AIP Evals(AIP Evals(AIP 评估))¶
AIP Evals is a testing environment to evaluate the performance of your AIP Logic functions, AIP Chatbot functions, or code-authored functions. It is specifically designed to help you deal with the non-deterministic nature of LLMs. AIP Evals allows you to create test cases, define evaluation functions to measure performance, and compare the results against previous versions of your function. It enables you to build the necessary confidence to put LLM-backed functions into production or make changes to an existing implementation.
You can use AIP Evals to:
- Create test cases and define evaluation criteria.
- Debug, iterate, and improve functions and prompts.
- Compare the performance of different models on your functions.
- Examine variance across multiple runs.
AIP Evals is also available as an integrated tool within AI FDE, allowing you to create and run evaluation suites through conversational commands.
Core concepts¶
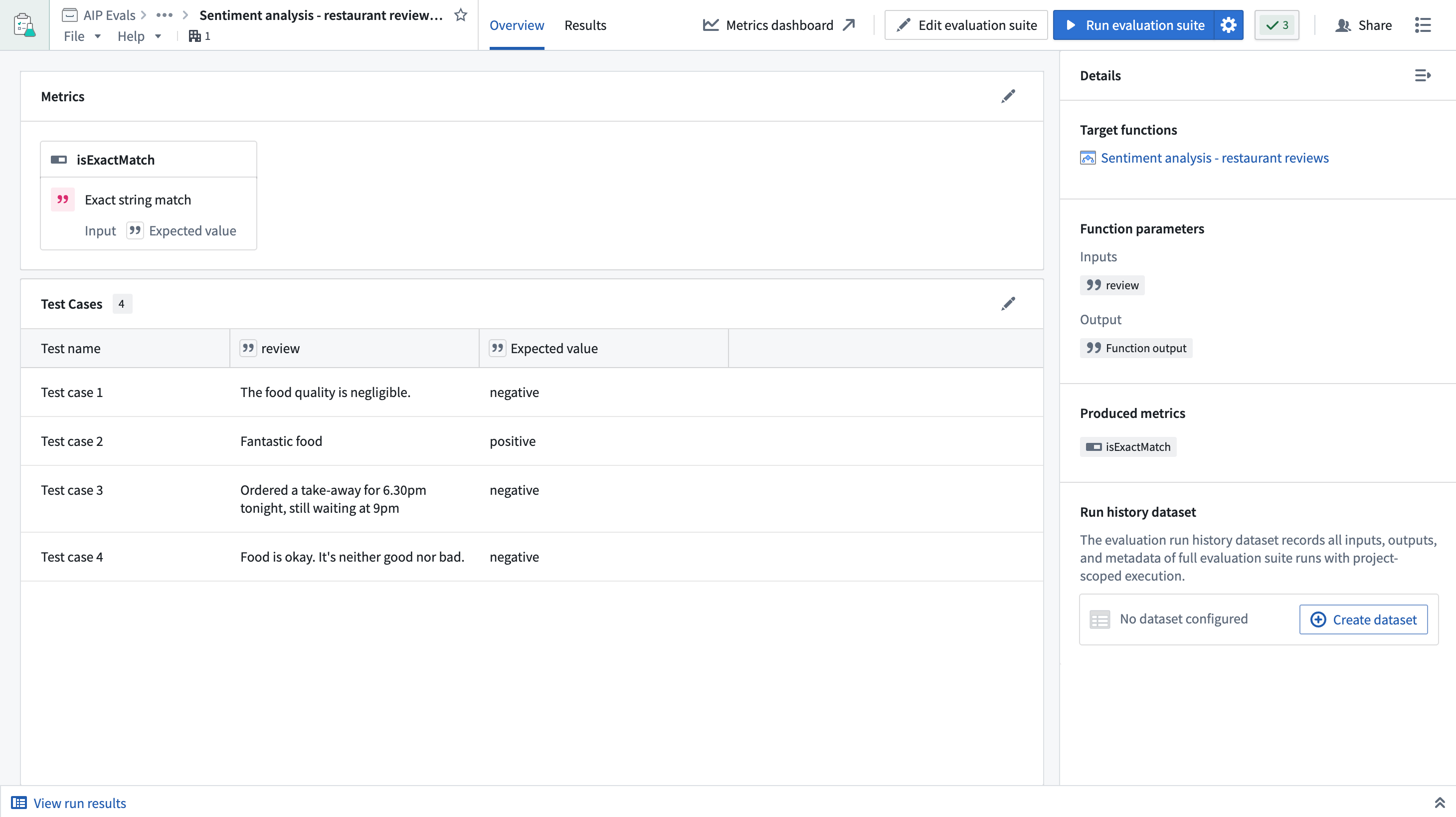
Evaluation suite: The collection of test cases, target functions, and evaluation functions used to benchmark function performance.
Target function: The function being evaluated. A suite can be configured to test multiple target functions simultaneously.
Evaluation function: The method used when comparing or evaluating the actual output of a target function against the expected output.
Test cases: Defined sets of inputs and expected outputs that are passed into evaluation functions during evaluation suite runs.
Metrics: The results of evaluation functions. Metrics are produced per test case and can be compared in aggregate or individually between runs.
To get started, create an evaluation suite for logic functions, or create an evaluation suite for general functions, and learn more about evaluation run configurations.
中文翻译¶
AIP Evals(AIP 评估)¶
AIP Evals 是一个测试环境,用于评估您的 AIP Logic 函数、AIP Chatbot 函数 或 代码编写的函数 的性能。它专门设计用于帮助您应对 LLM 的非确定性特性。AIP Evals 允许您创建测试用例、定义评估函数来衡量性能,并将结果与函数的先前版本进行比较。它使您能够建立必要的信心,将基于 LLM 的函数投入生产,或对现有实现进行更改。
您可以使用 AIP Evals 来:
- 创建测试用例并定义评估标准。
- 调试、迭代并改进函数和提示词。
- 比较不同模型在您的函数上的性能。
- 检查多次运行之间的差异。
AIP Evals 也可作为 AI FDE 中的集成工具使用,允许您通过对话式命令创建和运行评估套件。
核心概念¶
评估套件(Evaluation suite): 用于基准测试函数性能的测试用例、目标函数和评估函数的集合。
目标函数(Target function): 被评估的函数。一个套件可以配置为同时测试多个目标函数。
评估函数(Evaluation function): 用于比较或评估目标函数实际输出与预期输出的方法。
测试用例(Test cases): 定义的输入和预期输出集合,在评估套件运行期间传递给评估函数。
指标(Metrics): 评估函数的结果。指标按每个测试用例生成,可以在不同运行之间进行整体或单独比较。