Time series syncs(时间序列同步)¶
Time series syncs hold time-value pairs associated with any number of time series (keyed by seriesIds), enabling performant indexing on each series and associated time-value pairs. Time series syncs are backed by datasets or streams and are the backing data sources for time series properties. You can also use time series for geospatial entity tracking when your data contains latitude and longitude measurements recorded at different timestamps.
:::callout{theme="neutral"} Review the geospatial and geotemporal documentation to learn more about when to use geotemporal series instead of time series. :::
When Foundry resolves a time series property on a given object time series property, the seriesId contained in the property’s value will be searched for within that property’s data sources and its associated time series data will be returned.
When you create a time series sync, there will be a projection created for the dataset that is being synced; projections are used to optimize the queries made when fetching your time series data.
Time series syncs require the following columns:
- seriesId: The identifier of a series (
string). - timestamp: The time the associated value occurred (
timestamporlong). - For long typed time columns, the units must be specified. Available units include seconds, milliseconds, microseconds or nanoseconds.
- value: The value of the series at a given timestamp (
double,integer,floatorstring). - Ingestion time: (optional): The time at which the streaming data points were ingested (
timestamp).
:::callout{theme="warning"}
If a time series property is backed by more than one time series sync, the seriesIds in the property values must be fully contained within a single time series sync.
:::
:::callout{theme="warning"} The size of the transforms profile required for the projection built when creating a time series sync scales with the size of the input dataset. For datasets larger than 10 TB, we recommend splitting your dataset up into multiple datasets, partitioned by series identifier, then creating syncs off of these smaller datasets. Alternatively, you can use a view optimization that can be configured in the advanced settings of your time series sync. :::
