Ontology architecture(本体架构)¶
The Foundry Ontology is an operational layer for the organization. The Ontology sits on top of the digital assets integrated into Foundry (datasets and models) and connects them to their real-world counterparts, ranging from physical assets like factories, equipment, and products to concepts like customer orders or financial transactions. The Ontology serves as a digital twin of an organization, containing both the semantic elements (objects, properties, links) and kinetic elements (actions, functions, dynamic security) needed to enable use cases of all types. You can learn more about the Foundry Ontology and how it enables better decision-making in the Ontology documentation.
The Foundry Ontology is backed by multiple services that work together to index, store, query, and manipulate objects in the Ontology. This page provides a high-level overview of the Ontology’s backend architecture.
Functional components and architecture¶
The Foundry platform uses a microservices architecture in which multiple services together comprise the Ontology backend. The Ontology backend is responsible for three main functions:
- Datasource management to feed the Ontology and manage schema definitions within the Ontology.
- Querying, searching, and aggregating objects from the Ontology with support for specific filtering and permissioning.
- Orchestration of writing to the Ontology, including indexing of datasources and edits to Ontology objects based on decisions made or actions taken in Foundry.
These functions are handled collectively by the services that make up the Ontology backend, which are summarized below:
- Ontology Metadata Service (OMS)
- Object databases
- Object Set Service (OSS)
- Actions
- Object Data Funnel
- Functions on Objects
Ontology Metadata Service (OMS)¶
The Ontology Metadata Service (OMS) is an overarching service that defines the set of ontological entities that exist. This definition includes the metadata of object types, the link types that describe any relationships between object types, the action types that can modify object data in a structured and controlled way, and more.
Learn more about core concepts in the Foundry Ontology in the Ontology metadata documentation.
Object databases¶
Object databases are the services responsible for storing the indexed object data in the Ontology and are designed to provide fast data querying and query computation for user applications. In addition to storing indexed data, object databases are also responsible for indexing, querying, and orchestrating user edits.
Object Storage V1 (Phonograph) is Foundry's legacy Ontology backend component. Object Storage V2 is the next-generation canonical data store for backing the Ontology. More information on these services can be found below.
Object Set Service (OSS)¶
The Object Set Service (OSS) is the service responsible for serving reads from the Ontology; OSS allows other Foundry services and applications to query objects data from the Ontology, enabling searching, filtering, aggregating, and loading of objects.
Object sets¶
Object sets are lists of real-world entities that are saved for future reference and use across Foundry applications that support objects. Object sets are saved as resources for easy sharing with collaborators.
Object sets can be described by definition (static or dynamic) and current state in the object backend (temporary or permanent):
-
Static object sets: Static object sets are saved as a list of primary keys, and will stay the same regardless of any changes to the input data.
-
Dynamic object sets: Dynamic object sets are saved as a representation of the filters applied to create the object set. When new data matches the filters, the object set will be updated.
-
Temporary object sets: Temporary object sets are mainly used in the platform to hand object sets from one application or service to another and can only be accessed by the user who created them. A sample temporary object set RID will appear like
ri.object-set.main.temporary-object-set.37d7e171-2d11-4fcd-b031-9a0863f6f744and expires within 24 hours. -
Permanent object sets: Permanent object sets are stored in the object backend for future reference and use across the platform.
Actions¶
The Actions service is responsible for applying user edits to object databases. Actions provide a structured way to modify property values of an object and enable complex permissions and conditions for user edits. Additionally, Actions can be used to create a historical action log for analysis of user decisions.
Object Data Funnel¶
The Object Data Funnel ("Funnel") is a microservice in the Object Storage V2 architecture responsible for orchestrating data writes into the Ontology. Funnel reads data from Foundry datasources (such as datasets, restricted views, and streaming datasources) and user edits (from Actions) and indexes these data into object databases. Funnel also ensures that indexed data is kept up-to-date as the underlying datasources update.
Functions on Objects¶
Functions enable code authors to write logic that can be executed quickly in operational contexts, such as dashboards and applications designed to power decision-making processes.
See the Functions documentation for more details.
Evolution of the Ontology backend¶
This section describes the legacy architecture of Object Storage V1 (Phonograph) and the updated architecture of Object Storage V2.
