Binary classification evaluator(二元分类评估器)¶
One of the default evaluation libraries in a modeling objective is the binary classification evaluator. This library provides a core set of commonly used metrics for evaluating binary classification models.
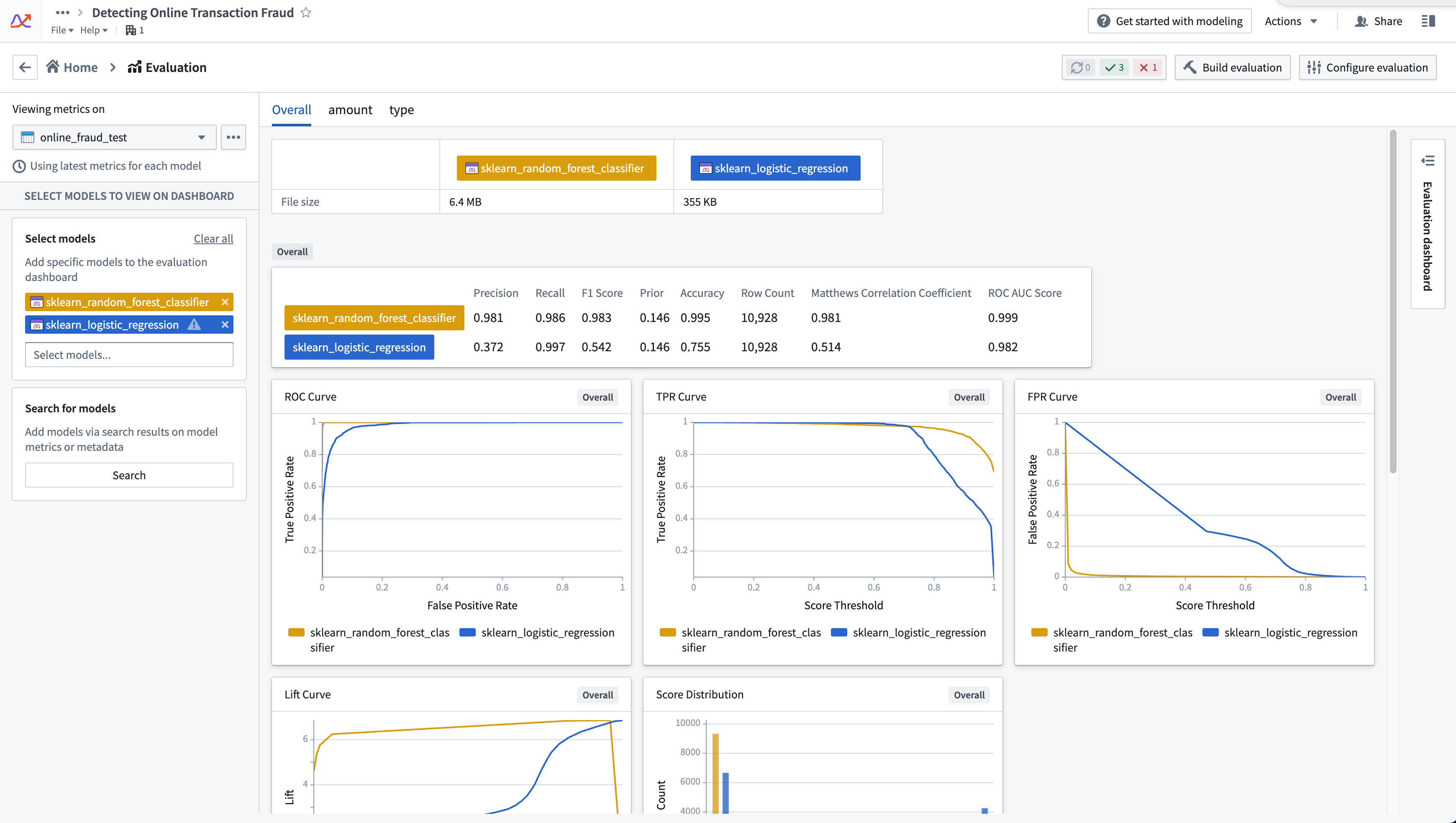
Included metrics¶
:::callout{theme="neutral"} The below metrics are produced for every subset bucket configured in the evaluation dashboard. It may not be possible to generate all metrics on every subset if, for example, the generated subset does not contain both classes in the model prediction or label columns. :::
The default binary classification evaluator produces the following numeric metrics:
- Row count: The number of records in the evaluation dataset.
- Prior: The proportion of positive results in the evaluation dataset. Note that the prior is not a direct measure of model performance but can be useful to contextualize other metrics.
- Accuracy: The proportion of records that were correctly categorized. A model's accuracy ranges between 0 and 1, where an accuracy of 1 represents a model that is correctly categorizing every record in the evaluation dataset.
- Precision: The number of true positives divided by the sum of the true positives and false positives. This will range between 0 and 1, where 1 is perfect model precision.
- Recall: The total number of true positives divided by the sum of the true positives and false negatives. This will range between 0 and 1, where 1 is perfect model recall. Also known as sensitivity.
