}
// bulkProcessing.ts - Best: Single Ontology operation
import { ObjectSet } from "@osdk/client";
import { ExampleDataAircraft } from "@ontology/sdk";
import { Integer } from "@osdk/functions";
export default async function bulkProcessing(
aircraftSet: ObjectSet<ExampleDataAircraft>
): Promise<Integer> {
const allMaintenanceEvents = aircraftSet.pivotTo("exampleDataAircraftMaintenanceEvent");
const result = await allMaintenanceEvents.aggregate({
$select: { $count: "unordered" }
});
return result.$count ?? 0;
}
```typescript tab="TypeScript v1" import { Function, Integer } from "@foundry/functions-api"; import { ObjectSet, ExampleDataAircraft } from "@foundry/ontology-api"; import { Objects } from "@foundry/ontology-api";
export class MyFunctions {
private async getMaintenanceEventCount(aircraft: ExampleDataAircraft): Promise
// Faster execution, but still multiple Ontology calls
@Function()
public async forLoopAsync(aircraftSet: ObjectSet<ExampleDataAircraft>): Promise<Integer> {
const allObjects = aircraftSet.all();
const futures = allObjects.map(obj => this.getMaintenanceEventCount(obj));
const results = await Promise.all(futures);
return results.reduce((sum, count) => sum + count, 0);
}
// Best: Single Ontology operation
@Function()
public async bulkProcessing(aircraftSet: ObjectSet<ExampleDataAircraft>): Promise<Integer> {
const allMaintenanceEvents = aircraftSet.searchAroundExampleDataAircraftMaintenanceEvent();
return await allMaintenanceEvents.count() ?? 0;
}
}
``
:::callout{theme="warning" title="Async operations improve speed, not cost"}
Using asynchronous operations likePromise.all()` can improve execution speed by running operations in parallel. However, it is important to understand that async operations do not reduce resource consumption or cost—they just make things faster.
For example, parallelizing a loop of individual queries is faster than running them sequentially, but you are still making the same number of queries. Bulk operations that push computation to the backend are both faster and more resource-effective than either approach.
:::
Write efficient ontology edits¶
When writing functions that edit objects, apply the same bulk-loading principles. Load all objects upfront rather than one at a time.
Editing large set of objects¶
When editing large numbers of objects, use pagination (explicit or implicit via iterate or asyncIter) to process them in manageable chunks without loading everything into memory at once.
```python tab="Python"
from functions.api import function, OntologyEdit
from ontology_sdk.ontology.objects import ExampleDataAircraft
from ontology_sdk.ontology.object_sets import ExampleDataAircraftObjectSet
from ontology_sdk import FoundryClient
Single object edit¶
@function(edits=[ExampleDataAircraft]) def edit_aircraft_name(aircraft: ExampleDataAircraft) -> list[OntologyEdit]: ontology_edits = FoundryClient().ontology.edits() editable = ontology_edits.objects.ExampleDataAircraft.edit(aircraft) editable.display_name = "new display name" return ontology_edits.get_edits()
Bulk edit using object set with iteration¶
@function(edits=[ExampleDataAircraft]) def edit_all_aircrafts(aircraft_set: ExampleDataAircraftObjectSet) -> list[OntologyEdit]: ontology_edits = FoundryClient().ontology.edits() for aircraft in aircraft_set.iterate(): editable = ontology_edits.objects.ExampleDataAircraft.edit(aircraft) editable.display_name = "new display name" return ontology_edits.get_edits()
Alternative: Pagination¶
This processes objects in chunks. The iterate() method above takes care of it behind the scenes.¶
@function(edits=[ExampleDataAircraft]) def edit_all_with_pagination(aircraft_set: ExampleDataAircraftObjectSet) -> list[OntologyEdit]: edits = FoundryClient().ontology.edits() next_token = None while True: page = aircraft_set.page(1000, next_token) for aircraft in page.data: editable = edits.objects.ExampleDataAircraft.edit(aircraft) editable.status = "reviewed" next_token = page.next_page_token if not next_token: break return edits.get_edits() ```
```typescript tab="TypeScript v2" // editAircraftName.ts - Single object edit import { Osdk, Client } from "@osdk/client"; import { ExampleDataAircraft } from "@ontology/sdk"; import { Edits, createEditBatch } from "@osdk/functions";
type OntologyEdit = Edits.Object
export default async function editAircraftName(
client: Client,
aircraft: Osdk.Instance
// editAllAircrafts.ts - Bulk edit using object set import { Client, ObjectSet } from "@osdk/client"; import { ExampleDataAircraft } from "@ontology/sdk"; import { Edits, createEditBatch } from "@osdk/functions";
type OntologyEdit = Edits.Object
export default async function editAllAircrafts(
client: Client,
aircraftSet: ObjectSet
for await (const aircraft of aircraftSet.asyncIter()) {
batch.update(aircraft, { displayName: "new display name" });
}
return batch.getEdits();
}
typescript tab="TypeScript v1"
import { Function, OntologyEditFunction, Edits } from "@foundry/functions-api";
import { ObjectSet, ExampleDataAircraft } from "@foundry/ontology-api";
export class MyFunctions {
// Single object edit
@Edits(ExampleDataAircraft)
@OntologyEditFunction()
public editAircraftName(aircraft: ExampleDataAircraft): void {
aircraft.displayName = "new display name";
}
// Array edit
@Edits(ExampleDataAircraft)
@OntologyEditFunction()
public editAircraftsNames(aircraftArray: ExampleDataAircraft[]): void {
aircraftArray.forEach(aircraft => {
aircraft.displayName = "new display name";
});
}
// Object set edit - most efficient when you need to edit many objects
@Edits(ExampleDataAircraft)
@OntologyEditFunction()
public editAllAircrafts(aircraftSet: ObjectSet
Optimize derived column generation¶
Workshop supports computing derived properties using functions on objects (FOO). Workshop applications typically call these functions with a few dozen rows of content from an object table. The function then returns a map where each object is mapped to the display value in the derived column.