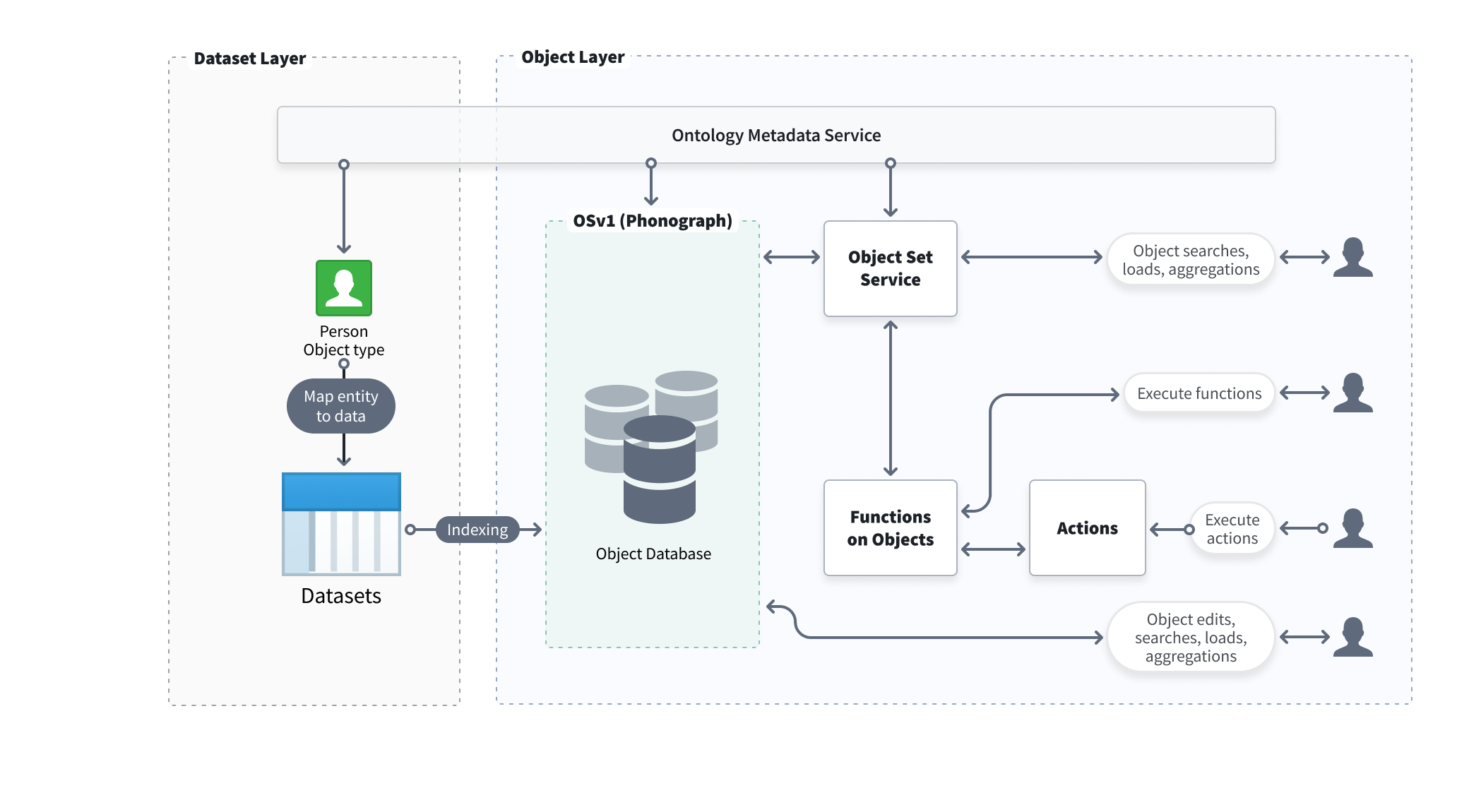
Object Storage V1 (Phonograph) architecture [Planned deprecation]¶
:::callout{theme="warning" title="Planned deprecation"}
Object Storage V1 (Phonograph) is in the planned deprecation phase of development and will be unavailable after June 30, 2026. Migrate your object types and link types to Object Storage V2. Reference the Migrate object types and many-to-many link types from Object Storage v1 to v2 intervention in Upgrade Assistant for more information.
Contact Palantir Support if you have questions about the OSv1 to OSv2 migration in your workflows.