- F1 score: The harmonic mean of the precision and recall, calculated as the product of precision and recall divided by the sum of precision and recall. A model's F1 score ranges between 0 and 1, where 1 represents a model that is correctly categorizing every record in the evaluation dataset.
- Matthews correlation coefficient (MCC): A numerical measure of model performance that combines the numeric correlation between the label and prediction values for each of the two classification classes equally. As a result, the MCC will only be high when the classifier is performing well on both classes. The MCC will range between -1 and 1, where a score of 1 is correctly categorizing every record.
- ROC AUC score (requires probability): The area under the ROC (receiver operating characteristic) curve; AUC stands for "Area Under Curve". Ranges from 0 to 1, where a score of 1 represents a perfect model and a score of 0.5 is the expected score for a model that is randomly guessing.
The default binary classification evaluator produces the following plots:
- Confusion matrix: Displays the number of true positive, true negative, false positive, and false negatives for predictions in the evaluation dataset.
- Score distribution: A bar chart of model predictions on the evaluation dataset.
- Probability distribution (requires probability): A bar chart of the model output probabilities on the evaluation dataset. The bucket width is
0.05, which results in 20 total buckets in the[0.0, 1.0]range. - ROC curve (requires probability): Plots the True Positive Rate against the False Positive Rate for different probabilities. A steeper curve generally indicates better model performance.
- True positive rate (TPR) curve (requires probability): The TPR curve plots the true positive rate against a model's prediction probability.
- False positive rate (FPR) curve (requires probability): The FPR curve plots the false positive rate against a model's prediction probability.
- Lift curve (requires probability): Shows the model's lift at each probability; lift is a measure of models performance on the positive class versus random chance.
Configuration¶
For full configuration instructions, see the documentation on how to configure a model evaluation library.
Required fields¶
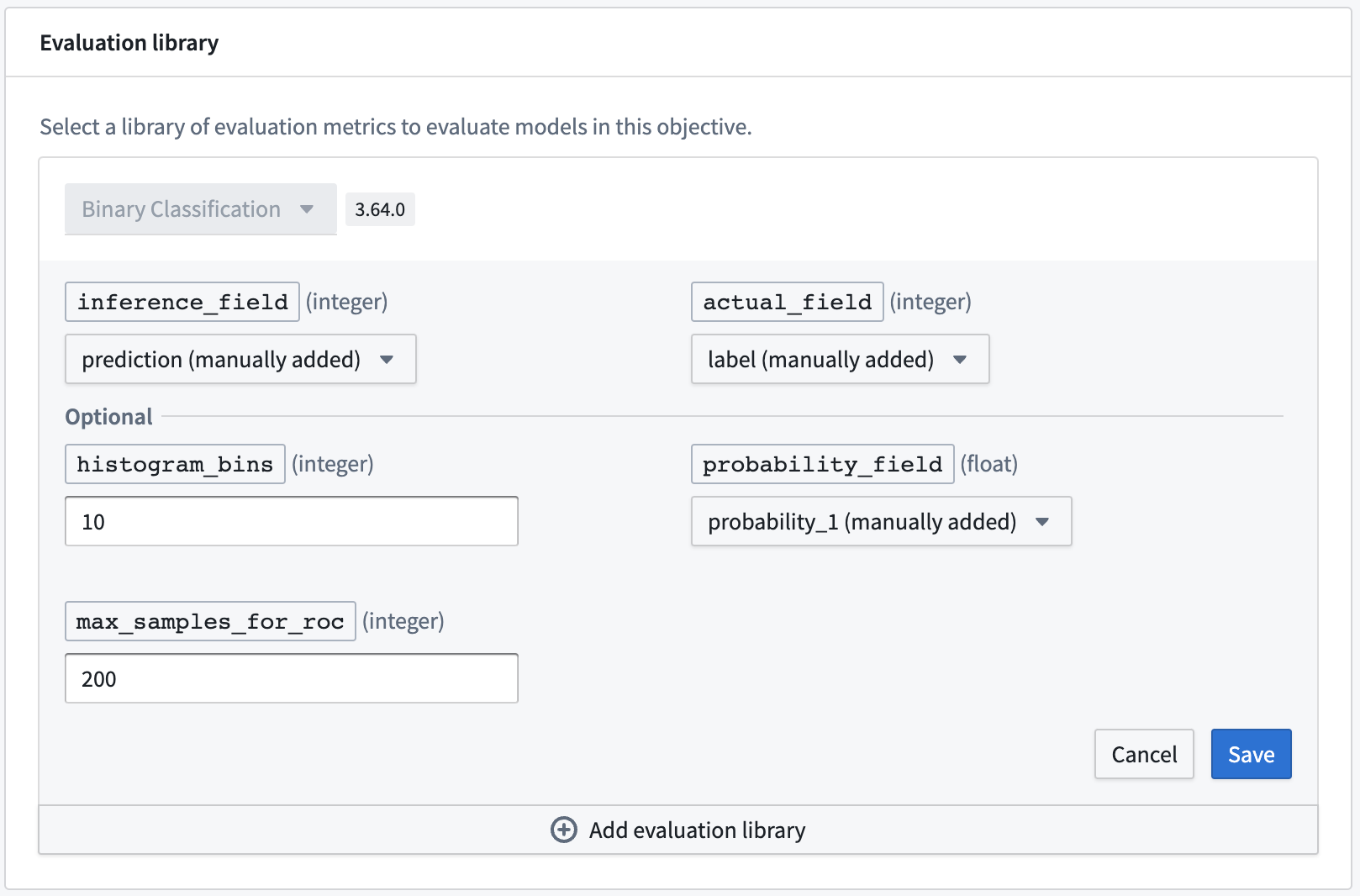
The following fields are required for a binary classification evaluator. The expected value type for these columns is integer.