Create a time series sync¶
Create using Time Series Catalog¶
Navigate to the Time Series Catalog and select New time series sync. You will be prompted to choose a location to save your sync; this location must be in a Project that contains your time series dataset or imports your time series dataset as a reference. Select Set up sync to configure the time series sync.
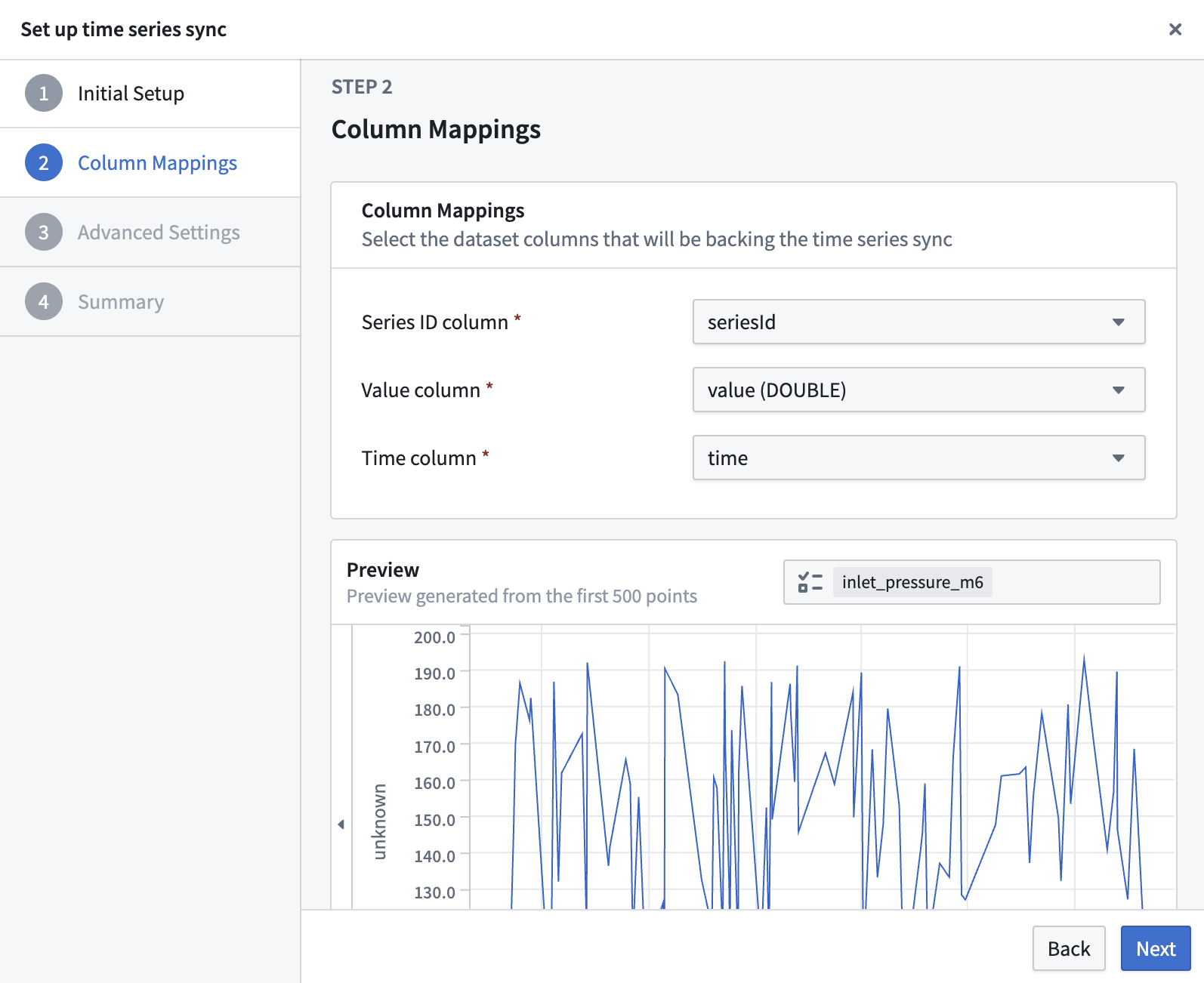
Select your time series dataset as the input, then complete the mapping of your dataset columns to the time series sync's Series ID, Value, and Timestamp. If your Timestamp column is a Long type, specify if it is a SECONDS, MILLISECONDS, MICROSECONDS, or NANOSECONDS unit. Use the preview to ensure time series data is appearing correctly.
You can optionally configure advanced settings. In most cases, the default values are recommended.
When you are finished, select Save and build in the final dialog step.
Create using Pipeline Builder¶
Pipeline Builder supports creating time series syncs. Review the Pipeline Builder documentation for guidance on adding data, creating transforms, and setting sync targets.
Navigate to Pipeline Builder and create a new pipeline.
-
Import your time series data and apply the necessary transforms so that your data has the necessary columns to be a time series sync.
-
Once your data has been transformed to contain the required columns, create a time series sync target.
- Next, configure the column mappings.
- Deploy the pipeline to create and build the time series sync. This will create both the backing dataset and the time series sync.
Manage a time series sync¶
Open a time series sync resource for advanced configuration and exploration. Explore all available time series syncs using the Time Series Catalog.
The Preview tab allows you to view the series identifier data that is contained with a sync. You can also view metadata about the resource, such as the time series properties of which it is a datasource. The Monitors tab displays various metrics for the checkpoint dataset of streaming time series syncs by default.