:::
Object Storage V1 (Phonograph) is Foundry's original object database, designed to index and manage information from a wide range of potential data models while maintaining Foundry's security model across object data in the Ontology. Beyond indexing and storing data, Object Storage V1 (Phonograph) tracks the application of user-generated edits, serves complex user queries with searches and aggregations, and orchestrates data writeback.
Below is a diagram describing the architecture for Object Storage V1 (Phonograph).
Object Storage V2 architecture¶
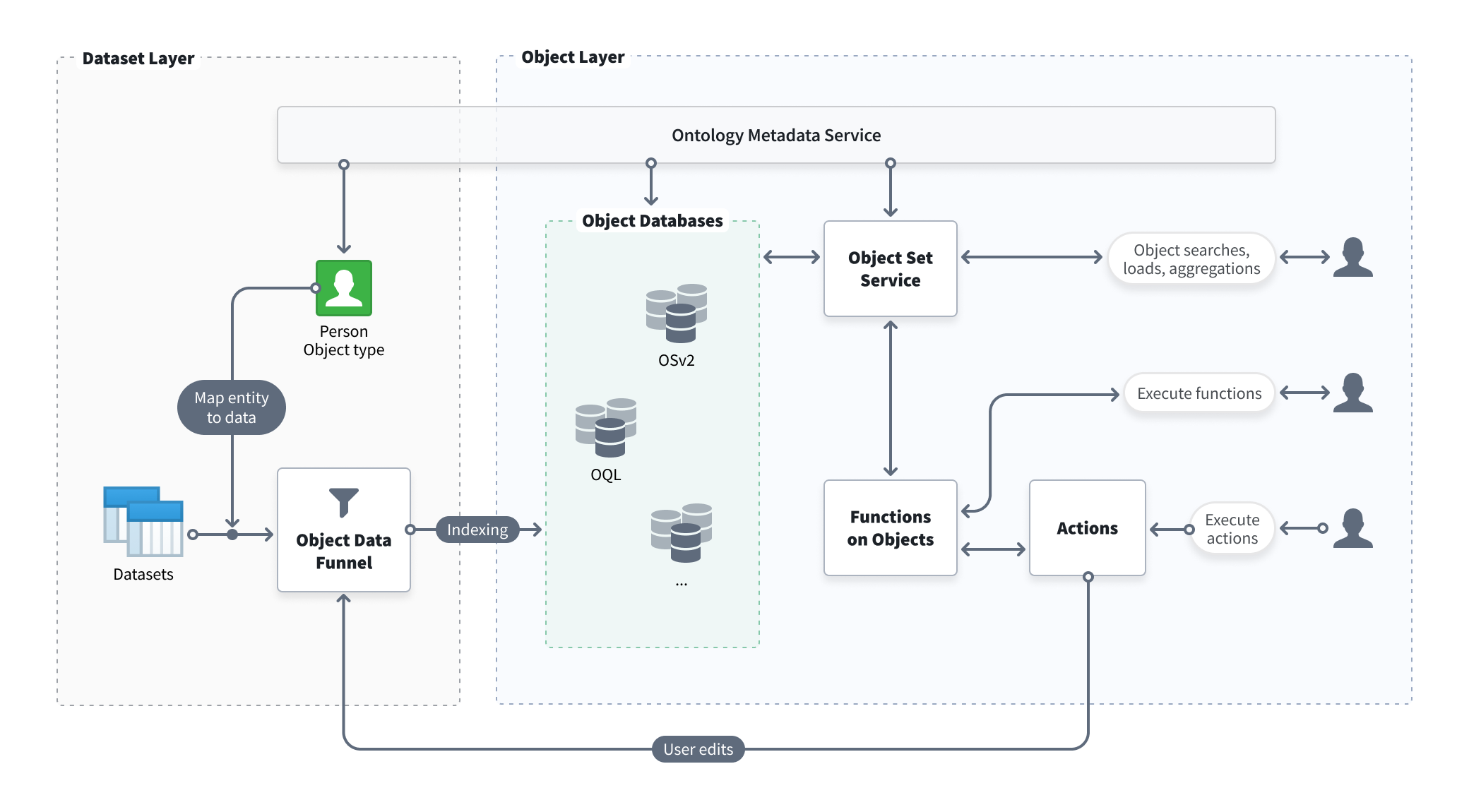
As Foundry gained more capabilities and evolved to meet the complex operational needs and growing scale of Palantir's customers, Object Storage V2 was built from first principles to enable the next generation of Ontology-driven use cases and workflows.
