Conclusion and next steps(结论与后续步骤)¶
In this tutorial, we created a supervised machine learning project in Foundry, in which we:
- Created a project for iterative model experimentation and development,
- Performed initial feature preparation and pipelining,
- Trained a production-ready model,
- Deployed our model to a live-hosted endpoint and a batch pipeline that automatically updates.
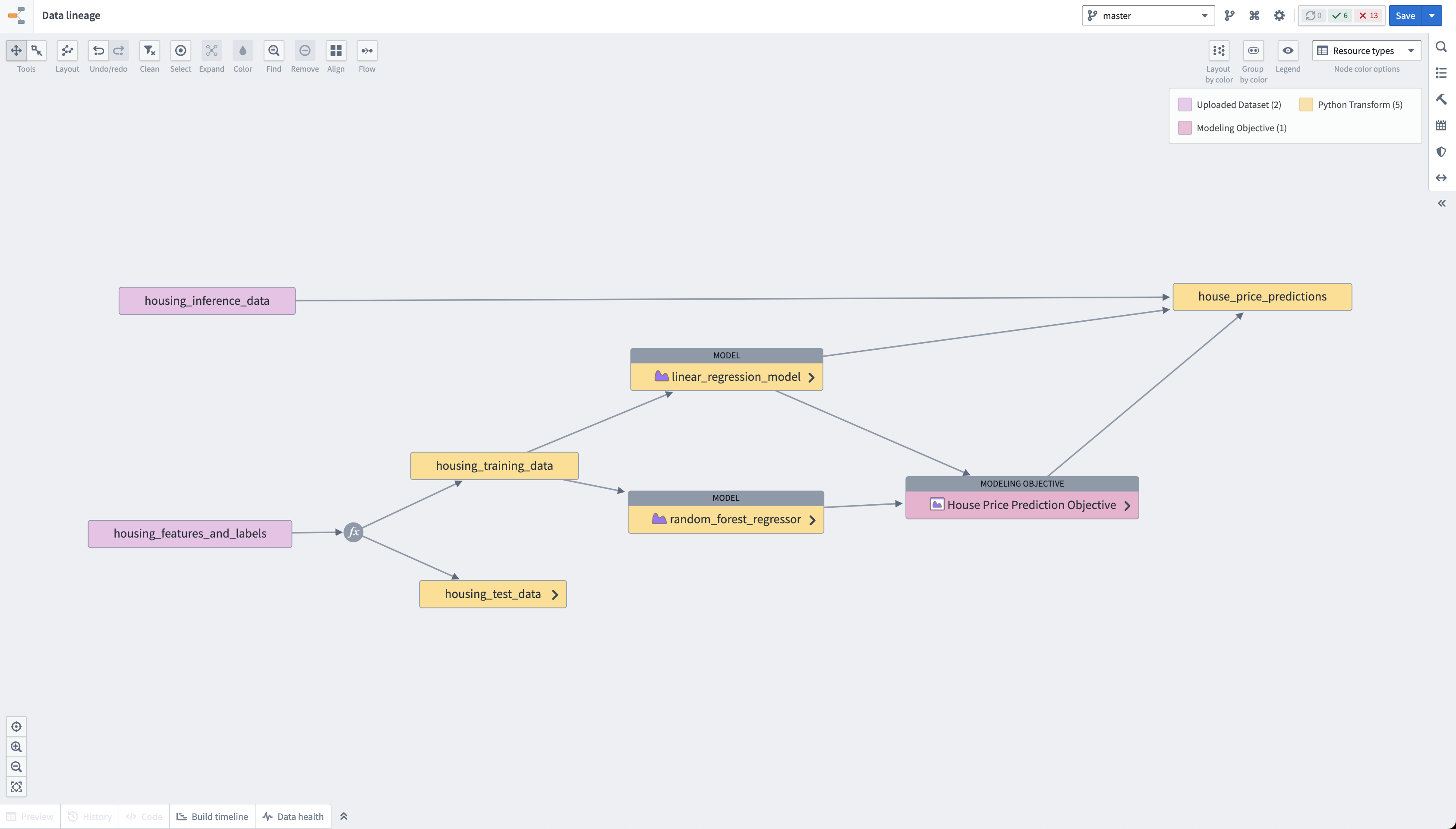
Foundry automatically tracks the lineage of all resources you produce in the platform. At the end of this tutorial, you will have a pipeline resembling the below screenshots.
Action: Navigate to your house_price_predictions dataset, select Explore pipelines > Explore data lineage.
Next steps¶
The next step is to convert this example workflow to a real workflow at your organization.
This typically includes:
- Integrate data from a range of data sources into Foundry to create a
features_and_labelsdataset that can be used for training and testing different models. - Try different model architectures, parameters, and features to get the best performance for your model.
- Integrate your model's predictions into the Foundry Ontology for use in operational applications either through a batch deployment, live deployment, or Python transforms.
- Create pre-release checks in your modeling objectives to ensure models are approved before release.
- Create "writeback" actions to capture user actions as a new dataset and use this data for continuous re-training and improvement of your model.
- Create a model inference history to improve and iterate on your model for more accurate performance and usage.
中文翻译¶
结论与后续步骤¶
在本教程中,我们在 Foundry 中创建了一个监督式机器学习项目,具体完成了以下操作:
- 创建了一个用于迭代模型实验与开发的项目,
- 执行了初始特征准备与流水线构建,
- 训练了一个可用于生产环境的模型,
- 将模型部署到实时托管端点(live-hosted endpoint)以及自动更新的批量流水线(batch pipeline)中。
Foundry 会自动追踪您在平台中生成的所有资源的血缘关系(lineage)。完成本教程后,您将获得一个类似于下方截图的流水线。
操作: 导航至您的 house_price_predictions 数据集,选择 探索流水线 > 探索数据血缘。
后续步骤¶
下一步是将此示例工作流转化为您所在组织的实际工作流。
通常包括以下内容:
- 将来自多种数据源的数据集成到 Foundry 中,创建一个可用于训练和测试不同模型的
features_and_labels数据集。 - 尝试不同的模型架构、参数和特征,以获得模型的最佳性能。
- 通过批量部署(batch deployment)、实时部署(live deployment)或 Python 转换(Python transforms),将模型的预测结果集成到 Foundry 本体(Ontology)中,用于运营应用。
- 在建模目标中创建预发布检查,确保模型在发布前获得批准。
- 创建"回写"操作,将用户操作捕获为新数据集,并利用这些数据持续重新训练和改进模型。
- 创建模型推理历史记录,以迭代优化模型,实现更准确的性能和使用效果。