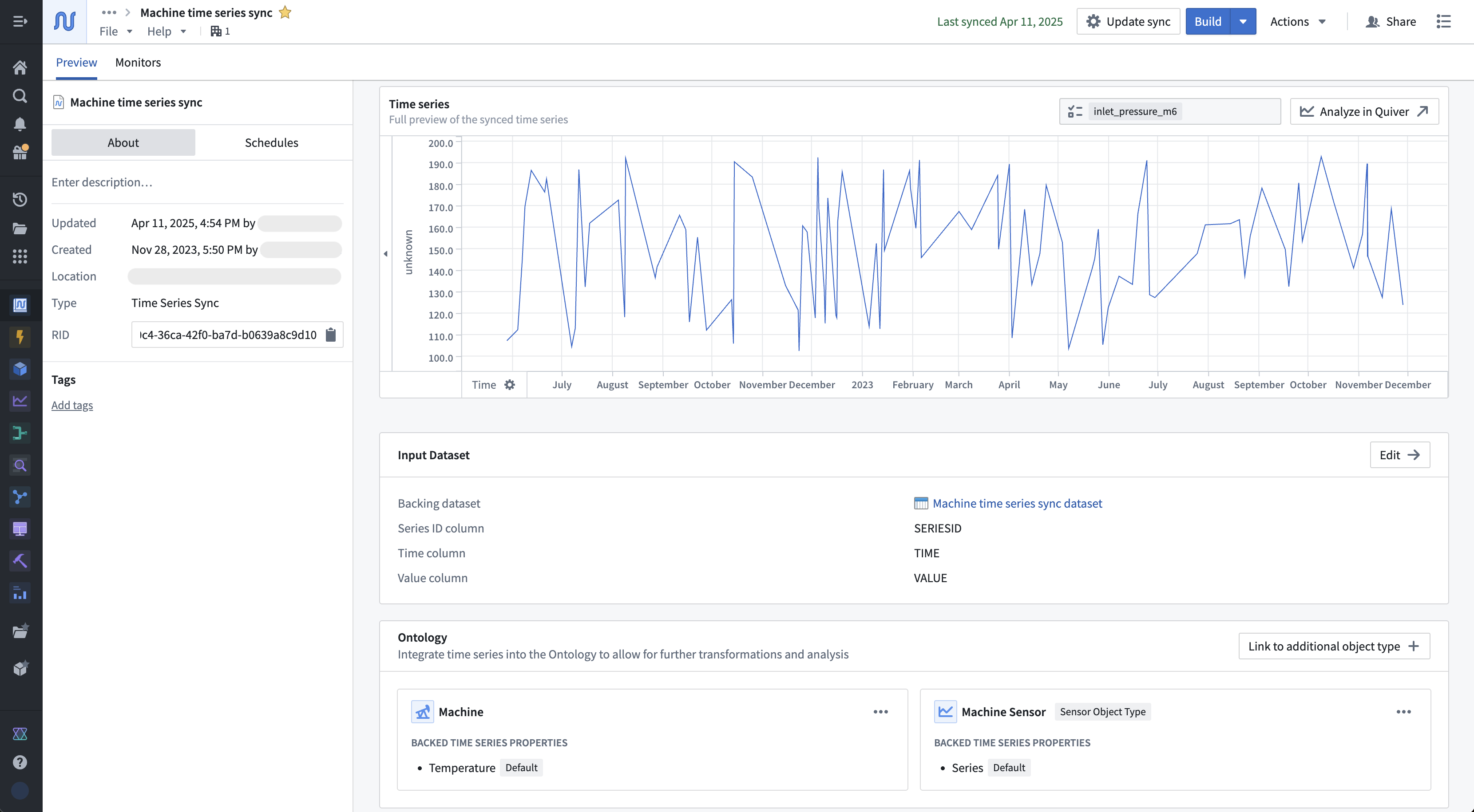
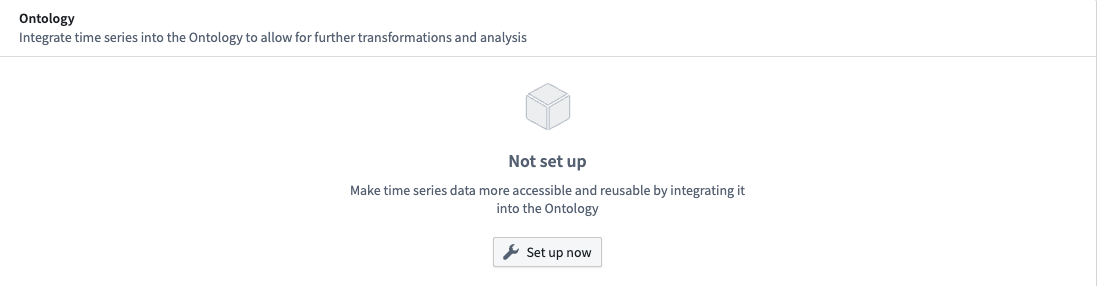
If the time series sync is not the datasource for any time series properties, then you have the option to follow the Ontology setup guide. Select Set up now in the Ontology section to initiate the setup guide. The setup guide will walk you through either choosing an existing object type or an automated flow creating a new object type to add a time series property to.
Select Update sync to configure the column mapping and advanced settings.