Specifically, the new architecture separates dimensions of concern that had been consolidated in Object Storage V1 (Phonograph) and decouples responsibilities within the system design; by separating the subsystems responsible for indexing and querying data, Object Storage V2 can scale horizontally more easily to meet future needs.
Object Storage V2 also incorporates additional services like Actions via the Object Data Funnel.
New features and capabilities enabled by Object Storage V2 include:
- Significantly improved performance for Ontology data indexing through incremental object indexing (enabled by default) for all object types.
- Increased indexing throughput on the order of tens of billions of objects for a single object type.
- More granular object permissions with multi-datasource object types, including column/property level permissions.
- Increased user edit throughput, enabling up to 10,000 objects to be edited in a single Action. If you need to enable a higher limit, contact Palantir Support to create a change request for your enrollment.
- Reduced user edit latency and faster observation of user edits.
- The ability to migrate existing user edits after a breaking schema change in an object type.
- Low-latency data indexing into the Ontology through support of streaming datasources.
- Supports a maximum of 2000 properties per object type.
- Higher-scale Search Arounds and more accurate aggregations through a Spark-based query execution layer.
- By default, the Search Around limit is 100,000 objects. If your use cases require a higher scale Search Around of over 100,000 objects, contact Palantir Support for instructions on how to enable this.
Below is an architecture diagram describing how Object Storage V2 powers the Ontology.
中文翻译¶
本体架构¶
Foundry 本体(Ontology)是组织的运营层。本体位于集成到 Foundry 中的数字资产(数据集和模型)之上,并将它们与现实世界的对应物连接起来,范围从工厂、设备和产品等物理资产到客户订单或金融交易等概念。本体充当组织的数字孪生,包含实现各类用例所需的语义元素(对象、属性、链接)和动态元素(操作、函数、动态安全)。您可以在本体文档中了解更多关于 Foundry 本体及其如何实现更优决策的信息。
Foundry 本体由多个服务共同支持,这些服务协同工作以索引、存储、查询和操作本体中的对象。本页面提供本体后端架构的高层概述。
功能组件与架构¶
Foundry 平台采用微服务架构,多个服务共同构成本体后端。本体后端负责三个主要功能:
- 数据源管理(Datasource management):为本体提供数据并管理本体内的模式定义。
- 查询、搜索和聚合对象(Querying, searching, and aggregating objects):从本体中查询对象,并支持特定的过滤和权限控制。
- 编排写入本体(Orchestration of writing to the Ontology):包括数据源索引以及基于 Foundry 中做出的决策或执行的操作对本体的编辑。
这些功能由构成本体后端的服务共同处理,概述如下:
- 本体元数据服务 (OMS)
- 对象数据库 (Object databases)
- 对象集服务 (OSS)
- 操作 (Actions)
- 对象数据漏斗 (Object Data Funnel)
- 对象函数 (Functions on Objects)
