Core concepts(核心概念)¶
Traditional extraction¶
Traditional extraction configurations are based on algorithms not backed by large language models, such as PDF metadata extraction, Optical Character Recognition (OCR) detection, and layout detection. These configurations in AIP Document Intelligence are backed by the transform media item endpoint.
Learn more about using document extraction media transformations in AIP Document Intelligence.
Preprocessing¶
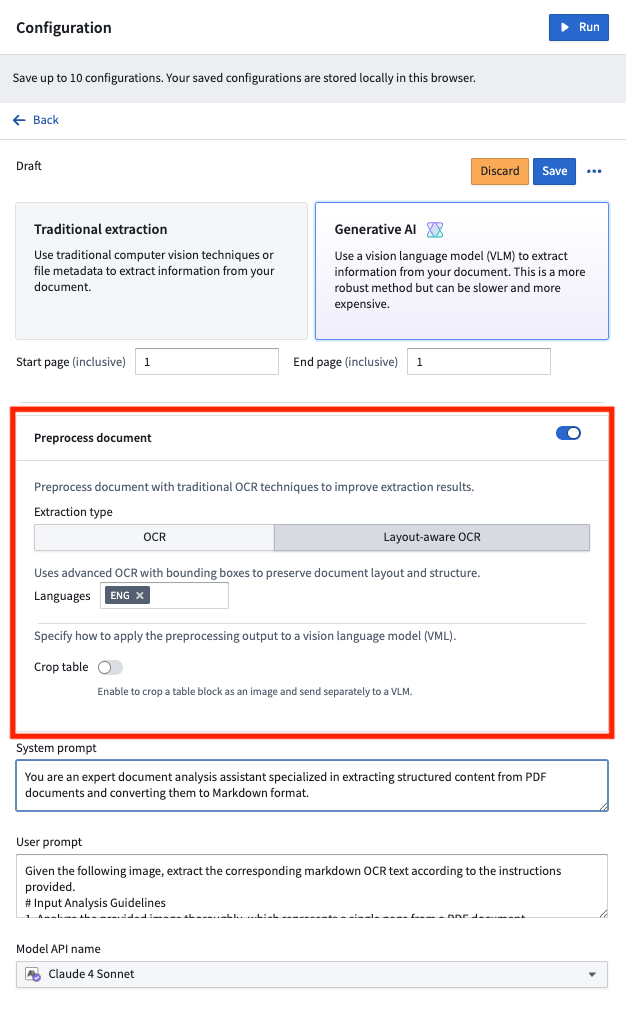
For use cases that work with more complex documents, combining VLMs with preprocessing techniques has proven quite successful. Under Configuration > Generative AI, toggle on Preprocess document. Document preprocessing essentially runs traditional OCR (Optical Character Recognition) on the document, then passes that output in addition to the document page itself to a VLM, giving the model more context to successfully analyze the document.
Evaluations¶
:::callout{theme="warning"} Currently, you can only perform extraction evaluations if Anthropic Claude 4 Sonnet is available for your enrollment. :::
For each run of an extraction strategy, you can choose to view a qualitative rubric that leverages your selected VLM as a judge. We fine-tuned the prompt to rank various area from 1 (worst) to 5 (best), including how well a given strategy extracted tables, headers, and more. Evaluations allow you to quickly iterate and make judgments as you test different prompts and strategies.
Deployment paths¶
Once you are satisfied with a particular strategy, you can deploy it in a batch pipeline to run it over your wider dataset. Currently, we only support a Python transform deployment path.
Python transform¶
You can export your strategy to a Python transform repository template that is fully dynamic; the dataset RID/path, model RID/path, custom prompt, and selected configuration are all automatically configured. We recommend you verify this work before triggering a build.
Learn more about the features of AIP Document Intelligence and how to get started.
中文翻译¶
核心概念¶
传统提取(Traditional extraction)¶
传统提取配置基于非大语言模型支持的算法,例如PDF元数据提取、光学字符识别(Optical Character Recognition,OCR)检测和版面检测。AIP Document Intelligence 中的这些配置由媒体项转换端点提供支持。
了解如何在 AIP Document Intelligence 中使用文档提取媒体转换。
预处理(Preprocessing)¶
对于处理更复杂文档的用例,将视觉语言模型(VLM)与预处理技术相结合已被证明非常成功。在 配置 > 生成式 AI 下,开启 预处理文档。文档预处理本质上是对文档运行传统 OCR(光学字符识别),然后将该输出连同文档页面本身一起传递给 VLM,从而为模型提供更多上下文以成功分析文档。
评估(Evaluations)¶
:::callout{theme="warning"} 目前,只有当您的组织已启用 Anthropic Claude 4 Sonnet 时,才能执行提取评估。 :::
对于每次提取策略的运行,您可以选择查看一个定性评估表,该表利用您选择的 VLM 作为评判标准。我们对提示词进行了微调,以对各个领域进行从 1(最差)到 5(最佳)的评分,包括特定策略提取表格、页眉等内容的效果。评估使您能够在测试不同提示词和策略时快速迭代并做出判断。
部署路径(Deployment paths)¶
当您对某个特定策略感到满意后,可以将其部署到批处理管道中,以便在更广泛的数据集上运行。目前,我们仅支持 Python 转换部署路径。
Python 转换(Python transform)¶
您可以将策略导出到一个完全动态的 Python 转换仓库模板中;数据集 RID/路径、模型 RID/路径、自定义提示词和所选配置都会自动配置。我们建议您在触发构建前验证此工作。