Time series sync advanced settings¶
This section describes the advanced settings that can be configured for time series syncs, and how these settings can be used for maintenance. You can find the advanced settings in the configuration options of your created sync, whether you set it up using Time Series Catalog or Pipeline Builder. You can access advanced settings during sync creation by proceeding to the third section of the wizard, or after sync creation by editing the sync.
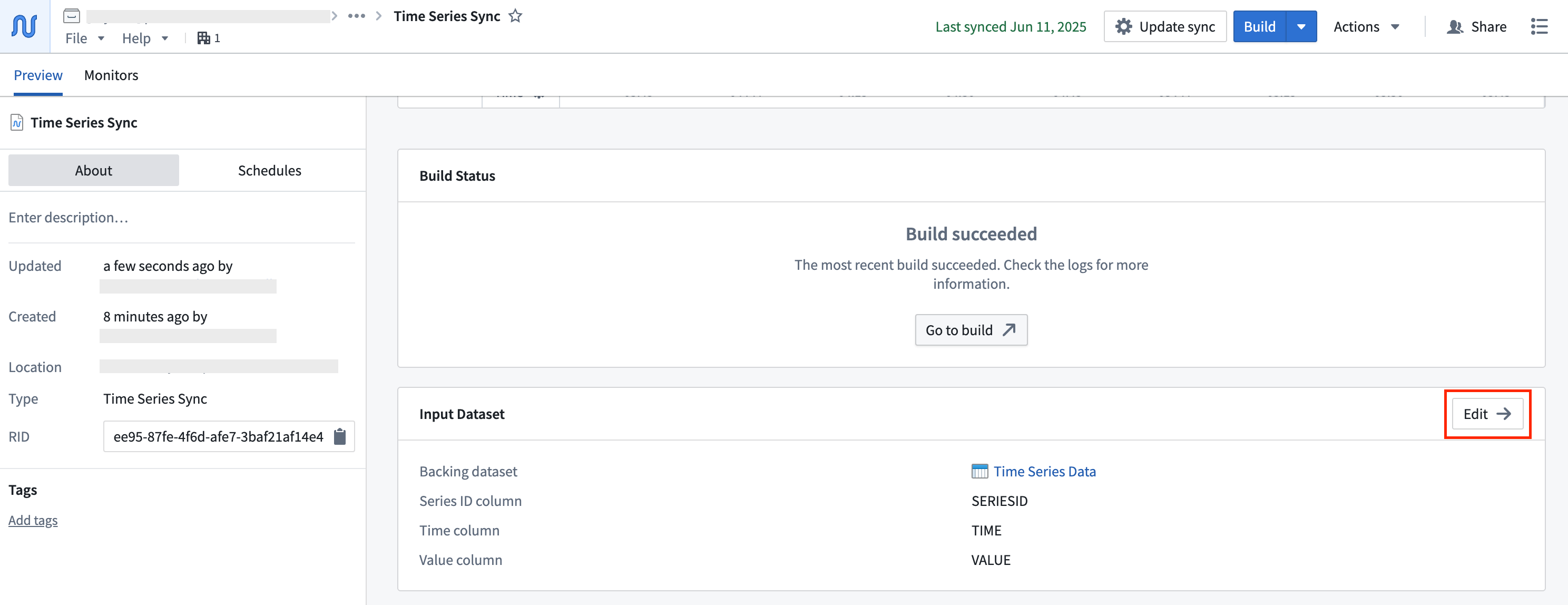
You will find the advanced settings as the third step in the pop-up wizard:
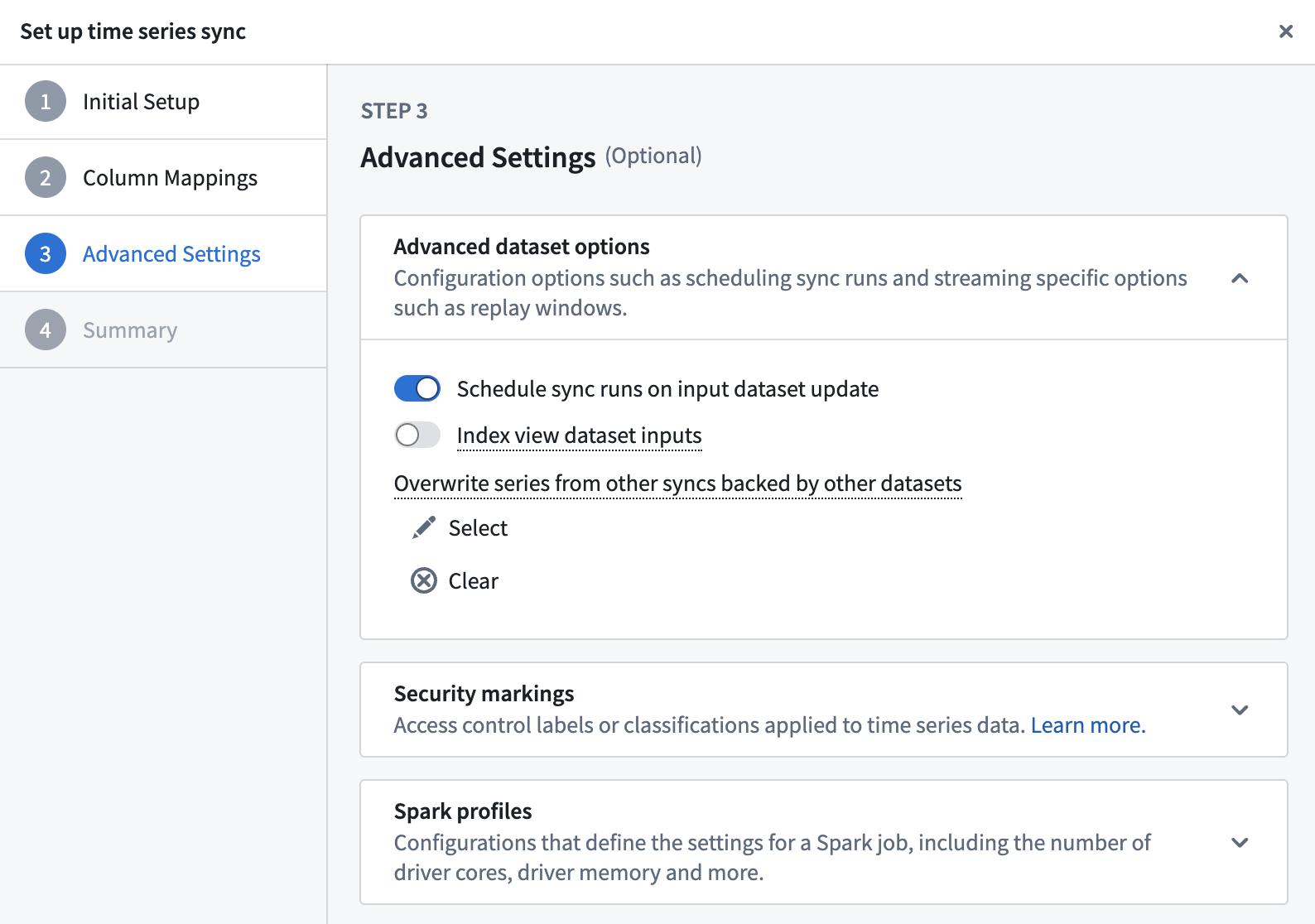
Advanced settings can be accessed during time series sync creation, and after creation by editing a time series sync. During sync creation, navigate to the Advanced settings section of the creation wizard. After creation, you can access the wizard by selecting the Edit option shown below when viewing the sync in Time Series Catalog.

Advanced dataset options¶
Schedule sync runs on input dataset update¶
By default, the sync will be scheduled to build when the input time series dataset updates. We recommend this setting to ensure your time series data is kept up-to-date.
Enable optimized sync builds¶
We highly recommend enabling this option if you will only use time series properties or qualified series IDs to access series in this sync, as this will speed up sync builds, use less disk space, and will not require the series IDs to be globally unique.
Index view dataset inputs¶
This option is recommended for syncs on views, unions of multiple datasets, that contain a large quantity of time series data (~10 TB+), but comprise few backing datasets (less than 10).
When selected, the resulting sync will index the view's backing datasets into the time series database, rather than the view itself. This will also transparently generate projections on the datasets that make up the view. As mentioned, this option is recommended for large canonical datasets. You can configure this in the advanced set up options of your time series sync.