Base implementation without optimization¶
Below is a non-optimized implementation that serves as the base case:
import { Function, FunctionsMap, Double } from "@foundry/functions-api";
import { Objects, ObjectSet, objectTypeA } from "@foundry/ontology-api";
export class MyFunctions {
/**
* This Function takes an ObjectSet as input, and generates a derived column as output.
* This derived column maps each object instance to the numeric value that will populate the column.
* This implementation is a trivial for-loop that multiplies an object property by a constant value.
* This serves as the base case that we will improve below.
*/
@Function()
public getDerivedColumn_noOptimization(objects: ObjectSet<objectTypeA>, scalar: Double): FunctionsMap<objectTypeA, Double> {
// Define the result map to return
const resultMap = new FunctionsMap<objectTypeA, Double>();
/* There is a limit to the number of objects that can be loaded in memory.
* See enforced limit documentation for current object set load limits.
*/
const allObjs: objectTypeA[] = objects.all();
// For each loaded object, perform the computation. If the result is defined, store it in the result map.
allObjs.forEach(o => {
const result = this.computeForThisObject(o, scalar);
if (result) {
resultMap.set(o, result);
}
});
return resultMap;
}
// An example of a function that computes the required value for the provided object.
private computeForThisObject(obj: objectTypeA, scalar: Double): Double | undefined {
if (scalar === 0) {
// Division by zero error
return undefined;
}
// Checks if exampleProperty is defined, and divides if so. If not, it returns undefined.
return obj.exampleProperty ? obj.exampleProperty / scalar : undefined;
}
}
Parallel execution optimization¶
If the computation is complex, it is possible to reduce compute time by using asynchronous execution. This way, computations for each object are executed in parallel:
import { Function, FunctionsMap, Double } from "@foundry/functions-api";
import { Objects, ObjectSet, objectTypeA, objectTypeB } from "@foundry/ontology-api";
/**
* This function takes a list of strings that are object primaryKeys as input, and generates a derived column as output.
*/
@Function()
public async getDerivedColumn_parallel(objects: ObjectSet<objectTypeA>, scalar: Double): Promise<FunctionsMap<objectTypeA, Double>> {
// Define the result map
const resultMap = new FunctionsMap<objectTypeA, Double>();
/* There is a limit to the number of objects that can be loaded in memory.
* See enforced limit documentation for current object set load limits.
* This should not be a problem as Workshop can lazy-load as users are scrolling.
*/
const allObjs: objectTypeA[] = objects.all();
// Launch parallel computations for each object in the array
const promises = allObjs.map(currObject => this.computeForThisObject(currObject, scalar));
// Use Promise.all to parallelize async execution of helper function
const allResolvedPromises = await Promise.all(promises);
// Populate resultMap with results
for (let i = 0; i < allObjs.length; i++) {
resultMap.set(allObjs[i], allResolvedPromises[i]);
}
return resultMap;
}
// An example of a function that computes the required value for the provided object.
private async computeForThisObject(obj: objectTypeA, scalar: Double): Promise<Double | undefined> {
if (scalar === 0) {
// Division by zero error
return undefined;
}
// Checks if exampleProperty is defined, and divides if so. If not, it returns undefined.
return obj.exampleProperty ? obj.exampleProperty / scalar : undefined;
}
Advanced: Ontology filtering within computation¶
For more complex cases where each object requires querying the Ontology, see the below examples.
Note: The same applies with a TwoDimensionalAggregation that would populate a Chart XY widget in Workshop. You can pass a list of category strings (buckets) to compute, instead of a list of object instances. Below is an example:
/**
* An example of a function that computes the required value for the provided object.
* For a given object, query the Ontology (filter for other objects, search-around to another object set, etc.)
