Objectives(目标)¶
A modeling objective is a project for context, relevant data sources, metadata, and models all centralized around a specific operational problem. You can think of an objective as the definition for a modeling problem—the interface of the problem, for which the models submitted provide the implementation.
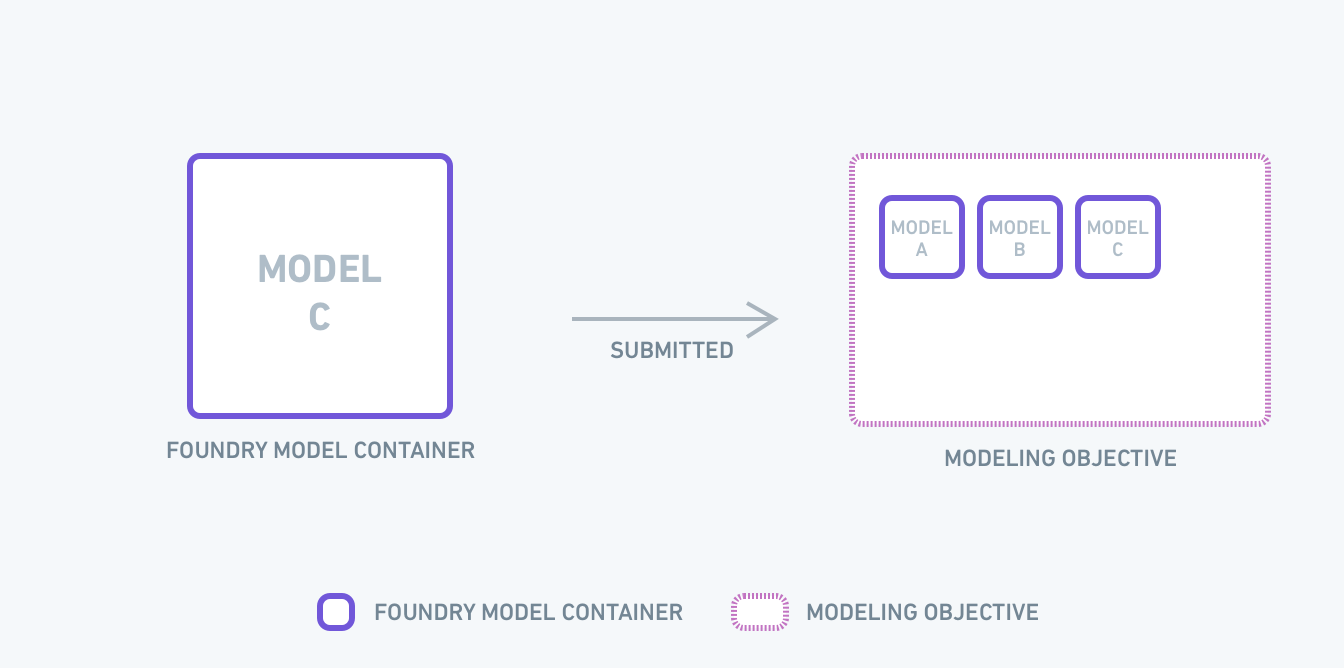
Modeling objectives serve as the communication hub for the modeling ecosystem and act as the system of record for evaluating, reviewing, and operationalizing successive model solutions over time.
Objectives are associated with metrics which define how models submitted to the objective should be evaluated against each other.
Submissions¶
When a model is submitted to a modeling objective to be managed and evaluated, a copy of that model version is created. This immutable submission is akin to a code Pull Request - when submitting a model, you are asking for a comprehensive review. A modeling objective is functionally a catalog of potential production-worthy model versions.
Releases¶
After models are submitted, they can be released. Releases are versioned, packaged, and production-ready assets containing model submission code. Releases can be thought of as accepted solutions to the modeling problem defined in the objective.
A Release includes configurable environment tags (such as "Staging" or "Production"), a user-defined version number, and a short descriptive field—a release note.