- inference_field: Column that represents the prediction classification of the model. This evaluator assumes that a
1is the positive class and a0is the negative class. - actual_field: Column containing values to which a model's predictions should be compared. This evaluator assumes that a
1is the positive class and a0is the negative class.
Optional fields¶
- probability_field: This is an optional field that represents the probability of a positive prediction class. When the probability_field is provided, the default binary classification evaluation library will produce the following metrics:
- ROC AUC score
- ROC curve
- TPR curve
- FPR curve
-
Lift curve
-
max_samples_for_roc The maximum number of samples to generate the model ROC curve on. If not provided, this will default to
200.
中文翻译¶
二元分类评估器¶
建模目标中的默认评估库之一是二元分类(binary classification)评估器。该库提供了一组核心常用指标,用于评估二元分类模型。
包含的指标¶
:::callout{theme="neutral"} 以下指标会针对评估仪表盘中配置的每个子集桶生成。如果生成的子集未包含模型预测列或标签列中的两个类别,则可能无法在所有子集上生成全部指标。 :::
默认的二元分类评估器会生成以下数值指标:
- 行数(Row count): 评估数据集中的记录数量。
- 先验概率(Prior): 评估数据集中正例结果的比例。请注意,先验概率并非模型性能的直接度量,但有助于为其他指标提供背景参考。
- 准确率(Accuracy): 正确分类的记录比例。模型准确率取值范围为0到1,其中准确率为1表示模型正确分类了评估数据集中的每一条记录。
- 精确率(Precision): 真正例数量除以真正例与假正例之和。取值范围为0到1,其中1表示模型精确率完美。
- 召回率(Recall): 真正例总数除以真正例与假负例之和。取值范围为0到1,其中1表示模型召回率完美。也称为灵敏度(sensitivity)。
- F1分数(F1 score): 精确率与召回率的调和平均数,计算公式为精确率与召回率的乘积除以两者之和。模型F1分数取值范围为0到1,其中1表示模型正确分类了评估数据集中的每一条记录。
- 马修斯相关系数(MCC): 一种模型性能的数值度量,它同等结合了两个分类类别中标签值与预测值之间的数值相关性。因此,只有当分类器在两个类别上均表现良好时,MCC才会较高。MCC取值范围为-1到1,其中得分为1表示正确分类了每一条记录。
- ROC AUC分数(需概率值): ROC(受试者工作特征)曲线下的面积;AUC代表"曲线下面积"(Area Under Curve)。取值范围为0到1,其中得分为1表示完美模型,得分为0.5是随机猜测模型的预期分数。
默认的二元分类评估器会生成以下图表:
- 混淆矩阵(Confusion matrix): 显示评估数据集中预测结果的真正例、真负例、假正例和假负例数量。
- 分数分布(Score distribution): 模型在评估数据集上预测结果的条形图。
- 概率分布(Probability distribution)(需概率值): 模型在评估数据集上输出概率的条形图。桶宽为
0.05,因此在[0.0, 1.0]范围内共生成20个桶。 - ROC曲线(ROC curve)(需概率值): 绘制不同概率下真正例率与假正例率的关系曲线。曲线越陡峭通常表示模型性能越好。
- 真正例率曲线(TPR curve)(需概率值): TPR曲线绘制真正例率与模型预测概率的关系。
- 假正例率曲线(FPR curve)(需概率值): FPR曲线绘制假正例率与模型预测概率的关系。
- 提升曲线(Lift curve)(需概率值): 显示模型在每个概率下的提升度;提升度是衡量模型在正例类别上相对于随机猜测的性能指标。
配置¶
有关完整配置说明,请参阅如何配置模型评估库的文档。
必填字段¶
二元分类评估器需要以下字段。这些列预期的值类型为整数。
- inference_field: 表示模型预测分类的列。该评估器假设
1为正例类别,0为负例类别。 - actual_field: 包含用于与模型预测结果进行比较的值的列。该评估器假设
1为正例类别,0为负例类别。
可选字段¶
- probability_field: 这是一个可选字段,表示正例预测类别的概率。当提供了probability_field时,默认的二元分类评估库将生成以下指标:
- ROC AUC分数
- ROC曲线
- TPR曲线
- FPR曲线
-
提升曲线
-
max_samples_for_roc: 用于生成模型ROC曲线的最大样本数。如果未提供,默认值为
200。