*/
@Function()
private async computeForThisObject_filterOntology(obj: objectTypeA): Promise<Double> {
// Create an object set by filtering on some properties
const currObjectSet = await Objects.search().objectTypeB().filter(o => o.property.exactMatch(obj.exampleProperty));
// Note: If there is an existing link between the ObjectTypes, an alternative would be:
// const currObjectSet = await Objects.search().objectTypeA([obj]).searchAroundObjectTypeB();
// Compute the aggregation for this object set
return await this.computeMetric_B(currObjectSet);
}
@Function()
public async computeMetric_B(objs: ObjectSet<objectTypeB>): Promise<Double> {
// Set up calls to different parts of the equation
const promises = [this.sumValue(objs), this.sumValueIfPresent(objs)];
// Execute all promises
const allResolvedPromises = await Promise.all(promises);
// Get values from the promises
const sum = allResolvedPromises[0];
const sumIfPresent = allResolvedPromises[1];
// Perform calculation
return sum / sumIfPresent;
}
@Function()
public async sumValue(objs: ObjectSet<objectTypeB>): Promise<Double> {
// Sum the values of the objects
const aggregation = await objs.sum(o => o.propertyToAggregateB);
const firstBucketValue = aggregation.primaryKeys[0].value;
return firstBucketValue;
}
@Function()
public async sumValueIfPresent(objs: ObjectSet<objectTypeB>): Promise<Double> {
// Sum the object values if they are not null
const aggregation = await objs.filter(o => o.metric.hasProperty()).sum(o => o.propertyToAggregateA);
const firstBucketValue = aggregation.primaryKeys[0].value;
return firstBucketValue;
}
Converting to TwoDimensionalAggregation¶
For use with Chart XY widgets in Workshop, you can convert a FunctionsMap to a TwoDimensionalAggregation:
@Function()
public async getDerivedColumn_parallel_asTwoDimensional(objects: ObjectSet<objectTypeA>, scalar: Double): Promise<TwoDimensionalAggregation<string>> {
const resultMap: FunctionsMap<objectTypeA, Double> = await this.getDerivedColumn_parallel(objects, scalar);
// Create a TwoDimensionalAggregation from the resultMap
const aggregation: TwoDimensionalAggregation<string> = {
// Map the entries (object -> Double) of resultMap to (string -> Double)
buckets: Array.from(resultMap.entries()).map(([key, value]) => ({
key: key.pkProperty, // Use the primary key property
value
})),
};
return aggregation;
}
中文翻译¶
优化性能¶
本文档描述了优化函数性能和资源使用的最佳实践。遵循这些指南有助于最小化计算消耗,并确保函数高效运行。
:::callout{theme="info"} 有关计算成本以及函数如何计量的信息,请参阅使用本体查询的计算用量。 :::
理解函数计算成本¶
函数的成本包含多个组成部分:
- 开销(Overhead): 每次函数执行都有固定的4计算秒(compute-seconds)开销,无论其执行什么操作。
- 计算时间(Compute time): 函数执行所需的vCPU时间。
- 外部调用(External calls): 对平台其他部分(本体查询、模型推理、LLM调用)的调用会产生各自的成本。
有关计算秒在平台中如何计算和计量的更多信息,请参阅用量类型。
使用性能选项卡¶
性能选项卡提供了一个工具,用于分析和识别函数的性能问题。
瀑布图将操作表示为在X轴上随时间延伸的水平条。每个操作都有标记,指示时间是如何消耗的。
- 执行函数(Execute function) 表示执行函数代码所花费的CPU时间。
- 从参数加载对象(Load objects from arguments) 和从链接加载对象(Load objects from links) 表示调用底层本体后端数据库服务(OSS)所花费的时间。
要改善函数性能:
- 使用对象API(Objects API)进行聚合和遍历链接,比在函数上下文中更快(如尽可能使用对象API中所述)。
- 确保本体后端服务调用并行执行,避免顺序加载。如果有多个
async/await调用,请使用Promise.all来并行等待所有调用。 - 例如,常见模式是在列表上使用
.map()创建Promises,然后在结果列表上使用Promise.all。 - 重要提示: 使用
Promise.all()可以提高执行速度,但不会减少资源消耗或成本。您仍然执行相同数量的操作——只是它们并行运行。批量操作既更快又更具成本效益。 - 避免不必要的嵌套循环,这会增加执行时间。
选择高效的输入类型¶
设计函数时,选择的输入参数类型会显著影响性能。使用满足需求的最有效输入类型。
最佳实践: 尽可能使用对象集(object sets)以获得最高效率和可扩展性。 可接受: 当需要在内存中处理对象时,使用对象数组(object arrays)。 反模式: 仅当对象类型只包含一个实例,或特定业务逻辑确实需要逐个对象处理时,才应使用单个对象参数。
| 输入类型 | 效率 | 使用场景 |
|---|---|---|
| 对象集(Object set) | 最佳 | 可查询的对象集合;如果只需要聚合,则无需预先加载成本 |
| 对象数组(Object array) | 良好 | 当需要遍历特定对象时 |
| 单个对象(Single object) | 效率最低 | 当业务逻辑需要一次处理一个对象时 |
最佳实践:对象集¶
作为参数传递的对象会触发本体查询来加载对象数据。即使是单个对象输入也会触发调用,将该对象加载到内存中。
对象集更可取,因为它们会延迟加载,直到您实际需要数据时才进行。如果您只需要聚合(如计数或求和),本体后端会在不加载单个对象的情况下进行计算。
```python tab="Python" from functions.api import function, Float from ontology_sdk.ontology.objects import ExampleDataAircraft from ontology_sdk.ontology.object_sets import ExampleDataAircraftObjectSet