In the context of time series, we recommend segmenting large canonical datasets into smaller datasets, and then using these smaller datasets as the constituents of a single view. With the Index view dataset inputs feature, this single view can be configured to a single sync, accounting for all backing datasets. The compromise is that accessing the timeseries data in this sync must account for all datasets in the view, potentially affecting query performance if the number of datasets is high (more than 10).
Overwrite series from other syncs backed by other datasets¶
If you wrote intersecting series IDs in another time series sync and would like to replace that sync with a new one, you can specify the old sync here. Doing this will cause the old sync to fail, and it should then be trashed. Time series syncs with stream inputs do not have this setting.
Security markings¶
Configure security markings. Markings that are inherited will be required when viewing the time series sync data through a time series property in the Ontology. See granular time series property permissions for more information.
Spark/Flink profiles¶
While it is possible to configure Spark or Flink compute profiles for time series sync builds, this is rarely necessary.
:::callout{theme="warning"} If the time series sync was created in Pipeline Builder, all of the fields that Pipeline Builder can configure will override any configuration set within the time series catalog application. For example, if changes were made to column mappings in the time series catalog application, but the time series sync was created in Pipeline Builder, the changes will be overridden the next time the creating pipeline is run. :::
中文翻译¶
时间序列同步¶
时间序列同步(Time series syncs)存储与任意数量时间序列(由 seriesIds 键控)关联的时间-值对,能够对每个序列及其关联的时间-值对进行高性能索引。时间序列同步由数据集或流支持,是时间序列属性(time series properties)的后端数据源。当您的数据包含在不同时间戳记录的经纬度测量值时,您还可以将时间序列用于地理空间实体追踪。
:::callout{theme="neutral"} 请查阅地理空间和地理时间文档,了解何时应使用地理时间序列(geotemporal series)而非时间序列。 :::
当 Foundry 解析给定对象时间序列属性时,系统将在该属性的数据源中搜索属性值中包含的 seriesId,并返回关联的时间序列数据。
创建时间序列同步时,将为被同步的数据集创建一个投影(projection);投影用于优化获取时间序列数据时的查询性能。
时间序列同步需要以下列:
- seriesId: 序列的标识符(
string类型)。 - timestamp: 关联值发生的时间(
timestamp或long类型)。 - 对于长整型时间列,必须指定时间单位。可用单位包括秒、毫秒、微秒或纳秒。
- value: 序列在给定时间戳的值(
double、integer、float或string类型)。 - Ingestion time(可选): 流式数据点被摄入的时间(
timestamp类型)。
:::callout{theme="warning"}
如果某个时间序列属性由多个时间序列同步支持,则属性值中的 seriesIds 必须完全包含在单个时间序列同步中。
:::