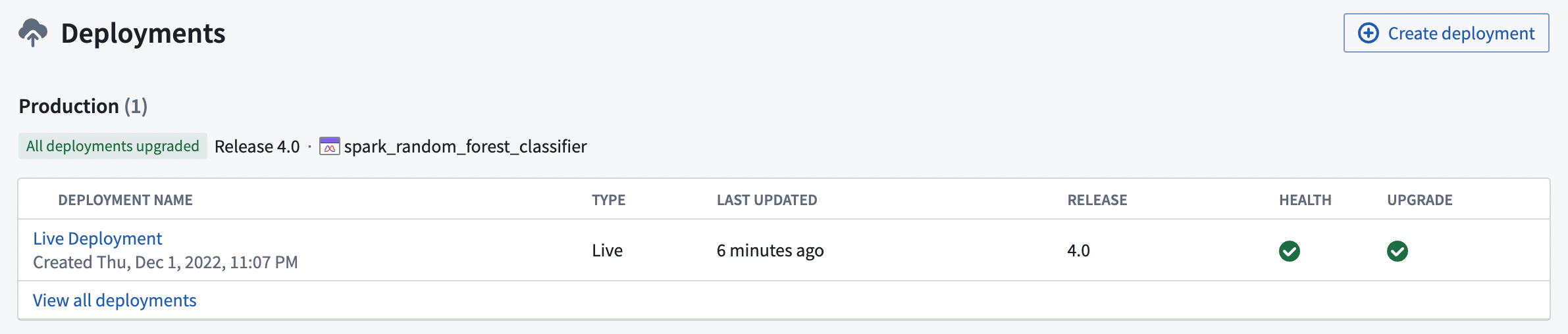
Released models power deployments, which are production inference pipelines or interactive endpoints. Deployments can be configured to pick up the latest tagged release. For example, a deployment with a "Production" environment will take the latest tagged "Production" release.
The release system provides a way to protect production deployments by requiring intentional upgrades via tagged and versioned releases, as well as an auditable model version history for production pipelines.
Deployments¶
Deployments enable delivery of selected and released models to consumers, including production pipelines, operational applications, and API subscribers.
Deployments provide a governed Continuous Integration & Continuous Delivery (CI/CD) layer for models in Foundry. As model submissions are reviewed and released, corresponding deployments pick up the new model versions automatically without downtime, while retaining lineage.
Types of Deployments¶
Batch deployments¶
Batch deployments run models within a pipeline by executing the model on a designated input Foundry dataset and publishing results into an output dataset. They leverage distributed compute and are suitable for production pipelines (for example, predicting housing price for all addresses in a county), as well as large-scale non-realtime processing (such as bulk computer vision or document analysis). Consumers can read from a consistent output dataset, even as the deployed model is switched.
Batch deployments are typically managed via build schedules, leveraging Foundry's internal build tools. Permissions propagate from the input dataset, model, Objective, and containing Project. Read about how to set up a batch deployment.
Live deployments¶
For low-latency or interactive settings, models can be served via Live deployments, which provide a serverless REST API endpoint that can be interactively queried.
Live endpoints can be independently permissioned, and executed with configured replication and resources. They are also highly available, meaning models can be updated via CI/CD without incurring endpoint downtime.
You can integrate Live deployments into operational applications by creating an interactive Live endpoint for your model or with Functions on models. You can also integrate models into scenario analyses and simulations.
Metrics¶
One of the most critical steps in modeling is understanding how well a model performs and under what conditions. Foundry enables you to generate and track metrics for models atop evaluation datasets, as well as logical subsets within that data. Metrics and their associated input datasets power the evaluation workflows within Modeling Objectives.
Metrics can be generated ad hoc (for example, at development time), or systematically as part of a modeling objective's automatic model evaluation. They are then visible within the model preview, and comparable with other models in the evaluation dashboard.
A MetricSet encapsulates the numerical metrics, images, and charts for a single model evaluation. MetricSets contain a reference to the corresponding model (and version), as well as the singular dataset and transaction (i.e. version) on which the metrics were computed. This dataset reference is called the "input dataset" of the MetricSet. See the range of options available for metric sets.