效率较低:单个对象触发预先加载¶
@function() def get_aircraft_name(aircraft: ExampleDataAircraft) -> str: return aircraft.display_name
中等:对象数组触发预先加载¶
@function() def get_aircrafts_names(aircraft_array: list[ExampleDataAircraft]) -> list[str]: return [aircraft.display_name for aircraft in aircraft_array]
效率最高:对象集延迟加载,直到需要时才进行¶
这里,只有聚合值被加载到函数内存中¶
@function() def count_aircrafts(aircraft_set: ExampleDataAircraftObjectSet) -> Float: return aircraft_set.count().compute()
```typescript tab="TypeScript v2"
// getAircraftName.ts - 效率较低:单个对象触发预先加载
import { Osdk } from "@osdk/client";
import { ExampleDataAircraft } from "@ontology/sdk";
export default function getAircraftName(aircraft: Osdk.Instance<ExampleDataAircraft>): string {
return aircraft.displayName!;
}
// getAircraftsNames.ts - 中等:对象数组触发预先加载
import { Osdk } from "@osdk/client";
import { ExampleDataAircraft } from "@ontology/sdk";
export default function getAircraftsNames(aircraftArray: Osdk.Instance<ExampleDataAircraft>[]): string[] {
return aircraftArray.map(e => e.displayName!);
}
// countAircrafts.ts - 效率最高:对象集延迟加载,直到需要时才进行
// 这里,只有聚合值被加载到函数内存中
import { ObjectSet } from "@osdk/client";
import { Integer } from "@osdk/functions";
import { ExampleDataAircraft } from "@ontology/sdk";
export default async function countAircrafts(aircraftSet: ObjectSet<ExampleDataAircraft>): Promise<Integer> {
const result = await aircraftSet.aggregate({
$select: { $count: "unordered" }
});
return result.$count;
}
```typescript tab="TypeScript v1" import { Function, Integer } from "@foundry/functions-api"; import { ObjectSet, ExampleDataAircraft } from "@foundry/ontology-api";
export class MyFunctions { // 效率较低:单个对象触发预先加载 @Function() public getAircraftName(aircraft: ExampleDataAircraft): string { return aircraft.displayName!; }
// 中等:对象数组触发预先加载
@Function()
public getAircraftsNames(aircraftArray: ExampleDataAircraft[]): string[] {
return aircraftArray.map(e => e.displayName!);
}
// 效率最高:对象集延迟加载,直到需要时才进行
// 这里,只有聚合值被加载到函数内存中
@Function()
public async countAircrafts(aircraftSet: ObjectSet<ExampleDataAircraft>): Promise<Integer> {
const count = await aircraftSet.count();
return count!;
}
} ```
高效加载对象¶
函数性能问题的常见来源是低效地加载对象。在循环中逐个加载对象会导致每次迭代都往返于本体。
反模式:逐个加载对象¶
在循环内部加载对象是一种反模式,会显著影响性能。每次迭代都会对本体进行单独的查询: ```python tab="Python" from functions.api import function from ontology_sdk import FoundryClient from ontology_sdk.ontology.objects import ExampleDataAircraft
反模式:在循环中逐个加载对象¶
@function() def for_loop_worst(pks_list: list[str]) -> int: client = FoundryClient() seats_count = 0 for current_pk in pks_list: aircrafts = client.ontology.objects.ExampleDataAircraft.where( ExampleDataAircraft.object_type.tail_number == current_pk ).page() aircraft = aircrafts.data[0] seats_count += aircraft.number_of_seats or 0 return seats_count
较好:一次调用加载所有对象,然后遍历¶
@function() def for_loop_better(pks_list: list[str]) -> int: client = FoundryClient() seats_count = 0 aircrafts = client.ontology.objects.ExampleDataAircraft.where( ExampleDataAircraft.object_type.tail_number.in_(pks_list) ) for aircraft in aircrafts: seats_count += aircraft.number_of_seats or 0 return seats_count
最佳:让后端执行聚合¶
@function() def for_loop_best(pks_list: list[str]) -> int: client = FoundryClient() result = client.ontology.objects.ExampleDataAircraft.where( ExampleDataAircraft.object_type.tail_number.in_(pks_list) ).sum(ExampleDataAircraft.object_type.number_of_seats).compute() return int(result or 0) ```
```typescript tab="TypeScript v2" // forLoopWorst.ts - 反模式:在循环中逐个加载对象 import { Client, Osdk } from "@osdk/client"; import { ExampleDataAircraft } from "@ontology/sdk"; import { Integer } from "@osdk/functions";
export default async function forLoopWorst(client: Client, pks_list: string[]): Promise
for (const currentPk of pks_list) {