:::callout{theme="warning"} 创建时间序列同步时构建投影所需的转换配置文件(transforms profile)大小与输入数据集的大小成正比。对于超过 10 TB 的数据集,我们建议将数据集拆分为多个按序列标识符分区的小数据集,然后基于这些较小的数据集创建同步。或者,您也可以使用视图优化(view optimization),该功能可在时间序列同步的高级设置中进行配置。 :::
创建时间序列同步¶
使用时间序列目录创建¶
导航至时间序列目录(Time Series Catalog),选择 New time series sync。系统将提示您选择保存同步的位置;该位置必须位于包含您时间序列数据集或将其作为引用导入的项目(Project)中。选择 Set up sync 以配置时间序列同步。
选择您的时间序列数据集作为输入,然后完成数据集列到时间序列同步的 Series ID、Value 和 Timestamp 的映射。如果您的 Timestamp 列是 Long 类型,请指定其单位为 SECONDS、MILLISECONDS、MICROSECONDS 或 NANOSECONDS。使用预览功能确保时间序列数据显示正确。
您可以选择配置高级设置。在大多数情况下,建议使用默认值。
完成后,在最终对话框步骤中选择 Save and build。
使用 Pipeline Builder 创建¶
Pipeline Builder 支持创建时间序列同步。请查阅 Pipeline Builder 文档,了解如何添加数据、创建转换和设置同步目标。
导航至 Pipeline Builder 并创建新管道。
-
导入您的时间序列数据,并应用必要的转换,使您的数据具备成为时间序列同步所需的列。
-
数据转换完成后,创建时间序列同步目标(time series sync target)。
- 接下来,配置列映射。
- 部署管道以创建并构建时间序列同步。这将同时创建后端数据集和时间序列同步。
管理时间序列同步¶
打开时间序列同步资源以进行高级配置和探索。使用时间序列目录探索所有可用的时间序列同步。
Preview 选项卡允许您查看同步中包含的序列标识符数据。您还可以查看资源的元数据,例如作为其数据源的时间序列属性。Monitors 选项卡默认显示流式时间序列同步检查点数据集的各种指标。
如果时间序列同步不是任何时间序列属性的数据源,您可以选择遵循本体设置指南。在 Ontology 部分选择 Set up now 以启动设置指南。该指南将引导您选择现有对象类型或通过自动化流程创建新对象类型,以添加时间序列属性。
选择 Update sync 以配置列映射和高级设置。
时间序列同步高级设置¶
本节介绍可为时间序列同步配置的高级设置,以及如何使用这些设置进行维护。您可以在已创建同步的配置选项中找到高级设置,无论您是使用时间序列目录还是 Pipeline Builder 进行设置。您可以在同步创建过程中进入向导的第三部分访问高级设置,也可以在同步创建后通过编辑同步来访问。
您将在弹出向导的第三步中找到高级设置:
高级设置可在时间序列同步创建期间访问,也可在创建后通过编辑时间序列同步来访问。在同步创建期间,导航至创建向导的 Advanced settings 部分。创建后,您可以通过在时间序列目录中查看同步时选择下图所示的 Edit 选项来访问向导。
高级数据集选项¶
在输入数据集更新时调度同步运行¶
默认情况下,同步将在输入时间序列数据集更新时被调度构建。我们建议启用此设置,以确保您的时间序列数据保持最新。
启用优化的同步构建¶
如果您仅使用时间序列属性或限定序列 ID(qualified series IDs)来访问此同步中的序列,我们强烈建议启用此选项,因为这将加快同步构建速度,减少磁盘空间使用,并且不需要序列 ID 全局唯一。
索引视图数据集输入¶
此选项推荐用于包含大量时间序列数据(约 10 TB 以上)但仅由少量后端数据集(少于 10 个)组成的视图(views)(多个数据集的联合)上的同步。
选中后,生成的同步将把视图的后端数据集索引到时间序列数据库中,而不是索引视图本身。这还将透明地在构成视图的数据集上生成投影。如前所述,此选项推荐用于大型规范数据集(canonical datasets)。您可以在时间序列同步的高级设置选项中配置此功能。
在时间序列的上下文中,我们建议将大型规范数据集分割为较小的数据集,然后将这些较小的数据集用作单个视图的组成部分。借助 Index view dataset inputs 功能,可以将此单个视图配置为单个同步,涵盖所有后端数据集。其折衷在于,访问此同步中的时间序列数据时必须考虑视图中的所有数据集,如果数据集数量较多(超过 10 个),可能会影响查询性能。
覆盖来自其他数据集支持的其他同步的序列¶
如果您在另一个时间序列同步中写入了交叉的序列 ID,并希望用新的同步替换该同步,您可以在此处指定旧同步。这样做将导致旧同步失败,然后应将其丢弃。具有流输入的时间序列同步没有此设置。
安全标记¶
配置安全标记。通过本体中的时间序列属性查看时间序列同步数据时,需要继承的标记(Markings)。有关更多信息,请参阅细粒度时间序列属性权限。
Spark/Flink 配置文件¶
虽然可以为时间序列同步构建配置 Spark 或 Flink 计算配置文件,但这通常不是必需的。
:::callout{theme="warning"} 如果时间序列同步是在 Pipeline Builder 中创建的,则 Pipeline Builder 可配置的所有字段将覆盖在时间序列目录应用程序中设置的任何配置。例如,如果在时间序列目录应用程序中对列映射进行了更改,但时间序列同步是在 Pipeline Builder 中创建的,则下次运行创建管道时,这些更改将被覆盖。 :::