Performance monitoring and optimization(性能监控与优化)¶
AIP observability provides comprehensive tools to monitor, analyze, and optimize the performance of your workflows and AIP applications. By leveraging trace data, execution metrics, and detailed logs, you can identify bottlenecks, optimize resource usage, and ensure your applications run efficiently at scale.
Why performance monitoring matters¶
Performance monitoring is crucial for:
- User experience: Slow workflows can frustrate users and reduce adoption.
- Cost efficiency: Optimized workflows use fewer resources and reduce compute costs.
- Reliability: Identifying performance issues early prevents outages and failures.
- Scalability: Understanding performance characteristics can help you plan for growth.
Identifying performance issues¶
You can use the trace view to identify slow operations.
- Long-running spans: Look for operations that take significantly longer than others.
- Sequential bottlenecks: Identify operations that could potentially run in parallel.
- Repeated operations: Find redundant calls that could be optimized.
- Model latency: Monitor LLM response times and consider using different models for time-sensitive operations.
In the screenshot below, you can see an example of AIP observability helping identify unbatched model calls that could be optimized.
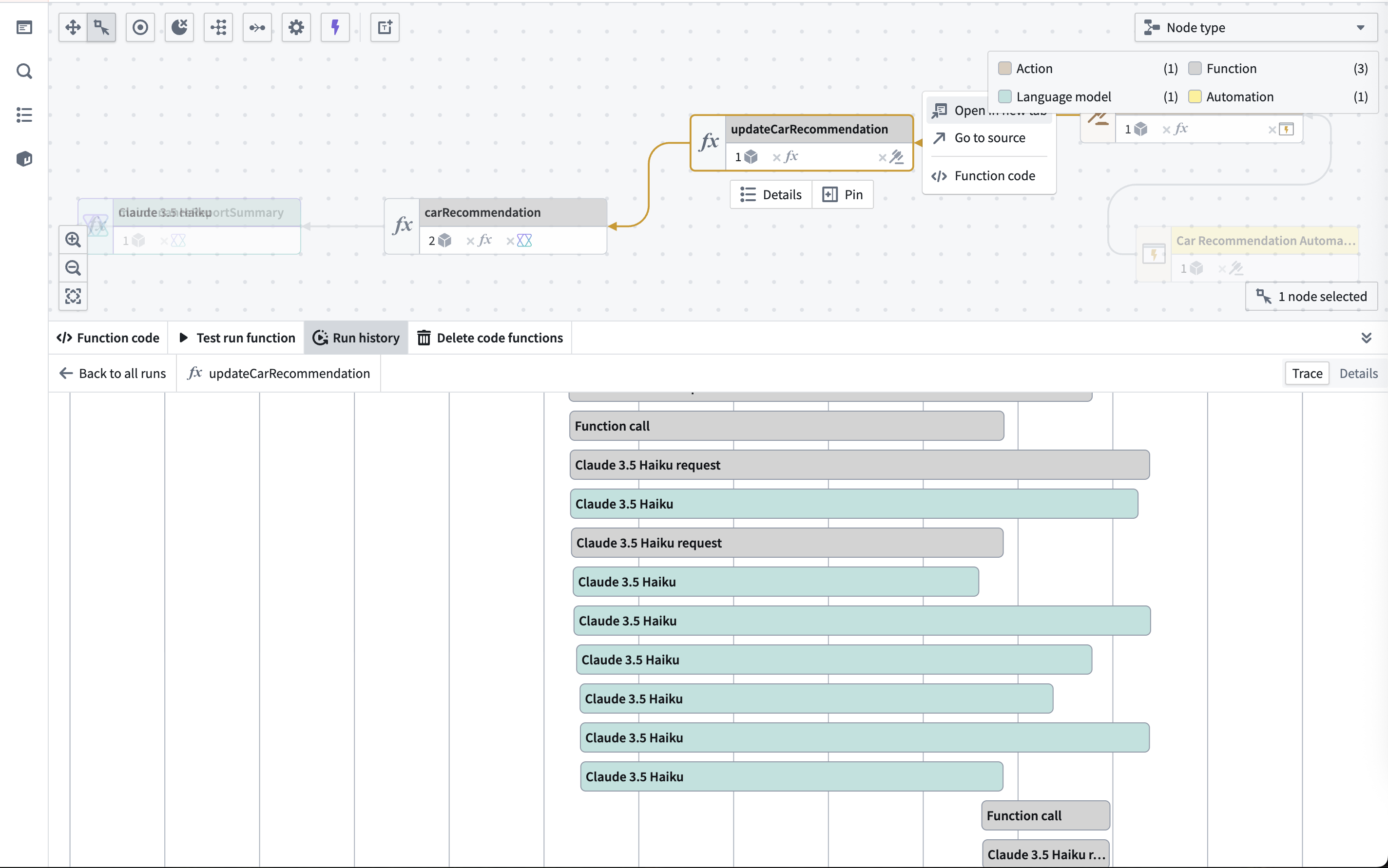
Optimization strategies¶
- Parallel execution: When possible, design workflows to execute independent operations concurrently.
- Model selection: Balance performance and quality by choosing appropriate models for each task.
- Batch operations: Group similar operations to reduce overhead.
- Error handling: Add proper error handling to prevent cascading failures.
中文翻译¶
性能监控与优化¶
AIP可观测性(AIP observability)提供了一套全面的工具,用于监控、分析和优化工作流及AIP应用程序的性能。通过利用追踪数据、执行指标和详细日志,您可以识别瓶颈、优化资源使用,并确保应用程序在规模化运行时保持高效。
为何性能监控至关重要¶
性能监控在以下方面具有关键作用:
- 用户体验: 缓慢的工作流会使用户受挫并降低采用率。
- 成本效益: 优化后的工作流消耗更少资源,降低计算成本。
- 可靠性: 及早发现性能问题可防止系统中断和故障。
- 可扩展性: 了解性能特征有助于您规划业务增长。
识别性能问题¶
您可以使用追踪视图(trace view)来识别运行缓慢的操作。
- 长耗时跨度(Long-running spans): 查找耗时显著长于其他操作的操作。
- 顺序瓶颈(Sequential bottlenecks): 识别可能并行运行的操作。
- 重复操作(Repeated operations): 发现可优化的冗余调用。
- 模型延迟(Model latency): 监控大语言模型(LLM)响应时间,并考虑对时间敏感型操作使用不同模型。
在下方截图中,您可以看到AIP可观测性如何帮助识别可优化的非批量模型调用(unbatched model calls)示例。
优化策略¶
- 并行执行: 在可能的情况下,将工作流设计为并发执行独立操作。
- 模型选择: 通过为每项任务选择合适的模型来平衡性能与质量。
- 批量操作: 将相似操作分组以减少开销。
- 错误处理: 添加适当的错误处理机制以防止级联故障。