const fetchedPage = await client(ExampleDataAircraft).where({
tailNumber: { $eq: currentPk }
}).fetchPage();
const aircraft = fetchedPage.data[0];
seatsCount += aircraft?.numberOfSeats ?? 0;
}
return seatsCount;
}
// forLoopBetter.ts - 较好:一次调用加载所有对象,然后遍历 import { Client, Osdk } from "@osdk/client"; import { ExampleDataAircraft } from "@ontology/sdk"; import { Integer } from "@osdk/functions";
export default async function forLoopBetter(client: Client, pks_list: string[]): Promise
const allObjects = client(ExampleDataAircraft).where({
tailNumber: { $in: pks_list }
});
for await (const currentObject of allObjects.asyncIter()) {
seatsCount += currentObject?.numberOfSeats ?? 0;
}
return seatsCount;
}
// forLoopBest.ts - 最佳:让后端执行聚合 import { Client } from "@osdk/client"; import { ExampleDataAircraft } from "@ontology/sdk"; import { Integer } from "@osdk/functions";
export default async function forLoopBest(client: Client, pks_list: string[]): Promise
return result.numberOfSeats.sum!;
}
typescript tab="TypeScript v1"
import { Function, Integer } from "@foundry/functions-api";
import { Objects, ExampleDataAircraft } from "@foundry/ontology-api";
export class MyFunctions {
// 反模式:在循环中逐个加载对象
@Function()
public forLoopWorst(pks_list: string[]): Integer {
let seatsCount = 0;
for (const currentPk of pks_list) {
const aircraft = Objects.search()
.exampleDataAircraft()
.filter(o => o.tailNumber.exactMatch(currentPk))
.all()[0];
seatsCount += aircraft.numberOfSeats ?? 0;
}
return seatsCount;
}
// 较好:批量加载对象,然后遍历
@Function()
public forLoopBetter(pks_list: string[]): Integer {
const allObjects = Objects.search()
.exampleDataAircraft()
.filter(o => o.tailNumber.exactMatch(...pks_list))
.all();
let seatsCount = 0;
for (const currentObject of allObjects) {
seatsCount += currentObject.numberOfSeats ?? 0;
}
return seatsCount;
}
// 最佳:让后端执行聚合
@Function()
public async forLoopBest(pks_list: string[]): Promise
最佳实践:后端聚合¶
当需要计算计数、求和或平均值等聚合时,请使用本体后端的聚合功能,而不是加载对象并在函数中计算。
尽可能使用对象API¶
在使用Workshop的派生属性时,常见模式是通过聚合每个对象的链接来计算属性值(例如,计算相关对象的数量)。
虽然下面的代码可以工作,但函数本身必须检索所有链接的对象,然后执行聚合(在本例中,计算长度):
@Function()
public async getEmployeeProjectCount(employees: Employee[]): Promise<FunctionsMap<Employee, Integer>> {
const promises = employees.map(employee => employee.workHistory.allAsync());
const allEmployeeProjects = await Promise.all(promises);
let functionsMap = new FunctionsMap();
for (let i = 0; i < employees.length; i++) {
functionsMap.set(employees[i], allEmployeeProjects[i].length);
}
return functionsMap;
}
虽然上述代码利用了异步API和异步函数(参见优化链接遍历),但使用对象API提供的聚合方法通常更有利:
@Function()
public async getEmployeeProjectCount(employees: Employee[]): Promise<FunctionsMap<Employee, Integer>> {
const result: FunctionsMap<Employee, Integer> = new FunctionsMap();
// 获取所有employeeId与employees参数匹配的项目,然后计算每个employeeId映射了多少个项目
const aggregation = await Objects.search().project()
.filter(project => project.employeeId.exactMatch(...employees.map(employee => employee.id)))
.groupBy(project => project.employeeId.byFixedWidths(1))
.count();
const map = new Map();
aggregation.buckets.forEach(bucket => {
// bucket.key.min 表示employeeId,因为每个桶的大小为1
map.set(bucket.key.min, bucket.value);
});
employees.forEach(employee => {
const value = map.get(employee.primaryKey);
if (value === undefined) {
return;
}
result.set(employee, value);
});
return result;
}
通过这种方式,您可以在单个步骤中执行聚合,而无需先拉取所有链接的项目。
:::callout{theme="neutral"}
请注意,聚合的通常限制仍然适用。特别是,对字符串ID使用.topValues()只会返回前1000个值。聚合目前限制为最多10K个桶,因此您可能需要执行多个聚合才能检索到所需结果。有关更多详细信息,请参阅计算聚合。
:::
优化链接遍历¶
函数性能问题最常见的来源是以低效的方式遍历链接。通常,当您编写代码循环遍历许多对象,并在每次循环迭代中调用API加载相关对象时,就会发生这种情况。
for (const employee of employees) {
const pastProjects = employee.workHistory.all();
}
在此示例中,循环的每次迭代都会加载单个员工的过去项目,导致往返数据库。为避免这种减速,您可以在一次遍历多个链接时使用异步链接遍历API(getAsync()和allAsync())。下面是一个编写为异步加载链接的函数示例:
@Function()
public async findEmployeeWithMostProjects(employees: Employee[]): Promise<Employee> {