本体元数据服务 (OMS)¶
本体元数据服务(Ontology Metadata Service,OMS)是一项总体服务,用于定义存在的本体实体集合。该定义包括对象类型的元数据、描述对象类型之间关系的链接类型、能够以结构化和受控方式修改对象数据的操作类型等。
在本体元数据文档中了解更多关于 Foundry 本体核心概念的信息。
对象数据库¶
对象数据库(Object databases)是负责存储本体中已索引对象数据的服务,旨在为用户应用程序提供快速的数据查询和查询计算。除了存储已索引数据外,对象数据库还负责索引、查询和编排用户编辑。
对象存储 V1 (Phonograph) 是 Foundry 的旧版本体后端组件。对象存储 V2 是支持本体的下一代规范数据存储。有关这些服务的更多信息,请参见下文。
对象集服务 (OSS)¶
对象集服务(Object Set Service,OSS)是负责处理本体读取的服务;OSS 允许其他 Foundry 服务和应用程序从本体查询对象数据,支持对象的搜索、过滤、聚合和加载。
对象集¶
对象集(Object sets)是现实世界实体的列表,保存以供将来参考并在支持对象的 Foundry 应用程序中使用。对象集作为资源保存,便于与协作者共享。
对象集可以通过定义(静态或动态)和对象后端中的当前状态(临时或永久)来描述:
-
静态对象集(Static object sets): 静态对象集保存为主键列表,无论输入数据如何变化,其内容保持不变。
-
动态对象集(Dynamic object sets): 动态对象集保存为用于创建对象集的过滤条件的表示。当新数据匹配过滤条件时,对象集将更新。
-
临时对象集(Temporary object sets): 临时对象集主要用于平台中将对象集从一个应用程序或服务传递到另一个,并且只能由创建它们的用户访问。示例临时对象集 RID 格式如
ri.object-set.main.temporary-object-set.37d7e171-2d11-4fcd-b031-9a0863f6f744,并在 24 小时内过期。 -
永久对象集(Permanent object sets): 永久对象集存储在对象后端中,供将来参考并在整个平台中使用。
操作¶
操作服务(Actions)负责将用户编辑应用到对象数据库。操作提供了一种结构化的方式来修改对象的属性值,并为用户编辑启用复杂的权限和条件。此外,操作可用于创建历史操作日志,用于分析用户决策。
对象数据漏斗¶
对象数据漏斗(Object Data Funnel,"Funnel")是对象存储 V2 架构中的一个微服务,负责编排数据写入本体。Funnel 从 Foundry 数据源(如数据集、受限视图和流式数据源)以及用户编辑(来自操作)读取数据,并将这些数据索引到对象数据库中。Funnel 还确保在底层数据源更新时,已索引数据保持最新。
对象函数¶
函数(Functions)使代码作者能够编写可在运营环境中快速执行的逻辑,例如旨在支持决策过程的仪表板和应用程序。
有关更多详细信息,请参见函数文档。
本体后端的演进¶
本节描述对象存储 V1 (Phonograph) 的旧版架构和对象存储 V2 的更新架构。
对象存储 V1 (Phonograph) 架构 [计划弃用]¶
:::callout{theme="warning" title="计划弃用"} 对象存储 V1 (Phonograph) 处于开发的计划弃用阶段,将于 2026 年 6 月 30 日后不可用。请将您的对象类型和链接类型迁移到对象存储 V2。有关更多信息,请参考升级助手中的"将对象类型和多对多链接类型从对象存储 v1 迁移到 v2"干预措施。 如果您对工作流中的 OSv1 到 OSv2 迁移有疑问,请联系 Palantir 支持。 :::
对象存储 V1 (Phonograph) 是 Foundry 的原始对象数据库,旨在索引和管理来自各种潜在数据模型的信息,同时在本体中的对象数据上维护 Foundry 的安全模型。除了索引和存储数据外,对象存储 V1 (Phonograph) 还跟踪用户生成编辑的应用、通过搜索和聚合处理复杂的用户查询,并编排数据写回。
以下是描述对象存储 V1 (Phonograph) 架构的图表。
对象存储 V2 架构¶
随着 Foundry 获得更多功能并不断发展以满足 Palantir 客户复杂的运营需求和不断增长的规模,对象存储 V2 从第一性原理构建,以实现下一代基于本体的用例和工作流。
具体来说,新架构分离了在对象存储 V1 (Phonograph) 中合并的关注维度,并在系统设计中解耦了职责;通过分离负责索引和查询数据的子系统,对象存储 V2 可以更轻松地水平扩展以满足未来需求。
对象存储 V2 支持的新功能和能力包括:
- 通过所有对象类型的增量对象索引(默认启用),显著提升本体数据索引性能。
- 单个对象类型的索引吞吐量提升至数百亿个对象。
- 更细粒度的对象权限,支持多数据源对象类型,包括列/属性级权限。
- 提升的用户编辑吞吐量,支持在单个操作中编辑多达 10,000 个对象。如需启用更高限制,请联系 Palantir 支持为您的注册创建变更请求。
- 降低的用户编辑延迟,更快地观察到用户编辑。
- 在对象类型发生破坏性模式变更后,能够迁移现有的用户编辑。
- 通过支持流式数据源,实现低延迟数据索引到本体。
- 每个对象类型最多支持 2000 个属性。
- 通过基于 Spark 的查询执行层,实现更高规模的搜索关联(Search Arounds)和更准确的聚合。
- 默认情况下,搜索关联限制为 100,000 个对象。如果您的用例需要超过 100,000 个对象的更高规模搜索关联,请联系 Palantir 支持以获取启用说明。
以下是描述对象存储 V2 如何驱动本体的架构图。