Metadata¶
An objective has associated, highly-configurable metadata that can be used to enable a broad range of management and collaboration workflows. Custom metadata fields can be collected with each model submission, which can aid with comparing models to one another.
中文翻译¶
目标¶
建模目标(modeling objective) 是一个围绕特定业务问题整合上下文、相关数据源、元数据和模型的项目。你可以将目标视为建模问题的定义——即问题的接口(interface),而提交的模型则提供实现(implementation)。
建模目标充当建模生态系统的沟通枢纽,并作为评估、审查和持续运营模型解决方案的记录系统。
目标与指标(metrics)相关联,这些指标定义了如何对提交至目标的模型进行相互评估。
提交¶
当模型被提交(submitted)至建模目标进行管理和评估时,会创建该模型版本的副本。这种不可变的提交类似于代码拉取请求(Pull Request)——提交模型时,你是在请求进行全面审查。建模目标本质上是一个潜在生产级模型版本的目录。
发布¶
模型提交后,可以进行发布(released)。发布是包含模型提交代码的版本化、打包且可投入生产的资产。可以将其视为目标中定义的建模问题的已接受解决方案。
一次发布包含可配置的环境标签(如"Staging"或"Production")、用户定义的版本号以及简短的描述字段——即发布说明。
已发布的模型为部署(deployments)提供支持,部署是生产推理管道或交互式端点。部署可配置为自动获取最新标记的发布。例如,带有"Production"环境的部署将获取最新标记的"Production"发布。
发布系统通过要求通过标记和版本化的发布进行有意的升级,以及为生产管道提供可审计的模型版本历史,从而保护生产部署。
部署¶
部署(Deployments) 能够将选定并发布的模型交付给消费者,包括生产管道、运营应用程序和API订阅者。
部署为Foundry中的模型提供了受控的持续集成与持续交付(CI/CD)层。随着模型提交被审查和发布,相应的部署会自动获取新模型版本,无需停机,同时保留血缘关系。
部署类型¶
批量部署¶
批量部署(Batch deployments) 通过在指定的输入Foundry数据集上执行模型,并将结果发布到输出数据集中,在管道内运行模型。它们利用分布式计算,适用于生产管道(例如,预测某个县所有地址的房价)以及大规模非实时处理(如批量计算机视觉或文档分析)。即使部署的模型发生切换,消费者也可以从一致的输出数据集中读取数据。
批量部署通常通过构建计划进行管理,利用Foundry的内部构建工具。权限从输入数据集、模型、目标和包含的项目传播。了解如何设置批量部署。
实时部署¶
对于低延迟或交互式场景,模型可以通过实时部署(Live deployments) 提供服务,它提供无服务器REST API端点,可进行交互式查询。
实时端点可以独立设置权限,并通过配置的复制和资源执行。它们还具有高可用性,这意味着模型可以通过CI/CD进行更新,而不会导致端点停机。
你可以通过为模型创建交互式实时端点或使用模型上的函数,将实时部署集成到运营应用程序中。你还可以将模型集成到场景分析和模拟中。
指标¶
建模中最关键的步骤之一是了解模型的表现如何以及在何种条件下表现良好。Foundry使你能够在评估数据集以及该数据中的逻辑子集上生成和跟踪模型的指标(metrics)。指标及其关联的输入数据集为建模目标中的评估工作流提供支持。
指标可以临时生成(例如,在开发时),或作为建模目标自动模型评估的一部分系统性地生成。然后,它们在模型预览中可见,并可在评估仪表板中与其他模型进行比较。
MetricSet 封装了单次模型评估的数值指标、图像和图表。MetricSet 包含对相应模型(及版本)的引用,以及计算指标所依据的单一数据集和事务(即版本)。该数据集引用称为 MetricSet 的"输入数据集"。查看指标集可用的选项范围。
元数据¶
目标具有高度可配置的关联元数据(metadata),可用于支持广泛的管理和协作工作流。每次模型提交时都可以收集自定义元数据字段,这有助于模型之间的相互比较。