// 为每个员工创建一个加载项目的Promise
const promises = employees.map(employee => employee.workHistory.allAsync());
// 分发所有promises,这将并行加载所有链接
const allEmployeeProjects = await Promise.all(promises);
// 遍历结果,找到项目数量最多的员工
let result;
let maxProjectsLength;
for (let i = 0; i < employees.length; i++) {
const employee = employees[i];
const projects = allEmployeeProjects[i];
if (!result || projects.length > maxProjectsLength) {
result = employee;
maxProjectsLength = projects.length;
}
}
return result;
}
此示例使用了ES6 async函数 ↗,这使得处理从.getAsync()和.allAsync()方法返回的Promise返回值变得方便。
理解异步操作和资源使用¶
异步操作可以加快函数执行速度,但可能不会减少资源使用。理解这一区别对于成本优化很重要。
```python tab="Python" from functions.api import function, Float from ontology_sdk.ontology.object_sets import ExampleDataAircraftObjectSet
最佳:使用search around进行批量操作¶
@function def bulk_processing(aircraft_set: ExampleDataAircraftObjectSet) -> Float: all_maintenance_events = aircraft_set.search_around_example_data_aircraft_maintenance_event() return all_maintenance_events.count().compute()
```typescript tab="TypeScript v2"
// forLoopAsync.ts - 执行更快,但仍然有多个本体调用
import { Client, ObjectSet, Osdk } from "@osdk/client";
import { ExampleDataAircraft } from "@ontology/sdk";
import { Integer } from "@osdk/functions";
async function getMaintenanceEventCount(
client: Client,
aircraft: Osdk.Instance<ExampleDataAircraft>
): Promise<Integer> {
const aircraftSet = client(ExampleDataAircraft).where({
tailNumber: { $eq: aircraft.tailNumber }
});
const maintenanceEvents = aircraftSet.pivotTo("exampleDataAircraftMaintenanceEvent");
const result = await maintenanceEvents.aggregate({
$select: { $count: "unordered" }
});
return result.$count ?? 0;
}
export default async function forLoopAsync(
client: Client,
aircraftSet: ObjectSet<ExampleDataAircraft>
): Promise<Integer> {
const allObjects: Osdk.Instance<ExampleDataAircraft>[] = [];
for await (const obj of aircraftSet.asyncIter()) {
allObjects.push(obj);
}
const futures = allObjects.map(obj => getMaintenanceEventCount(client, obj));
const results = await Promise.all(futures);
return results.reduce((sum, count) => sum + count, 0);
}
// bulkProcessing.ts - 最佳:单个本体操作
import { ObjectSet } from "@osdk/client";
import { ExampleDataAircraft } from "@ontology/sdk";
import { Integer } from "@osdk/functions";
export default async function bulkProcessing(
aircraftSet: ObjectSet<ExampleDataAircraft>
): Promise<Integer> {
const allMaintenanceEvents = aircraftSet.pivotTo("exampleDataAircraftMaintenanceEvent");
const result = await allMaintenanceEvents.aggregate({
$select: { $count: "unordered" }
});
return result.$count ?? 0;
}
```typescript tab="TypeScript v1" import { Function, Integer } from "@foundry/functions-api"; import { ObjectSet, ExampleDataAircraft } from "@foundry/ontology-api"; import { Objects } from "@foundry/ontology-api";
export class MyFunctions {
private async getMaintenanceEventCount(aircraft: ExampleDataAircraft): Promise
// 执行更快,但仍然有多个本体调用
@Function()
public async forLoopAsync(aircraftSet: ObjectSet<ExampleDataAircraft>): Promise<Integer> {
const allObjects = aircraftSet.all();
const futures = allObjects.map(obj => this.getMaintenanceEventCount(obj));
const results = await Promise.all(futures);
return results.reduce((sum, count) => sum + count, 0);
}
// 最佳:单个本体操作
@Function()
public async bulkProcessing(aircraftSet: ObjectSet<ExampleDataAircraft>): Promise<Integer> {
const allMaintenanceEvents = aircraftSet.searchAroundExampleDataAircraftMaintenanceEvent();
return await allMaintenanceEvents.count() ?? 0;
}
}
``
:::callout{theme="warning" title="异步操作提高速度,而非降低成本"}
使用像Promise.all()`这样的异步操作可以通过并行运行操作来提高执行速度。然而,重要的是要理解异步操作不会减少资源消耗或成本——它们只是让事情变得更快。
例如,并行化单个查询的循环比顺序运行它们更快,但您仍然执行相同数量的查询。将计算推送到后端的批量操作比任何一种方法都更快且更节省资源。
:::
编写高效的本体编辑¶
在编写编辑对象的函数时,应用相同的批量加载原则。预先加载所有对象,而不是逐个加载。
编辑大量对象¶
当编辑大量对象时,使用分页(显式或通过iterate或asyncIter隐式)以可管理的块进行处理,而无需一次将所有内容加载到内存中。
```python tab="Python"
from functions.api import function, OntologyEdit
from ontology_sdk.ontology.objects import ExampleDataAircraft
from ontology_sdk.ontology.object_sets import ExampleDataAircraftObjectSet
from ontology_sdk import FoundryClient
单个对象编辑¶
@function(edits=[ExampleDataAircraft]) def edit_aircraft_name(aircraft: ExampleDataAircraft) -> list[OntologyEdit]: ontology_edits = FoundryClient().ontology.edits() editable = ontology_edits.objects.ExampleDataAircraft.edit(aircraft) editable.display_name = "new display name" return ontology_edits.get_edits()
使用对象集和迭代进行批量编辑¶
@function(edits=[ExampleDataAircraft]) def edit_all_aircrafts(aircraft_set: ExampleDataAircraftObjectSet) -> list[OntologyEdit]: ontology_edits = FoundryClient().ontology.edits() for aircraft in aircraft_set.iterate(): editable = ontology_edits.objects.ExampleDataAircraft.edit(aircraft) editable.display_name = "new display name" return ontology_edits.get_edits()
替代方案:分页¶
这会以块的形式处理对象。上面的iterate()方法在后台处理了这一点。¶
@function(edits=[ExampleDataAircraft]) def edit_all_with_pagination(aircraft_set: ExampleDataAircraftObjectSet) -> list[OntologyEdit]: edits = FoundryClient().ontology.edits() next_token = None while True: page = aircraft_set.page(1000, next_token) for aircraft in page.data: editable = edits.objects.ExampleDataAircraft.edit(aircraft) editable.status = "reviewed" next_token = page.next_page_token if not next_token: break return edits.get_edits() ```
```typescript tab="TypeScript v2" // editAircraftName.ts - 单个对象编辑 import { Osdk, Client } from "@osdk/client"; import { ExampleDataAircraft } from "@ontology/sdk"; import { Edits, createEditBatch } from "@osdk/functions";
type OntologyEdit = Edits.Object
export default async function editAircraftName(
client: Client,
aircraft: Osdk.Instance
// editAllAircrafts.ts - 使用对象集进行批量编辑 import { Client, ObjectSet } from "@osdk/client"; import { ExampleDataAircraft } from "@ontology/sdk"; import { Edits, createEditBatch } from "@osdk/functions";
type OntologyEdit = Edits.Object
export default async function editAllAircrafts(
client: Client,
aircraftSet: ObjectSet
for await (const aircraft of aircraftSet.asyncIter()) {
batch.update(aircraft, { displayName: "new display name" });
}
return batch.getEdits();
}
typescript tab="TypeScript v1"
import { Function, OntologyEditFunction, Edits } from "@foundry/functions-api";
import { ObjectSet, ExampleDataAircraft } from "@foundry/ontology-api";
export class MyFunctions {
// 单个对象编辑
@Edits(ExampleDataAircraft)
@OntologyEditFunction()
public editAircraftName(aircraft: ExampleDataAircraft): void {
aircraft.displayName = "new display name";
}
// 数组编辑
@Edits(ExampleDataAircraft)
@OntologyEditFunction()
public editAircraftsNames(aircraftArray: ExampleDataAircraft[]): void {
aircraftArray.forEach(aircraft => {
aircraft.displayName = "new display name";
});
}
// 对象集编辑 - 当需要编辑许多对象时效率最高
@Edits(ExampleDataAircraft)
@OntologyEditFunction()
public editAllAircrafts(aircraftSet: ObjectSet
优化派生列生成¶
Workshop支持使用对象函数(FOO)计算派生属性。Workshop应用程序通常使用对象表中的几十行内容调用这些函数。然后,函数返回一个映射,其中每个对象都映射到派生列中的显示值。
未优化的基础实现¶
下面是一个未优化的实现,作为基础案例:
import { Function, FunctionsMap, Double } from "@foundry/functions-api";
import { Objects, ObjectSet, objectTypeA } from "@foundry/ontology-api";
export class MyFunctions {
/**
* 此函数接受一个ObjectSet作为输入,并生成一个派生列作为输出。
* 此派生列将每个对象实例映射到将填充该列的数值。
* 此实现是一个简单的for循环,将对象属性乘以一个常量值。
* 这作为我们将要在下面改进的基础案例。
*/
@Function()
public getDerivedColumn_noOptimization(objects: ObjectSet<objectTypeA>, scalar: Double): FunctionsMap<objectTypeA, Double> {
// 定义要返回的结果映射
const resultMap = new FunctionsMap<objectTypeA, Double>();
/* 可以加载到内存中的对象数量有限制。
* 有关当前对象集加载限制,请参阅强制限制文档。
*/
const allObjs: objectTypeA[] = objects.all();
// 对于每个加载的对象,执行计算。如果结果已定义,则将其存储在结果映射中。
allObjs.forEach(o => {
const result = this.computeForThisObject(o, scalar);
if (result) {
resultMap.set(o, result);
}
});
return resultMap;
}
// 一个计算所提供对象所需值的函数示例。
private computeForThisObject(obj: objectTypeA, scalar: Double): Double | undefined {
if (scalar === 0) {
// 除以零错误
return undefined;
}
// 检查exampleProperty是否已定义,如果已定义则进行除法。如果未定义,则返回undefined。
return obj.exampleProperty ? obj.exampleProperty / scalar : undefined;
}
}
并行执行优化¶
如果计算很复杂,可以通过使用异步执行来减少计算时间。这样,每个对象的计算将并行执行:
import { Function, FunctionsMap, Double } from "@foundry/functions-api";
import { Objects, ObjectSet, objectTypeA, objectTypeB } from "@foundry/ontology-api";
/**
* 此函数接受一个对象primaryKeys字符串列表作为输入,并生成一个派生列作为输出。
*/
@Function()
public async getDerivedColumn_parallel(objects: ObjectSet<objectTypeA>, scalar: Double): Promise<FunctionsMap<objectTypeA, Double>> {
// 定义结果映射
const resultMap = new FunctionsMap<objectTypeA, Double>();
/* 可以加载到内存中的对象数量有限制。
* 有关当前对象集加载限制,请参阅强制限制文档。
* 由于Workshop可以在用户滚动时延迟加载,这应该不是问题。
*/
const allObjs: objectTypeA[] = objects.all();
// 为数组中的每个对象启动并行计算
const promises = allObjs.map(currObject => this.computeForThisObject(currObject, scalar));
// 使用Promise.all并行执行辅助函数的异步执行
const allResolvedPromises = await Promise.all(promises);
// 用结果填充resultMap
for (let i = 0; i < allObjs.length; i++) {
resultMap.set(allObjs[i], allResolvedPromises[i]);
}
return resultMap;
}
// 一个计算所提供对象所需值的函数示例。
private async computeForThisObject(obj: objectTypeA, scalar: Double): Promise<Double | undefined> {
if (scalar === 0) {
// 除以零错误
return undefined;
}
// 检查exampleProperty是否已定义,如果已定义则进行除法。如果未定义,则返回undefined。
return obj.exampleProperty ? obj.exampleProperty / scalar : undefined;
}
高级:计算中的本体过滤¶
对于每个对象需要查询本体的更复杂情况,请参见下面的示例。
注意: 同样的方法适用于TwoDimensionalAggregation,它将填充Workshop中的图表XY小部件。您可以传递一个类别字符串(桶)列表进行计算,而不是对象实例列表。下面是一个示例:
/**
* 一个计算所提供对象所需值的函数示例。
* 对于给定的对象,查询本体(过滤其他对象,search around到另一个对象集等)
*/
@Function()
private async computeForThisObject_filterOntology(obj: objectTypeA): Promise<Double> {
// 通过过滤某些属性创建一个对象集
const currObjectSet = await Objects.search().objectTypeB().filter(o => o.property.exactMatch(obj.exampleProperty));
// 注意:如果ObjectTypes之间存在现有链接,替代方案是:
// const currObjectSet = await Objects.search().objectTypeA([obj]).searchAroundObjectTypeB();
// 计算此对象集的聚合
return await this.computeMetric_B(currObjectSet);
}
@Function()
public async computeMetric_B(objs: ObjectSet<objectTypeB>): Promise<Double> {
// 设置对等式不同部分的调用
const promises = [this.sumValue(objs), this.sumValueIfPresent(objs)];
// 执行所有promises
const allResolvedPromises = await Promise.all(promises);
// 从promises中获取值
const sum = allResolvedPromises[0];
const sumIfPresent = allResolvedPromises[1];
// 执行计算
return sum / sumIfPresent;
}
@Function()
public async sumValue(objs: ObjectSet<objectTypeB>): Promise<Double> {
// 对对象的值求和
const aggregation = await objs.sum(o => o.propertyToAggregateB);
const firstBucketValue = aggregation.primaryKeys[0].value;
return firstBucketValue;
}
@Function()
public async sumValueIfPresent(objs: ObjectSet<objectTypeB>): Promise<Double> {
// 如果对象值不为空,则对其求和
const aggregation = await objs.filter(o => o.metric.hasProperty()).sum(o => o.propertyToAggregateA);
const firstBucketValue = aggregation.primaryKeys[0].value;
return firstBucketValue;
}
转换为TwoDimensionalAggregation¶
为了与Workshop中的图表XY小部件一起使用,您可以将FunctionsMap转换为TwoDimensionalAggregation:
@Function()
public async getDerivedColumn_parallel_asTwoDimensional(objects: ObjectSet<objectTypeA>, scalar: Double): Promise<TwoDimensionalAggregation<string>> {
const resultMap: FunctionsMap<objectTypeA, Double> = await this.getDerivedColumn_parallel(objects, scalar);
// 从resultMap创建一个TwoDimensionalAggregation
const aggregation: TwoDimensionalAggregation<string> = {
// 将resultMap的条目(object -> Double)映射为(string -> Double)
buckets: Array.from(resultMap.entries()).map(([key, value]) => ({
key: key.pkProperty, // 使用主键属性
value
})),
};
return aggregation;
}